经典哈希连接实现
连接(join)是数据库表之间的常用操作,通过把多个表之间某列相等的元组提取出来组成新的表。两个表若是元组数目过多,逐个遍历开销就很大,哈希连接就是一种提高连接效率的方法。
哈希连接主要分为两个阶段:建立阶段(build phase)和探测阶段(probe phase)
Bulid Phase
选择一个表(一般情况下是较小的那个表,以减少建立哈希表的时间和空间),对其中每个元组上的连接属性(join attribute)采用哈希函数得到哈希值,从而建立一个哈希表。
Probe Phase
对另一个表,扫描它的每一行并计算连接属性的哈希值,与bulid phase建立的哈希表对比,若有落在同一个bucket的,如果满足连接谓词(predicate)(in,between,like,exists)则连接成新的表。
在内存足够大的情况下建立哈希表的过程时整个表都在内存中,完成连接操作后才放到磁盘里。但这个过程也会带来很多的I/O操作。
特点
- 所有两个参加连接的表只需要被扫描一次;
- 需要整个哈希表都能够被存放在内存里面;
如果内存不能存放完整的哈希表,那么情况会变的比较复杂,一种解决方案如下:
- 读取最大内存可以容纳的记录创建哈希表;
- 另外一张表对于本部分哈希表进行一次全量探测;
- 清理掉哈希表;
- 返回第一步重新执行,直到用于创建哈希表的表记录全部都被处理了一遍;
Grace hash join
因为经典哈希连接对于创建内存不能容纳的哈希表不友好,产生了另外一种算法就是可落盘的哈希算法。这个方法适合用于内存不足的情况,核心在于分块处理。算法具体步骤如下:
第一阶段分块阶段(Partition Phase):把每个关系(relation)分别用同一个哈希函数h(x)在连接属性上进行分块(partition)。分块后每个元组分配到对应的bucket,然后分别把这些buckets写到磁盘当中。
第二阶段和普通的哈希连接类似,将分别来自于两个关系对应的bucket加载到内存中,为较小的那个bucket构建哈希表(注意,这里一定要用不同的哈希函数,因为数据很多的情况下不同值的哈希值可能相同,但不同值的两个哈希值都相同可能性非常小)
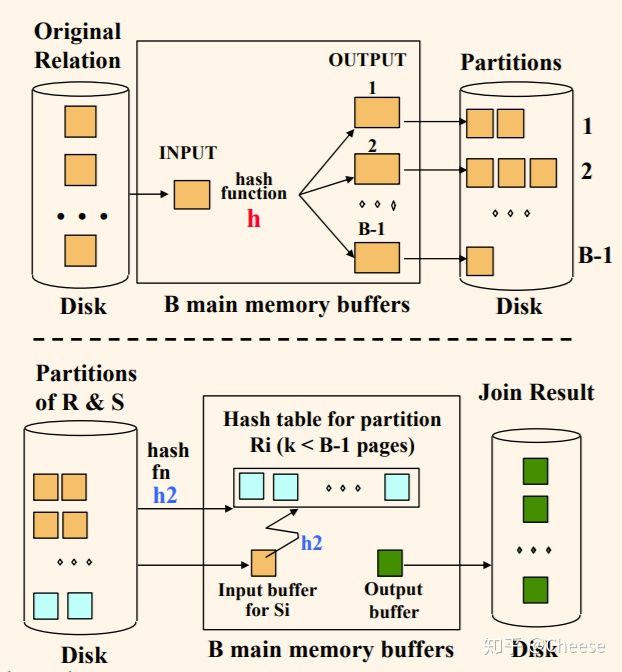
图来自于Database Management Systems, S. Chakravarthy
也有可能出现一个或多个bucket扔无法写入到内存的情况,这时可递归对每一个bucket采用该算法。与此同时这会增加很多时间,所以最好尽可能通过选择合理的哈希函数形成小的bucket来减少这种情况的发生。
注意:这里需要注意第一步划分数据的时候要防止数据倾斜。因为如果第一步划分分片数据不能划分好数据,可能会导致有的分区没用完用于创建哈希表的内存配额,而另外一些分区又放不下的尴尬情况。

若有收获,就点个赞吧
0 人点赞
