访问路径指的就是通过哪种扫描方式获取数据,比如全表扫描、索引扫描或者直接通过 ROWID 获取数据。想要成为 SQL 优化高手,我们就必须深入理解各种访问路径。本章将会详细介绍常见的访问路径。
TABLE ACCESS FULL
TABLE ACCESS FULL 表示全表扫描,一般情况下是多块读,HINT: FULL(表名/别名)。等待事件为 db file scattered read。如果是并行全表扫描,等待事件为 direct path read。在 Oracle11g 中有个新特征,在对一个大表进行全表扫描的时候,会将表直接读入 PGA,绕过 buffer cache,这个时候全表扫描的等待事件也是 direct path read。一般情况下,我们都会禁用该新特征。等待事件 direct path read 在开启了异步 I/O(disk_asynch_io)的情况下统计是不准确的。关于等待事件,本书不做讨论,那毕竟超出了本书范围。
因为 direct path read 统计不准,所以我们在编写本书的时候禁用了 direct path read。
alter system set "_serial_direct_read"=false;
System altered.
全表扫描究竟是怎么扫描数据的呢?回忆一下 Oracle 的逻辑存储结构,Oracle 最小的存储单位是块(block),物理上连续的块组成了区(extent),区又组成了段(segment)。对于非分区表,如果表中没有 clob/blob 字段,那么一个表就是一个段。全表扫描,其实就是扫描表中所有格式化过的区。因为区里面的数据块在物理上是连续的,所以全表扫描可以多块读。全表扫描不能跨区扫描,因为区与区之间的块物理上不一定是连续的。对于分区表,如果表中没有 clob/blob 字段,一个分区就是一个段,分区表扫描方式与非分区表扫描方式是一样的。
对一个非分区表进行并行扫描,其实就是同时扫描表中多个不同区,因为区与区之间的块物理上不连续,所以我们不需要担心扫描到相同数据块。
对一个分区表进行并行扫描,有两种方式。如果需要扫描多个分区,那么是以分区为粒度进行并行扫描的,这时如果分区数据不均衡,会严重影响并行扫描速度;如果只需要扫描单个分区,这时是以区为粒度进行并行扫描的。
如果表中有 clob 字段,clob 会单独存放在一个段中,当全表扫描需要访问 clob 字段时,这时性能会严重下降,因此尽量避免在 Oracle 中使用 clob。我们可以考虑将 clob 字段拆分为多个 varchar2(4000)字段,或者将 clob 存放在 nosql 数据库中,例如 mongodb。
一般的操作系统,一次 I/O 最多只支持读取或者写入 1MB 数据。数据块为 8KB 的时候,一次 I/O 最多能读取 128 个块。数据块为 16KB 的时候,一次 I/O 最多能读取 64 个块,数据块为 32KB 的时候,一次 I/O 最多能读取 32 个块。
如果表中有部分块已经缓存在 buffer cache 中,在进行全表扫描的时候,扫描到已经被缓存的块所在区时,就会引起 I/O 中断。如果一个表不同的区有大量块缓存在 buffer cache 中,这个时候,全表扫描性能会严重下降,因为有大量的 I/O 中断,导致每次 I/O 不能扫描 1MB 数据。
我们以测试表 test 为例,先查看测试表 test 有多少个区。
select extent_id,blocks, block_idfrom dba_extentswhere segment_name = 'TEST'and owner = 'SCOTT';
EXTENT_ID BLOCKS BLOCK_ID---------- ---------- ----------0 8 5281 8 5362 8 5443 8 5524 8 5605 8 5686 8 5767 8 5848 8 5929 8 60010 8 60811 8 61612 8 62413 8 63214 8 64015 8 64816 128 76817 128 89618 128 102419 128 115220 128 128021 128 140822 128 153623 128 166424 rows selected.
测试表 test 一共有 24 个区,而且每个区都没有超过 128 个块。正常情况下,对测试表 test 进行全表扫描需要进行 24 次多块读。现在我们清空 buffer cache 缓存,对 test 表进行全表扫描,同时使用 10046 事件监控等待事件。
-- SQLPLUS 语句show parameter db_file_multiblock;-- SQLselect VALUE from v$parameter where UPPER(name) LIKE '%DB_FILE_MULTIBLOCK%';
NAME TYPE VALUE------------------------------------ ----------------------------- -----db_file_multiblock_read_count integer 128
alter system flush buffer_cache;
System altered.
alter session set events '10046 trace name context forever, level 8';
Session altered.
select count(*) from test;
COUNT(*)----------72462
alter session set events '10046 trace name context off';
Session altered.
查询 10046 trace文件具体位置:
select distinct(m.sid),s.serial#,p.spid,p.tracefile fromv$mystat m,v$session s,v$process p where m.sid=s.sid and s.paddr=p.addr;

格式化trace
tkprof /u01/app/oracle/diag/rdbms/xe/xe/trace/xe_ora_62499.trcaa.tkp sys=no waits=yes explain=admin/oracle
下面是经过 tkprof 格式化后的 10046 trace 文件的部分数据。
Rows Row Source Operation------- ---------------------------------------------------1 SORT AGGREGATE (cr=1037 pr=1033 pw=0 time=0 us)72462 TABLE ACCESS FULL TEST (cr=1037 pr=1033 pw=0 time=7795 us cost=289 size=0 card=72462)Elapsed times include waiting on following events:Event waited on Times Max. Wait Total Waited---------------------------------------- Waited ---------- ------------SQL*Net message to client 2 0.00 0.00Disk file operations I/O 1 0.00 0.00db file sequential read 1 0.00 0.00db file scattered read 24 0.00 0.01SQL*Net message from client 2 11.10 11.10
正如我们猜想的那样,全表扫描多块读(db file scattered read)耗费了 24 次。
现在我们利用下面 SQL,查找一些介于第 17 个区和第 24 个区之间的 rowid。
select rowid,dbms_rowid.rowid_relative_fno(rowid) file#,dbms_rowid.rowid_block_number(rowid) block#from test;
我们可以根据 block_id 为边界来判断 rowid 在哪个区。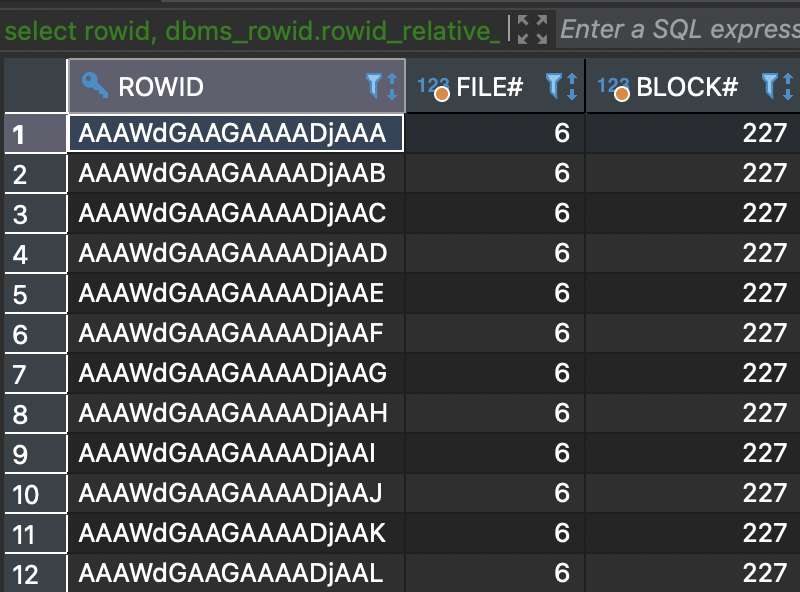
现在我们清空 buffer cache,选取 4 个不同区的 rowid 访问表中数据,这样就将 4 个不同区的块缓存在 buffer cache 中了,然后对 test 表进行全表扫描,同时使用 10046 事件监控等待事件。
alter system flush buffer_cache;
System altered.
select count(*)from testwhere rowid in ('AAASNJAAEAAAAMPAAk', 'AAASNJAAEAAAAQRAAn','AAASNJAAEAAAAQ2AAR', 'AAASNJAAEAAAAUhAAM');
COUNT(*)----------4
alter session set events '10046 trace name context forever, level 8';
Session altered.
select count(*) from test;
COUNT(*)----------72462
alter session set events '10046 trace name context off';
Session altered.
下面是经过 tkprof 格式化后的 10046 trace 文件的部分数据。
Rows Row Source Operation------- ---------------------------------------------------1 SORT AGGREGATE (cr=1037 pr=1029 pw=0 time=0 us)72462 TABLE ACCESS FULL TEST (cr=1037 pr=1029 pw=0 time=10479 us cost=289 size=0 card=72462)Elapsed times include waiting on following events:Event waited on Times Max. Wait Total Waited---------------------------------------- Waited ---------- ------------SQL*Net message to client 2 0.00 0.00db file sequential read 1 0.00 0.00db file scattered read 28 0.00 0.02SQL*Net message from client 2 3.85 3.85
因为缓存了 4 个不同区的块在 buffer cache 中,全表扫描的时候需要中断 4 次 I/O,所以全表扫描多块读一共耗费了 28 次。
如果表正在发生大事务,在进行全表扫描的时候,还会从 undo 读取部分数据。从 undo 读取数据是单块读,这种情况下全表扫描效率非常低下。因此,我们建议使用批量游标的方式处理大事务。使用批量游标处理大事务还可以减少对 undo 的使用,防止事务失败回滚太慢。
以示例表 test 为例,我们先在一个会话中更新表中所有数据,模拟一个大事务。
update test set owner='SCOTT';
72462 rows updated.
我们开启另一个会话,清空 buffer cache 缓存并且设置 10046 事件,然后运行查询。
alter system flush buffer_cache;
System altered.
alter session set events '10046 trace name context forever, level 8';
Session altered.
select count(*) from test;
COUNT(*)----------72462
alter session set events '10046 trace name context off';
Session altered.
下面是经过 tkprof 格式化后的 10046 trace 文件的部分数据。
Rows Row Source Operation------- ---------------------------------------------------1 SORT AGGREGATE (cr=74531 pr=3380 pw=0 time=0 us)72462 TABLE ACCESS FULL TEST (cr=74531 pr=3380 pw=0 time=962057 us cost=289 size=0 card=72462)Elapsed times include waiting on following events:Event waited on Times Max. Wait Total Waited---------------------------------------- Waited ---------- ------------SQL*Net message to client 2 0.00 0.00Disk file operations I/O 1 0.00 0.00db file sequential read 2348 0.00 0.41db file scattered read 24 0.00 0.02SQL*Net message from client 2 11.43 11.43
db file sequential read 表示单块读,一共读取了 2 348 次,这里的单块读就是大事务产生的 undo 所引起的。
Oracle 行存储数据库在进行全表扫描时会扫描表中所有的列。关于行存储与列存储本书将在后面章节介绍。
TABLE ACCESS BY USER ROWID
TABLE ACCESS BY USER ROWID 表示直接用 ROWID 获取数据,单块读。
该访问路径在 Oracle 所有的访问路径中性能是最好的。
我们以测试表 test 为例,运行下面 SQL 并且查看执行计划。
select * from test where rowid='AAASNJAAEAAAAJqAA3';
Execution Plan----------------------------------------------------------Plan hash value: 1358188196-----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 97 | 1 (0)| 00:00:01 || 1 | TABLE ACCESS BY USER ROWID| TEST | 1 | 97 | 1 (0)| 00:00:01 |-----------------------------------------------------------------------------------
在 where 条件中直接使用 rowid 获取数据就会使用该访问路径。
TABLE ACCESS BY ROWID RANGE
TABLE ACCESS BY ROWID RANGE 表示 ROWID 范围扫描,多块读。因为同一个块里面的 ROWID 是连续的,同一个 EXTENT 里面的 ROWID 也是连续的,所以可以多块读。
我们以测试表 test 为例,运行下面 SQL 并且查看执行计划。
select * from test where rowid>='AAASs5AAEAAB+SLAAA';
72462 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 3472873366------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3651 | 345K| 186 (1)| 00:00:03 ||* 1 | TABLE ACCESS BY ROWID RANGE| TEST | 3651 | 345K| 186 (1)| 00:00:03 |------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access(ROWID>='AAASs5AAEAAB+SLAAA')
where 条件中直接使用 rowid 进行范围扫描就会使用该执行计划。
TABLE ACCESS BY INDEX ROWID
TABLE ACCESS BY INDEX ROWID 表示回表,单块读。
INDEX UNIQUE SCAN
INDEX UNIQUE SCAN 表示索引唯一扫描,单块读。
对唯一索引或者对主键列进行等值查找,就会走 INDEX UNIQUE SCAN。因为对唯一索引或者对主键列进行等值查找,CBO 能确保最多只返回 1 行数据,所以这时可以走索引唯一扫描。
我们以 scott 账户中 emp 表为例,运行下面 SQL 并且查看执行计划。
select * from emp where empno=7369;
Execution Plan----------------------------------------------------------Plan hash value: 2949544139-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cos t(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 ||* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - access("EMPNO"=7369)
因为 empno 是主键列,对 empno 进行等值访问,就走了 INDEX UNIQUE SCAN。
INDEX UNIQUE SCAN 最多只返回一行数据,只会扫描「索引高度」个索引块,在所有的 Oracle 访问路径中,其性能仅次于 TABLE ACCESS BY USER ROWID。
INDEX RANGE SCAN
INDEX RANGE SCAN 表示索引范围扫描,单块读,返回的数据是有序的(默认升序)。HINT: INDEX(表名/别名 索引名)。对唯一索引或者主键进行范围查找,对非唯一索引进行等值查找,范围查找,就会发生 INDEX RANGE SCAN。等待事件为 db file sequential read。
我们以测试表 test 为例,运行下面 SQL 并且查看执行计划。
select * from test where object_id=100;
Execution Plan----------------------------------------------------------Plan hash value: 3946039639-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 97 | 2 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 97 | 2 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | IDX_ID | 1 | | 1 (0)| 00:00:01 |-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - access("OBJECT_ID"=100)
因为索引 IDX_ID 是非唯一索引,对非唯一索引进行等值查找并不能确保只返回一行数据,有可能返回多行数据,所以执行计划会进行索引范围扫描。
索引范围扫描默认是从索引中最左边的叶子块开始,然后往右边的叶子块扫描(从小到大),当检查到不匹配数据的时候,就停止扫描。现在我们将过滤条件改为小于,并且对过滤列进行降序排序,查看执行计划。
select * from test where object_id<100 order by object_id desc;
98 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 1069979465-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 96 | 9312 | 4 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID | TEST | 96 | 9312 | 4 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN DESCENDING| IDX_ID | 96 | | 2 (0)| 00:00:01 |-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - access("OBJECT_ID"<100)filter("OBJECT_ID"<100)
INDEX RANGE SCAN DECENDING 表示索引降序范围扫描,从右往左扫描,返回的数据是降序显示的。
假设一个索引叶子块能存储 100 行数据,通过索引返回 100 行以内的数据,只扫描「索引高度」个索引块,如果通过索引返回 200 行数据,就需要扫描两个叶子块。通过索引返回的行数越多,扫描的索引叶子块也就越多,随着扫描的叶子块个数的增加,索引范围扫描的性能开销也就越大。如果索引范围扫描需要回表,同样假设一个索引叶子块能存储 100 行数据,通过索引返回 1000 行数据,只需要扫描 10 个索引叶子块(单块读),但是回表可能会需要访问几十个到几百个表块(单块读)。在检查执行计划的时候我们要注意索引范围扫描返回多少行数据,如果返回少量数据,不会出现性能问题;如果返回大量数据,在没有回表的情况下也还好;如果返回大量数据同时还有回表,这时我们应该考虑通过创建组合索引消除回表或者使用全表扫描来代替它。
INDEX SKIP SCAN
INDEX SKIP SCAN 表示索引跳跃扫描,单块读。返回的数据是有序的(默认升序)。HINT: INDEX_SS(表名/别名 索引名)。当组合索引的引导列(第一个列)没有在 where 条件中,并且组合索引的引导列/前几个列的基数很低,where 过滤条件对组合索引中非引导列进行过滤的时候就会发生索引跳跃扫描,等待事件为 db file sequential read。
我们在测试表 test 上创建如下索引。
create index idx_ownerid on test(owner,object_id);
Index created.
然后我们删除 object_id 列上的索引 IDX_ID。
drop index idx_id;
Index dropped.
我们执行如下 SQL 并且查看执行计划。
select * from test where object_id<100;
98 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 847134193-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 96 | 9312 | 100 (0)| 00:00:02| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 96 | 9312 | 100 (0)| 00:00:02|* 2 | INDEX SKIP SCAN | IDX_OWNERID | 96 | | 97 (0)| 00:00:02-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - access("OBJECT_ID"<100)filter("OBJECT_ID"<100)
从执行计划中我们可以看到上面 SQL 走了索引跳跃扫描。最理想的情况应该是直接走 where 条件列 object_id 上的索引,并且走 INDEX RANGE SCAN。但是因为 where 条件列上面没有直接创建索引,而是间接地被包含在组合索引中,为了避免全表扫描,CBO 就选择了索引跳跃扫描。
INDEX SKIP SCAN 中有个 SKIP 关键字,也就是说它是跳着扫描的。那么想要跳跃扫描,必须是组合索引,如果是单列索引怎么跳?另外,组合索引的引导列不能出现在 where 条件中,如果引导列出现在 where 条件中,它为什么还跳跃扫描呢,直接 INDEX RANGE SCAN 不就可以了?再有,要引导列基数很低,如果引导列基数很高,那么它「跳」的次数就多了,性能就差了。
当执行计划中出现了 INDEX SKIP SCAN,我们可以直接在过滤列上面建立索引,使用 INDEX RANGE SCAN 代替 INDEX SKIP SCAN。
INDEX FULL SCAN
INDEX FULL SCAN 表示索引全扫描,单块读,返回的数据是有序的(默认升序)。HINT: INDEX(表名/别名 索引名)。索引全扫描会扫描索引中所有的叶子块(从左往右扫描),如果索引很大,会产生严重性能问题(因为是单块读)。等待事件为 db file sequential read。
它通常发生在下面 3 种情况。
- 分页语句,分页语句在本书第 8 章中会详细介绍,这里不做赘述。
- SQL 语句有 order by 选项,order by 的列都包含在索引中,并且 order by 后列顺序必须和索引列顺序一致。order by 的第一个列不能有过滤条件,如果有过滤条件就会走索引范围扫描(INDEX RANGE SCAN)。同时表的数据量不能太大(数据量太大会走 TABLE ACCESS FULL + SORT ORDER BY)。我们有如下 SQL。
select * from test order by object_id,owner;
我们创建如下索引(索引顺序必须与排序顺序一致,加 0 是为了让索引能存 NULL)。
create index idx_idowner on test(object_id,owner,0);
Index created.
我们执行如下 SQL 并且查看执行计划。
select * from test order by object_id,owner;
72462 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 3870803568-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes |Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 73020 | 6916K|1338 (1)| 00:00:17 || 1 | TABLE ACCESS BY INDEX ROWID| TEST | 73020 | 6916K|1338 (1)| 00:00:17 || 2 | INDEX FULL SCAN | IDX_IDOWNER | 73020 | | 242 (1)| 00:00:03 |-------------------------------------------------------------------------------------
- 在进行 SORT MERGE JOIN 的时候,如果表数据量比较小,让连接列走 INDEX FULL SCAN 可以避免排序。例子如下。
select /*+ use_merge(e,d) */*from emp e, dept dwhere e.deptno = d.deptno;
14 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 844388907-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 14 | 812 | 6 (17)| 00:00:01 || 1 | MERGE JOIN | | 14 | 812 | 6 (17)| 00:00:01 || 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00:00:01 || 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00:00:01 ||* 4 | SORT JOIN | | 14 | 532 | 4 (25)| 00:00:01 || 5 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00:00:01 |-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------4 - access("E"."DEPTNO"="D"."DEPTNO")filter("E"."DEPTNO"="D"."DEPTNO")
当看到执行计划中有 INDEX FULL SCAN,我们首先要检查 INDEX FULL SCAN 是否有回表。
如果 INDEX FULL SCAN 没有回表,我们要检查索引段大小,如果索引段太大(GB 级别),应该使用 INDEX FAST FULL SCAN 代替 INDEX FULL SCAN,因为 INDEX FAST FULL SCAN 是多块读,INDEX FULL SCAN 是单块读,即使使用了 INDEX FAST FULL SCAN 会产生额外的排序操作,也要用 INDEX FAST FULL SCAN 代替 INDEX FULL SCAN。
如果 INDEX FULL SCAN 有回表,大多数情况下,这种执行计划是错误的,因为 INDEX FULL SCAN 是单块读,回表也是单块读。这时应该走全表扫描,因为全表扫描是多块读。如果分页语句走了 INDEX FULL SCAN 然后回表,这时应该没有太大问题,具体原因请大家阅读本书 8.3 节。
INDEX FAST FULL SCAN
INDEX FAST FULL SCAN 表示索引快速全扫描,多块读。HINT:INDEX_FFS(表名/别名 索引名)。当需要从表中查询出大量数据但是只需要获取表中部分列的数据的,我们可以利用索引快速全扫描代替全表扫描来提升性能。索引快速全扫描的扫描方式与全表扫描的扫描方式是一样,都是按区扫描,所以它可以多块读,而且可以并行扫描。等待事件为 db file scattered read,如果是并行扫描,等待事件为 direct path read。
现有如下 SQL。
select owner,object_name from test;
该 SQL 没有过滤条件,默认情况下会走全表扫描。但是因为 Oracle 是行存储数据库,全表扫描的时候会扫描表中所有的列,而上面查询只访问表中两个列,全表扫描会多扫描额外 13 个列,所以我们可以创建一个组合索引,使用索引快速全扫描代替全表扫描。
create index idx_ownername on test(owner,object_name,0);
Index created.
我们查看 SQL 执行计划。
select owner,object_name from test;
72462 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 3888663772-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 73020 | 2210K| 79 (2)| 00:00:01 || 1 | INDEX FAST FULL SCAN| IDX_OWNERNAME | 73020 | 2210K| 79 (2)| 00:00:01 |-------------------------------------------------------------------------------------
现有如下 SQL。
select object_name from test where object_id<100;
该 SQL 有过滤条件,根据过滤条件where object_id<100过滤数据之后只返回少量数据,一般情况下我们直接在 object_id 列创建索引,让该 SQL 走 object_id 列的索引即可。
create index idx_id on test(object_id);
Index created.
select object_name from test where object_id <100;
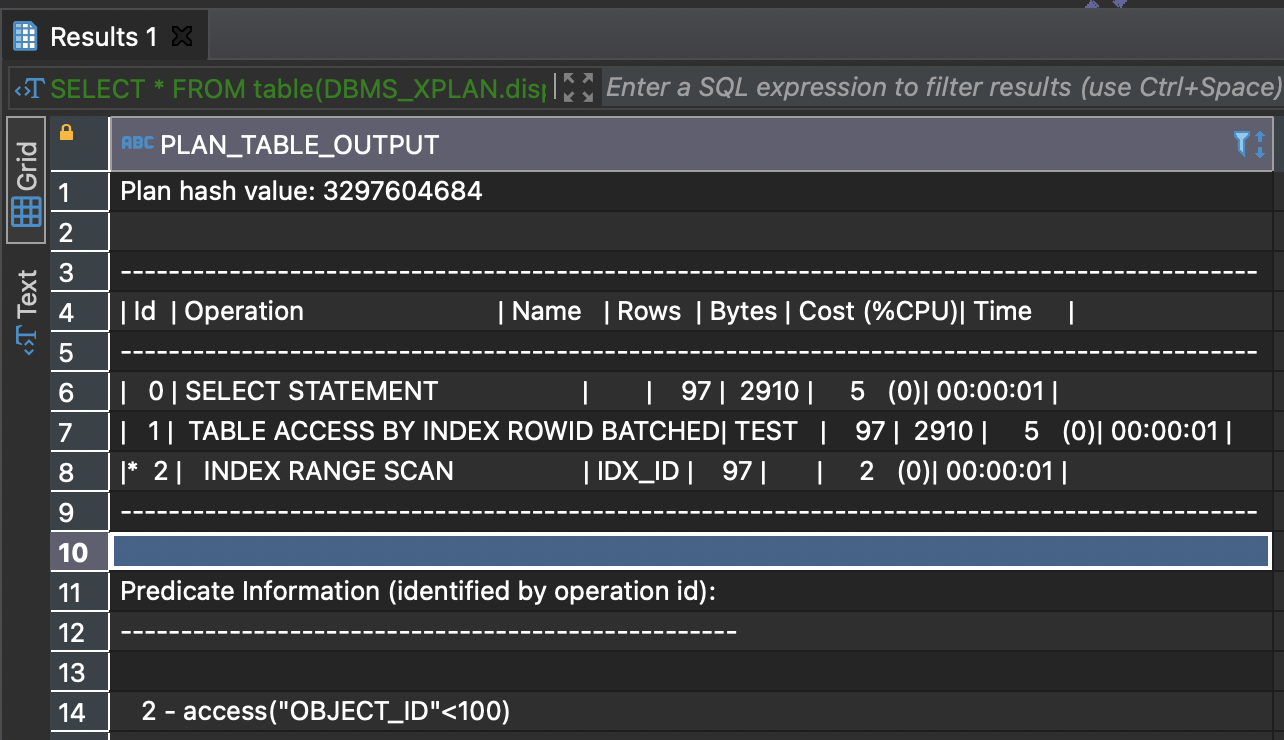
18 consistent gets0 physical reads0 redo size2217 bytes sent via SQL*Net to client485 bytes received via SQL*Net from client8 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)98 rows processed
因为该 SQL 只查询一个字段,所以我们可以将 select 列放到组合索引中,避免回表。
create index idx_idname on test(object_id,object_name);
Index created.
我们再次查看 SQL 的执行计划。
select object_name from test where object_id<100;
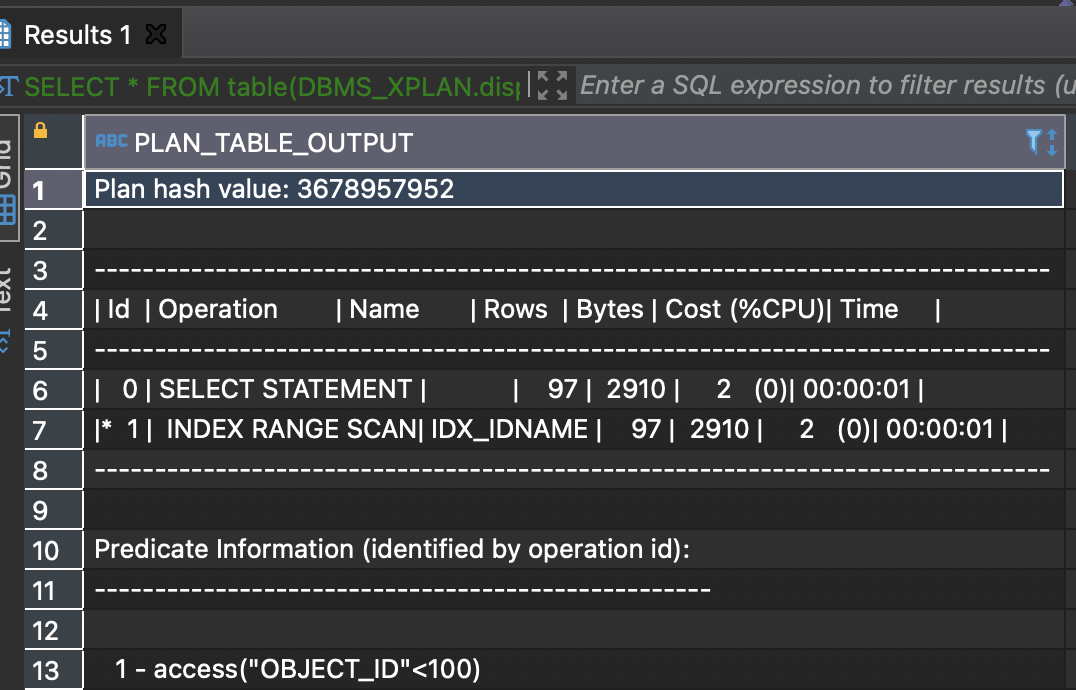
9 consistent gets0 physical reads0 redo size2217 bytes sent via SQL*Net to client485 bytes received via SQL*Net from client8 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)98 rows processed
现有如下 SQL。
select object_name from test where object_id>100;
以上 SQL 过滤条件是where object_id>100,返回大量数据,应该走全表扫描,但是因为 SQL 只访问一个字段,所以我们可以走索引快速全扫描来代替全表扫描。
select object_name from test where object_id>100;
72363 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 252646278-----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 72924 | 2136K| 73 (2)| 00:00:01 ||* 1 | INDEX FAST FULL SCAN| IDX_IDNAME | 72924 | 2136K| 73 (2)| 00:00:01 |-----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter("OBJECT_ID">100)
大家可能会有疑问,以上 SQL 能否走 INDEX RANGE SCAN 呢?INDEX RANGE SCAN 是单块读,SQL 会返回表中大量数据,「几乎」会扫描索引中所有的叶子块。INDEX FAST FULL SCAN 是多块读,会扫描索引中所有的块(根块、所有的分支块、所有的叶子块)。虽然 INDEX RANGE SCAN 与 INDEX FAST FULL SCAN 相比扫描的块少(逻辑读少),但是 INDEX RANGE SCAN 是单块读,耗费的 I/O 次数比 INDEX FAST FULL SCAN 的 I/O 次数多,所以 INDEX FAST FULL SCAN 性能更好。
在做 SQL 优化的时候,我们不要只看逻辑读来判断一个 SQL 性能的好坏,物理 I/O 次数比逻辑读更为重要。有时候逻辑读高的执行计划性能反而比逻辑读低的执行计划性能更好,因为逻辑读高的执行计划物理 I/O 次数比逻辑读低的执行计划物理 I/O 次数低。
在 Oracle 数据库中,INDEX FAST FULL SCAN 是用来代替 TABLE ACCESS FULL 的。因为 Oracle 是行存储数据库,TABLE ACCESS FULL 会扫描表中所有的列,而 INDEX FAST FULL SCAN 只需要扫描表中部分列,INDEX FAST FULL SCAN 就是由 Oracle 是行存储这个「缺陷」而产生的。
如果数据库是 Exadata,INDEX FAST FULL SCAN 几乎没有用武之地,因为 Exadata 是行列混合存储,在全表扫描的时候可以只扫描需要的列(Smart Scan),没必要使用 INDEX FAST FULL SCAN 来代替全表扫描。如果我们在 Exadata 中强行使用 INDEX FAST FUL SCAN 来代替全表扫描,反而会降低数据库性能,因为没办法使用 Exadata 中的 Smart Scan。
如果我们启用了 12c 中的新特性 IN MEMORY OPTION,INDEX FAST FULL SCAN 几乎也没有用武之地了,因为表中的数据可以以列的形式存放在内存中,这时直接访问内存中的数据即可。
INDEX FULL SCAN(MIN/MAX)
INDEX FULL SCAN(MIN/MAX)表示索引最小/最大值扫描、单块读,该访问路径发生在 SELECT MAX(COLUMN)FROM TABLE 或者 SELECT MIN(COLUMN)FROM TABLE等 SQL 语句中。
INDEX FULL SCAN(MIN/MAX)只会访问「索引高度」个索引块,其性能与 INDEX UNIQUE SCAN 一样,仅次于 TABLE ACCESS BY USER ROWID。
现有如下 SQL。
select max(object_id) from t;
该 SQL 查询 object_id 的最大值,如果 object_id 列有索引,索引默认是升序排序的,这时我们只需要扫描索引中「最右边」的叶子块就能得到 object_id 的最大值。现在我们查看该 SQL 的执行计划。
select max(object_id) from t;
Elapsed: 00:00:00.00Execution Plan----------------------------------------------------------Plan hash value: 2448092560-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 13 | 186 (1)| 00:00:03 || 1 | SORT AGGREGATE | | 1 | 13 | | || 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | |-------------------------------------------------------------------------------------Note------ dynamic sampling used for this statement (level=2)Statistics----------------------------------------------------------0 recursive calls0 db block gets2 consistent gets0 physical reads0 redo size430 bytes sent via SQL*Net to client419 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed
现有另外一个 SQL。
select max(object_id),min(object_id) from t;
该 SQL 要同时查看 object_id 的最大值和最小值,如果想直接从 object_id 列的索引获取数据,我们只需要扫描索引中「最左边」和「最右边」的叶子块就可以。在 Btree 索引中,索引叶子块是双向指向的,如果要一次性获取索引中「最左边」和「最右边」的叶子块,我们就需要连带的扫描「最大值」与「最小值」中间的叶子块,而本案例中,中间叶子块的数据并不是我们需要的。如果该 SQL 走索引,会走 INDEX FAST FULL SCAN,而不会走 INDEX FULL SCAN,因为 INDEX FAST FULL SCAN 可以多块读,而 INDEX FULL SCAN 是单块读,两者性能差距巨大(如果索引已经缓存在 buffer cache 中,走 INDEX FULL SCAN 与 INDEX FAST FULL SCAN 效率几乎一样,因为不需要物理 I/O)。需要注意的是,该 SQL 没有排除 object_id 为 NULL,如果直接运行该 SQL,不会走索引。
select max(object_id),min(object_id) from t;
Elapsed: 00:00:00.02Execution Plan----------------------------------------------------------Plan hash value: 2966233522---------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 13 | 186 (1)| 00:00:03 || 1 | SORT AGGREGATE | | 1 | 13 | | || 2 | TABLE ACCESS FULL| T | 67907 | 862K| 186 (1)| 00:00:03 |---------------------------------------------------------------------------
我们排除 object_id 为 NULL,查看执行计划。
select max(object_id),min(object_id) from t where object_id is not null;
Elapsed: 00:00:00.01Execution Plan----------------------------------------------------------Plan hash value: 3570898368----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 13 | 33 (4)| 00:00:01 || 1 | SORT AGGREGATE | | 1 | 13 | | ||* 2 | INDEX FAST FULL SCAN| IDX_T_ID | 67907 | 862K| 33 (4)| 00:00:01 |----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - filter("OBJECT_ID" IS NOT NULL)Note------ dynamic sampling used for this statement (level=2)Statistics----------------------------------------------------------0 recursive calls0 db block gets169 consistent gets0 physical reads0 redo size501 bytes sent via SQL*Net to client419 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed
从上面的执行计划中我们可以看到 SQL 走了 INDEX FAST FULL SCAN,INDEX FAST FULL SCAN 会扫描索引段中所有的块,理想的情况是只扫描索引中「最左边」和「最右边」的叶子块。现在我们将该 SQL 改写为如下 SQL。
select (select max(object_id) from t),(select min(object_id) from t) from dual;
我们查看后的执行计划。
select (select max(object_id) from t),(select min(object_id) from t) from dual;
Elapsed: 00:00:00.01Execution Plan----------------------------------------------------------Plan hash value: 3622839313-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 2 (0)| 00:00:01 || 1 | SORT AGGREGATE | | 1 | 13 | | || 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | || 3 | SORT AGGREGATE | | 1 | 13 | | || 4 | INDEX FULL SCAN (MIN/MAX)| IDX_T_ID | 67907 | 862K| | || 5 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 |-------------------------------------------------------------------------------------Note------ dynamic sampling used for this statement (level=2)Statistics----------------------------------------------------------0 recursive calls0 db block gets4 consistent gets0 physical reads0 redo size527 bytes sent via SQL*Net to client419 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed
原始 SQL 因为需要 1 次性从索引中取得最大值和最小值,所以导致走了 INDEX FAST FULL SCAN。我们将该 SQL 进行等价改写之后,访问了索引两次,一次取最大值,一次取最小值,从而避免扫描不需要的索引叶子块,大大提升了查询性能。
MAT_VIEW REWRITE ACCESS FULL
MAT_VIEW REWRITE ACCESS FULL 表示物化视图全表扫描、多块读。因为物化视图本质上也是一个表,所以其扫描方式与全表扫描方式一样。如果我们开启了查询重写功能,而且 SQL 查询能够直接从物化视图中获得结果,就会走该访问路径。
现在我们创建一个物化视图 TEST_MV。
create materialized view test_mvbuild immediate enable query rewriteas select object_id,object_name from test;
Materialized view created.
有如下 SQL 查询。
select object_id,object_name from test;
因为物化视图 TEST_MV 已经包含查询需要的字段,所以该 SQL 会直接访问物化视图 TEST_MV。
select object_id,object_name from test;
72462 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 1627509066-------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |-------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 67036 | 5171K| 65 (2)| 00:00:01 || 1 | MAT_VIEW REWRITE ACCESS FULL| TEST_MV | 67036 | 5171K| 65 (2)| 00:00:01 |-------------------------------------------------------------------------------------

若有收获,就点个赞吧
0 人点赞
