1. 集成算法
1.1 集成算法是通过在数据上构建多个模型,集成所有模型的建模结果,包括随机森林,梯度提升树(GBDT),Xgboost等。
1.2 多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
1.3 装袋法的核心思想是构建多个相互独立的评估器,装袋法的代表模型就是随机森林。
1.4 提升法的核心思想是结合弱评估器的力量一次次对难以评估的样本
进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
2. RandomForestClassifier 随机森林分类
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。
2.1 重要参数(n_estimators,random_state,boostrap和oob_score)
1. n_estimators
这是森林中树木的数量,即基评估器的数量。n_estimators越大,模型的效果往往越好。
一个随机森林和单个决策树效益的对比
1. 导入包
#1.导入包#代表画图的时候,需要这个环境%matplotlib inlinefrom sklearn.tree import DecisionTreeClassifier #决策树from sklearn.ensemble import RandomForestClassifier #集成学习中的随机森林
2. 导入数据集
#2 导入数据集wine = load_wine()wine.datawine.target
3. sklearn建模的基本流程
1.实例化
2.训练集带入实例化后的模型进行训练,使用的接口是fit
3.使用其它接口将测试集导入我们训练好的模型,去获取我们希望获取的结果(score,y_test)
from sklearn.model_selection import train_test_splitXtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)#复习:sklearn建模的基本流程clf = DecisionTreeClassifier(random_state=0)rfc = RandomForestClassifier(random_state=0)clf = clf.fit(Xtrain,Ytrain)rfc = rfc.fit(Xtrain,Ytrain)score_c = clf.score(Xtest,Ytest) #是精确度score_r = rfc.score(Xtest,Ytest)print('Single Tree:{}'.format(score_c),'Random Forest:{}'.format(score_r)) #format是将分数转换放在{}中
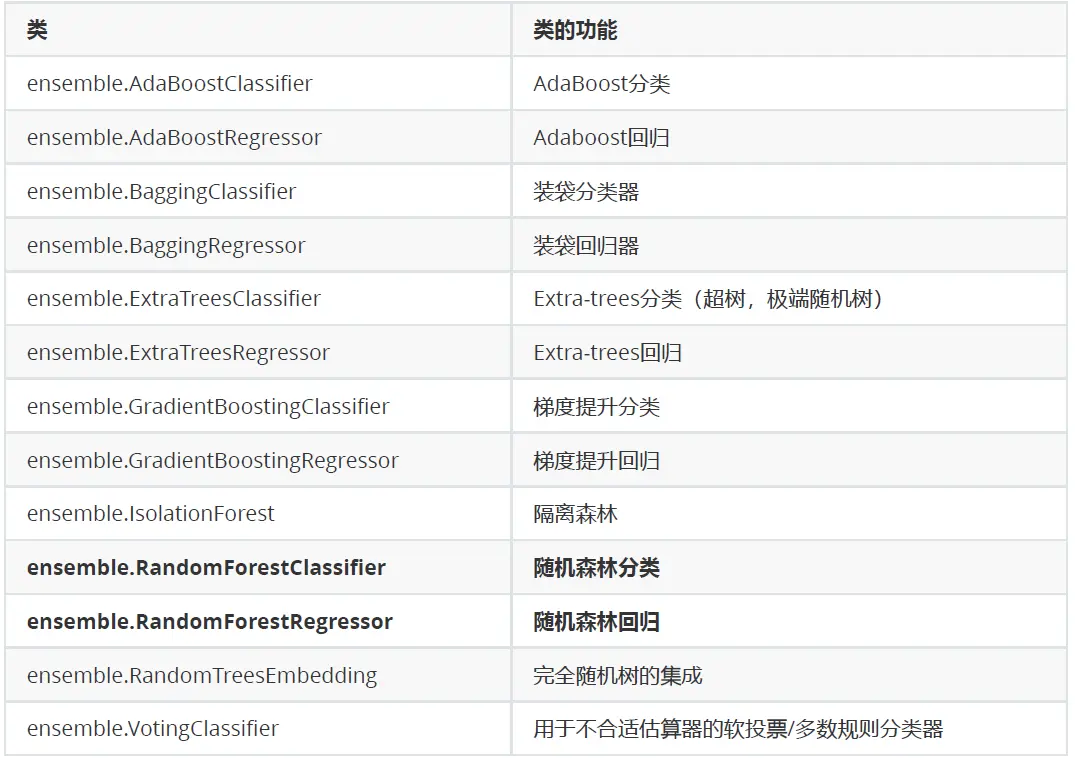
4. 画出随机森林和决策树在一组交叉验证下的效果对比
#4. 画出随机森林和决策树在一组交叉验证下的效果对比#交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法from sklearn.model_selection import cross_val_scoreimport matplotlib.pyplot as pltrfc = RandomForestClassifier(n_estimators=25)rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)clf = DecisionTreeClassifier()clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)plt.plot(range(1,11),rfc_s,label = "RandomForest")plt.plot(range(1,11),clf_s,label = "Decision Tree")plt.legend()plt.show()
#上述交叉验证更为简单的实现方式# for循环两种交叉验证,先计算RandomForest,再计算DecisionTreelabel = "RandomForest"for model in [RandomForestClassifier(n_estimators=25),DecisionTreeClassifier()]:score = cross_val_score(model,wine.data,wine.target,cv=10)print("{}:".format(label)),print(score.mean()) #这边打印的是计算10次得到的acuraccy的平均值plt.plot(range(1,11),score,label = label)plt.legend()label = "DecisionTree"
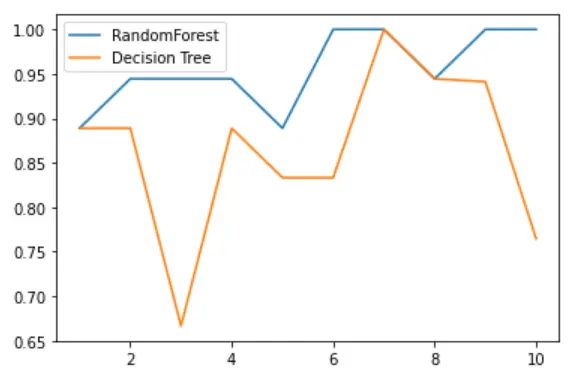
5. 画出随机森林和决策树在十组交叉验证下的效果对比
# 5. 画出随机森林和决策树在十组交叉验证下的效果对比rfc_l = []clf_l = []for i in range(10):rfc = RandomForestClassifier(n_estimators=25)rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()rfc_l.append(rfc_s)clf = DecisionTreeClassifier()clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()clf_l.append(clf_s)plt.plot(range(1,11),rfc_l,label = "Random Forest")plt.plot(range(1,11),clf_l,label = "Decision Tree")plt.legend()plt.show()
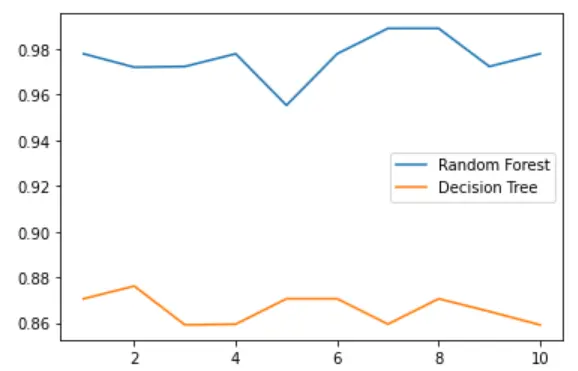
6. n_estimators的学习曲线
#6. n_estimators的学习曲线superpa = []for i in range(200):rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1) #这里就是进行了200次的随机森林计算,每次的n_estimator设置不一样rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()superpa.append(rfc_s)print(max(superpa),superpa.index(max(superpa)))plt.figure(figsize=[20,5])plt.plot(range(1,201),superpa)plt.show()# list.index(object) >>>返回对象object在列表list中的索引 68是i值,但是n_estimators=i+1,所以最大准确率对应的n_estimators是69.
2. random_state
在决策树中,一个random_state只控制生成一棵树,而随机森林中的random_state控制的是生成森林的模式。当random_state固定时,随机森林中生成是一组固定的树,但每棵树依然是不一致的。
rfc = RandomForestClassifier(n_estimators=25,random_state=2)rfc = rfc.fit(Xtrain,Ytrain)# #随机森林的重要属性之一:estimators,查看森林中树的状况rfc.estimators_[0].random_state #就是查看第0棵树的randomstate是多少#1872583848#通过循环将随机森林中所有决策树的random_state导出for i in range(len(rfc.estimators_)):print(rfc.estimators_[i].random_state)
3. bootstrap & oob_score
袋装法正是通过有放回的随机抽样技术来形成不同的训练数据,bootstrap就是用来控制抽样技术的参数。bootstrap参数默认True,代表采用这种有放回的随机抽样技术。
这种抽样方法会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据来测试我们的模型即可。oobscore来查看我们的在袋外数据上测试的结果。
#无需划分训练集和测试集,用袋外数据来测试模型rfc = RandomForestClassifier(n_estimators=25,oob_score=True) #oob_score默认是FALSE,bootstrap默认是TRUE.rfc = rfc.fit(wine.data,wine.target) #用所有的数据来训练#重要属性oob_score_rfc.oob_score_ #查看袋外数据在模型上的测试结果#0.9606741573033708
2.2 重要属性和接口
重要属性:.estimators .oob_score 和.featureimportances
接口:apply, fit, predict, score和predict_proba
rfc = RandomForestClassifier(n_estimators=25)rfc = rfc.fit(Xtrain, Ytrain) #fit接口是训练集用的rfc.score(Xtest,Ytest)rfc.feature_importances_ #得出所有特征的重要性数值rfc.apply(Xtest) #返回测试集每个样本在所在树的叶子节点的索引rfc.predict(Xtest) #返回对测试集的预测标签rfc.predict_proba(Xtest) #每一个样本分配到每一个标签的概率
参数是用来实例化确定模型有哪些限制条件的,属性是模型训练集的一些信息;fit接口是用于训练集的,剩下的接口基本都是用于测试集的。

若有收获,就点个赞吧
0 人点赞
