回归树几乎所有参数,属性及接口都和分类树一模一样,但是回归树中没有标签分布是否均衡的问题
class sklearn.tree.DecisionTreeRegressor (criterion=’mse’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort=False)
1. 重要参数 criterion, 属性和接口
属性中最重要的依然是featureimportances,接口依然是apply, fit, predict, score最核心。
回归树衡量分枝质量的指标:
- mse”使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为特征选择的标准。
- MSE的本质是样本真实数据与回归结果的差异。在回归树中,MSE最常用的衡量回归树回归质量的指标(在分类树中这个指标是score代表的预测准确率)。
- MSE越小越好。
- 值得一提的是,虽然均方误差永远为正,但是sklearn当中使用均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。真正的
均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
回归树是怎么工作的
#回归处理的是连续性变量,决策树处理的是分类变量from sklearn.datasets import load_boston #用波士顿房价数据from sklearn.model_selection import cross_val_score #cross_val_score在model_selection模块中from sklearn.tree import DecisionTreeRegressorboston = load_boston()#第一步实例化regressor = DecisionTreeRegressor(random_state=0) #random_state设置随机参数#cross_val_score的参数5个:#regressor:1是模型评估器,不一定是回归,分类,SVM等,只要是实例化后的模型都可以#2,3是属性数据和标签:是完整的不需要划分训练集和测试集的数据#4cv=10,是将数据分为10分,每次取一份作为测试集,其余9分作为训练集,循环10次;默认是5;#scoring 是用neg_mean_squared_error(负的均方误差)作为衡量指标,评估模型;MSE越小,模型越好。cross_val_score(regressor, boston.data, boston.target, cv=10,scoring = "neg_mean_squared_error")
array([-18.08941176, -10.61843137, -16.31843137, -44.97803922,
-17.12509804, -49.71509804, -12.9986 , -88.4514 ,
-55.7914 , -25.0816 ]) #生成的就是-MSE,可以看到MSE越小代表模型越好。
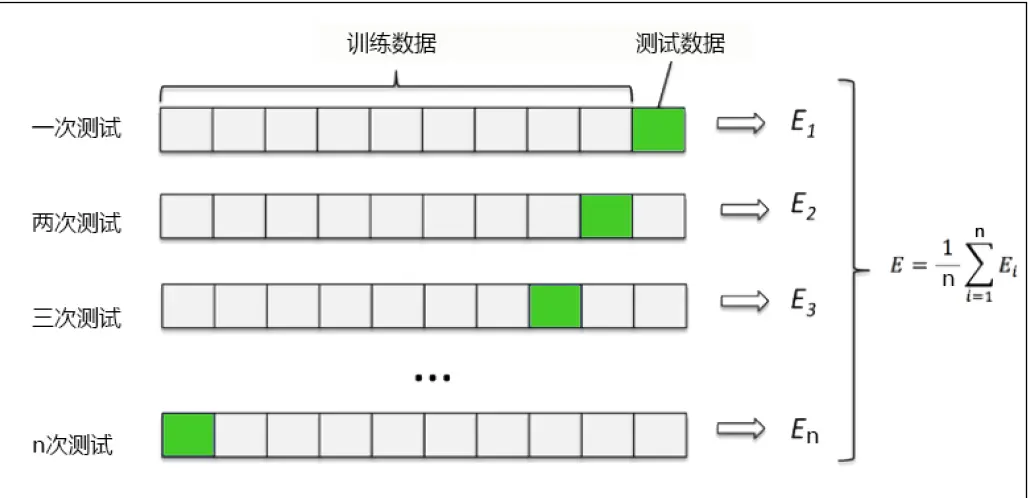
其中,交叉验证是cross_val_score,用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。
2. 一维回归图像,观察噪声对于回归树的影响
import numpy as npfrom sklearn.tree import DecisionTreeRegressorimport matplotlib.pyplot as plt
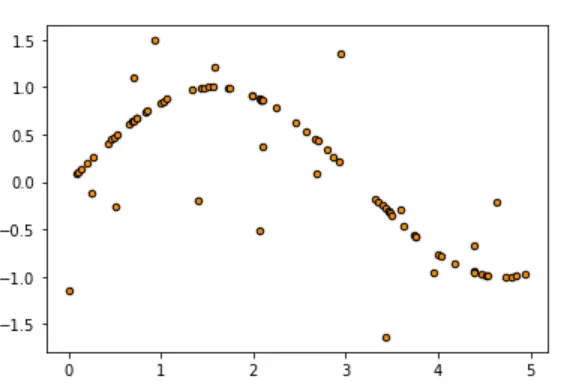
创建一条含有噪声的正弦曲线
rng = np.random.RandomState(1) #生成固定的随机数种子X = np.sort(5 * rng.rand(80,1), axis=0) #rand是随机生成0-1之间的数 (80,1)是数据的格式是80行,1列;通过np.sort对数据进行按照axis的行进行排序y = np.sin(X).ravel() #生成正弦曲线y[::5] += 3 * (0.5 - rng.rand(16)) # 加噪声 #这里就是y切片后的数据每一个加上一个随机的-1.5到1.5的数y.shape
下面是代码的理解
#了解降维函数ravel()的用法np.random.random((2,1))np.random.random((2,1)).ravel()np.random.random((2,1)).ravel().shape
(2,)
rng = np.random.RandomState(1) #生成固定的随机数种子rng.rand(8,1) #rand是随机生成0-1之间的数 生成8行一列的二维数据x = np.sort(5 * rng.rand(8,1), axis=0)x
array([[0.13693797],
[1.02226125],
[1.98383737],
[2.09597257],
[2.69408367],
[3.35233755],
[3.4260975 ],
[4.39058718]])
y = np.sin(x).ravel()y[::5] #对y进行切片,每5个取一个数字0.5 - rng.rand(16) #生成的数据就是-0.5到0.5之间
array([-0.19187711, 0.18448437, -0.18650093, -0.33462567, 0.48171172,
-0.25014431, -0.48886109, -0.24816565, 0.21955601, -0.28927933,
0.39677399, 0.05210647, -0.4085955 , 0.20638585, 0.21222466,
0.36997143])
绘制图像
plt.figure()plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data") #可以看到绘制出的图形有很多噪声
实例化和训练模型 做两个模型,最大深度小可以防止模型的过拟合
regr_1 = DecisionTreeRegressor(max_depth=2)regr_2 = DecisionTreeRegressor(max_depth=5)regr_1.fit(X, y)regr_2.fit(X, y)
测试集导入,预测结果
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] #这里就是生成一个二维的500行一列的数据y_1 = regr_1.predict(X_test) #predict返回每个测试样本的回归结果y_2 = regr_2.predict(X_test)
下面是对代码的解释
#np.arrange(开始点,结束点,步长) 生成有序的一维数组的函数np.arange(0.0, 5.0, 0.1)#了解增维切片np.newaxis的用法 其实就是和ravel()相反l = np.array([1,2,3,4])ll.shape #一维数据l[:,np.newaxis]l[:,np.newaxis].shape #升维后变成4行1列数据l[np.newaxis,:].shape #升维后变成1行4列数据

绘制图像
plt.figure() #打开一个画布plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data") # edgecolor边框,c是点颜色,s是点的大小,label是点的名字plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2) #plot是画折线图,label是线的名字plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)plt.xlabel("data") #横坐标plt.ylabel("target") #纵坐标plt.title("Decision Tree Regression")plt.legend() #显示图例plt.show() #展示图片
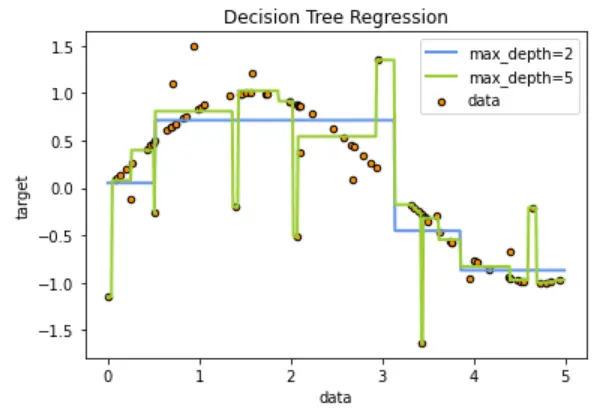
我们可以看到,如果树的最大深度(由max_depth参数控制)设置得太高,则决策树学习得太精细,它从训练数据中学了很多细节,包括噪声得呈现,从而使模型偏离真实的正弦曲线,形成过拟合。
参考菜菜老师的sklearn课程

若有收获,就点个赞吧
0 人点赞
