两表关联只返回一个表的数据就叫半连接。半连接一般就是指的 in 和 exists。在 SQL 优化实战中,半连接的优化是最为复杂的。
半连接等价改写
in 和 exists 一般情况下都可以进行等价改写。
半连接 in 的写法如下。
select * from dept where deptno in (select deptno from emp);
DEPTNO DNAME LOC---------- ---------- ---------------------------------------10 ACCOUNTING NEW YORK20 RESEARCH DALLAS30 SALES CHICAGO
执行计划如下: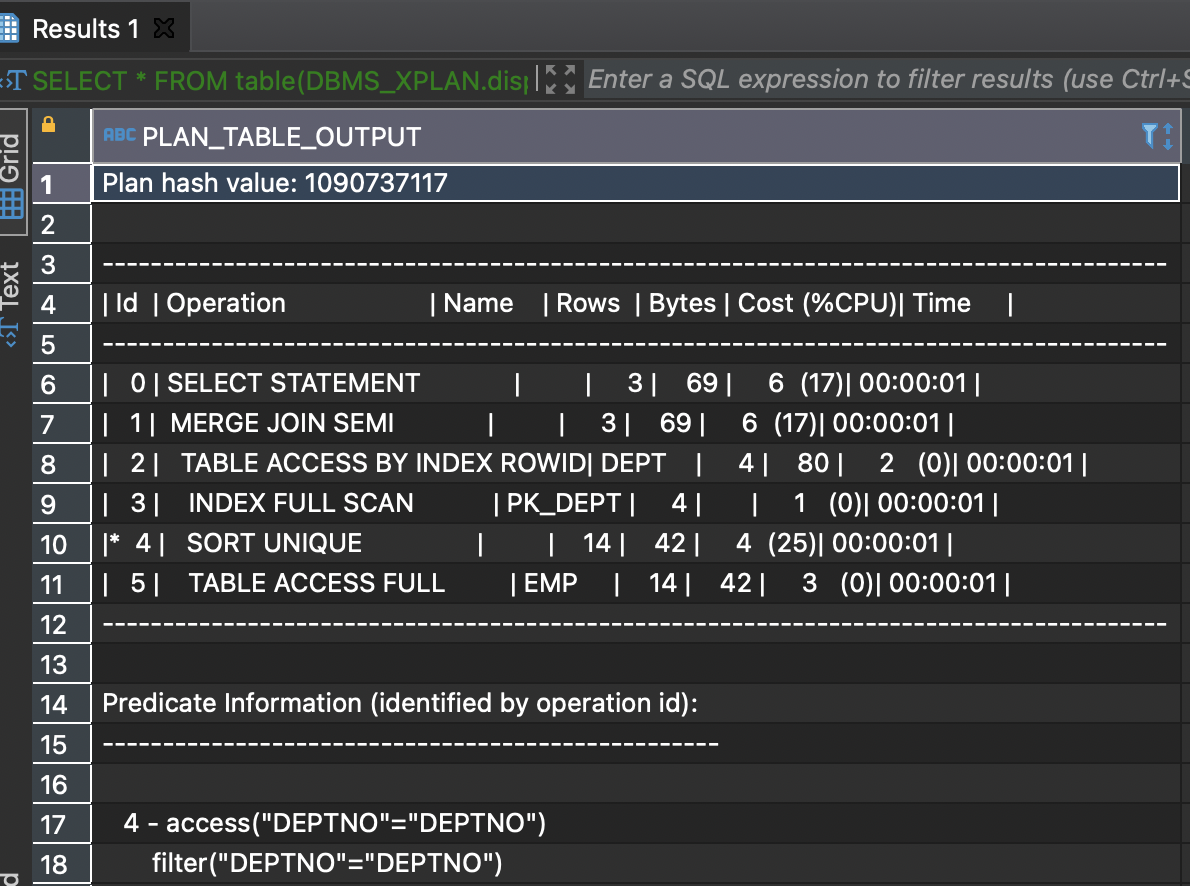
半连接 exists 的写法如下。
select * from dept where exists(select null from emp where dept.deptno=emp.deptno);
DEPTNO DNAME LOC---------- ---------- ---------------------------------------10 ACCOUNTING NEW YORK20 RESEARCH DALLAS30 SALES CHICAGO
in 和 exists 有时候也可以等价地改写为内连接,例如,上面查询语句可以改写为如下写法。
select d.*from dept d, (select deptno from emp group by deptno) ewhere d.deptno = e.deptno;
DEPTNO DNAME LOC---------- --------------- -----------------------------------10 ACCOUNTING NEW YORK20 RESEARCH DALLAS30 SALES CHICAGO
注意:上面内连接的写法性能没有半连接写法性能高,因为多了 GROUP BY 去重操作。
在将半连接改写为内连接的时候,我们要注意主表与子表(子查询中的表)的关系。这里 DEPT 与 EMP 是 1∶n 关系。在半连接的写法中,返回的是 DEPT 表的数据,也就是说返回的数据是属于 1 的关系。然而在使用内连接的写法中,由于 DEPT 与 EMP 是 1∶n 关系,两表关联之后会返回 n(有重复数据),所以我们需要加上 GROUP BY 去掉重复数据。
如果半连接中主表属于 1 的关系,子表(子查询中的表)属于 n 的关系,我们在改写为内连接的时候,需要加上 GROUP BY 去重。注意:这个时候半连接性能高于内连接。
如果半连接中主表属于 n 的关系,子表(子查询中的表)属于 1 的关系,我们在改写为内连接的时候,就不需要去重了。注意:这个时候半连接与内连接性能一样。
如果半连接中主表属于 n 的关系,子表(子查询中的表)也属于 n 的关系,这时我们可以先对子查询去重,将子表转换为 1 的关系,然后再关联,千万不能先关联再去重。
这里给一篇半连接被优化器改写为内连接而导致查询变慢的经典案例,如果大家有兴趣可以阅读参考:http://blog.csdn.net/robinson1988/article/details/51148332。
控制半连接执行计划
我们先来查看示例 SQL 的原始执行计划。
select * from dept where deptno in (select deptno from emp);
Execution Plan----------------------------------------------------------Plan hash value: 1090737117-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 69 | 6 (17)| 00:00:01 || 1 | MERGE JOIN SEMI | | 3 | 69 | 6 (17)| 00:00:01 || 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00:00:01 || 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00:00:01 ||* 4 | SORT UNIQUE | | 14 | 42 | 4 (25)| 00:00:01 || 5 | TABLE ACCESS FULL | EMP | 14 | 42 | 3 (0)| 00:00:01 |-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------4 - access("DEPTNO"="DEPTNO")filter("DEPTNO"="DEPTNO")
执行计划中 DEPT 与 EMP 是采用排序合并连接进行关联的。
我们现在让 DEPT 与 EMP 进行嵌套循环连接,同时让 DEPT 当驱动表。
select /*+ use_nl(emp@a,dept) leading(dept) */*from deptwhere deptno in (select /*+ qb_name(a) */ deptno from emp);
Execution Plan----------------------------------------------------------Plan hash value: 2645846736---------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 69 | 8 (0)| 00:00:01 || 1 | NESTED LOOPS SEMI | | 3 | 69 | 8 (0)| 00:00:01 || 2 | TABLE ACCESS FULL| DEPT | 4 | 80 | 3 (0)| 00:00:01 ||* 3 | TABLE ACCESS FULL| EMP | 9 | 27 | 1 (0)| 00:00:01 |---------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------3 - filter("DEPTNO"="DEPTNO")
有读者可能会好奇,为何不写 HINT /+ use_nl(dept,emp) leading(dept) /?
因为在 Oracle 数据库中,每个子查询都会自动生成一个查询块(query block),子查询里面的表会自动地被优化器取别名。这里 from 后面的表只有 DEPT,而 EMP 在子查询中,HINT 写成 use_nl(dept,emp)会导致 CBO 无法识别 EMP,为了让 CBO 能识别到 EMP,在子查询中添加了 qb_name 这个 HINT,给子查询取别名为 a,再在主查询中使用 use_nl(emp@a,dept),就能使两表进行嵌套循环关联。
如果不想使用 qb_name 这个 HINT,我们也可以参考如下操作。
explain plan for select * from dept where deptno in (select deptno from emp);
Explained.
select * from table(dbms_xplan.display(null, null, 'advanced -projection -outline -predicate'));
PLAN_TABLE_OUTPUT-------------------------------------------------------------------------------------Plan hash value: 1090737117-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 69 | 6 (17)|00:00:01|| 1 | MERGE JOIN SEMI | | 3 | 69 | 6 (17)|00:00:01|| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)|00:00:01|| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)|00:00:01|| 4 | SORT UNIQUE | | 14 | 42 | 4 (25)|00:00:01|| 5 | TABLE ACCESS FULL | EMP | 14 | 42 | 3 (0)|00:00:01|-------------------------------------------------------------------------------------Query Block Name / Object Alias (identified by operation id):-------------------------------------------------------------1 - SEL$5DA710D32 - SEL$5DA710D3 / DEPT@SEL$13 - SEL$5DA710D3 / DEPT@SEL$15 - SEL$5DA710D3 / EMP@SEL$220 rows selected.
select /*+ use_nl(dept,emp@sel$2) leading(dept) */*from deptwhere deptno in (select deptno from emp);
Execution Plan----------------------------------------------------------Plan hash value: 2645846736---------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 69 | 8 (0)| 00:00:01 || 1 | NESTED LOOPS SEMI | | 3 | 69 | 8 (0)| 00:00:01 || 2 | TABLE ACCESS FULL| DEPT | 4 | 80 | 3 (0)| 00:00:01 ||* 3 | TABLE ACCESS FULL| EMP | 9 | 27 | 1 (0)| 00:00:01 |---------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------3 - filter("DEPTNO"="DEPTNO")
现在我们让 DEPT 与 EMP 进行 HASH 连接,同时让 EMP 作为驱动表。
select /*+ use_hash(dept,emp@sel$2) leading(emp@sel$2) */*from deptwhere deptno in (select deptno from emp);
Execution Plan----------------------------------------------------------Plan hash value: 300394613----------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 69 | 8 (25)| 00:00:01 ||* 1 | HASH JOIN | | 3 | 69 | 8 (25)| 00:00:01 || 2 | SORT UNIQUE | | 14 | 42 | 3 (0)| 00:00:01 || 3 | TABLE ACCESS FULL| EMP | 14 | 42 | 3 (0)| 00:00:01 || 4 | TABLE ACCESS FULL | DEPT | 4 | 80 | 3 (0)| 00:00:01 |----------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access("DEPTNO"="DEPTNO")
让 EMP 表作为驱动表之后,CBO 先对 EMP 进行了去重(SORT UNIQUE)操作,这里 CBO 其实对该 SQL 进行了等价改写,将半连接等价改写为内连接(因为执行计划中没有 SEMI 关键字),在改写的过程中,因为 EMP 属于 N 的关系,所以对 EMP 进行了去重。
读者思考
现有如下 SQL。
select * from a where a.id in (select id from b);
假设 a 有 1000 万,b 有 100 行,请问如何优化该 SQL?
假设 a 有 100 行,b 有 1000 万,请问如何优化该 SQL?
假设 a 有 100 万,b 有 1000 万,请问如何优化该 SQL?

若有收获,就点个赞吧
0 人点赞
