关系型数据库中,表与表之间会进行关联,在进行关联的时候,我们一定要理清楚表与表之间的关系。表与表之间存在 3 种关系。一种是 1∶1 关系,一种是 1∶N关系,最后一种是N∶N关系。搞懂表与表之间关系,对于 SQL 优化、SQL 等价改写、表设计优化以及分表分库都有巨大帮助。
两表在进行关联的时候,如果两表属于 1∶1 关系,关联之后返回的结果也是属于 1 的关系,数据不会重复。如果两表属于 1∶N关系,关联之后返回的结果集属于N的关系。如果两表属于N∶N关系,关联之后返回的结果集会产生局部范围的笛卡儿积,N∶N关系一般不存在内/外连接中,只能存在于半连接或者反连接中。
如果我们不知道业务,不知道数据字典,怎么判断两表是什么关系呢?我们以下面 SQL 为例子。
select * from emp e, dept d where e.deptno = d.deptno;
我们只需要对两表关联列进行汇总统计就能知道两表是什么关系。
select deptno, count(*) from emp group by deptno order by 2 desc;
DEPTNO COUNT(*)---------- ----------30 620 510 3
select deptno, count(*) from dept group by deptno order by 2 desc;
DEPTNO COUNT(*)---------- ----------10 140 130 120 1
从上面查询我们可以知道两表 emp 与 dept 是N∶1 关系。搞清楚表与表之间关系对于 SQL 优化很有帮助。
2013 年,我们曾遇到一个案例,SQL 运行了 12 秒,SQL 文本如下。
select count(*) from a left join b on a.id=b.id;
案例中 a 与 b 是 1∶1 关系,a 与 b 都是上千万数据量。因为 a 与 b 是使用外连接进行关联,不管 a 与 b 是否关联上,始终都会返回 a 的数据,SQL 语句中求的是两表关联后的总行数,因为两表是 1∶1 关系,关联之后数据不会翻番,那么该 SQL 等价于如下文本。
select count(*) from a;
我们将 SQL 改写之后,查询可以秒出。如果 a 与 b 是n∶1 关系,我们也可以将 b 表去掉,因为两表关联之后数据不会翻倍。如果 b 表属于n的关系,这时我们不能去掉 b 表,因为这时关联之后数据量会翻番。
在本书后面的标量子查询等价改写、半连接等价改写以及 SQL 优化案例章节中我们就会用到表与表之间关系这个重要的概念。
数据准备
先准备两张表:
- 学生表:student
select * from student;
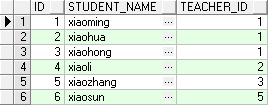
- 教师表:teacher
select * from teacher;
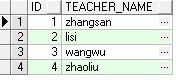
内连接
在每个表中找出符合条件的共有记录。[x inner join y on...]
第一种写法:(只使用where)
select t.teacher_name, s.student_name from teacher t,student s where t.id = s.teacher_id;
第二种写法:(join .. on.. )
select t.teacher_name, s.student_name from teacher t join student s on t.id = s.teacher_id;
第三种写法:(inner join .. on.. )
select t.teacher_name, s.student_name from teacher t inner join student s on t.id = s.teacher_id;
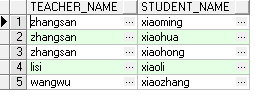
外连接
外连接有三种方式:左连接,右连接和全连接。
左连接
根据左表的记录,在被连接的右表中找出符合条件的记录与之匹配,如果找不到与左表匹配的,用null表示。[x left [outer] join y on...
第一种写法:(left join .. on ..)
select t.teacher_name, s.student_name from teacher t left join student s on t.id = s.teacher_id;
第二种写法:(left outer join .. on ..)
select t.teacher_name, s.student_name from teacher t left outer join student s on t.id = s.teacher_id;
第三种写法:(+) 所在位置的另一侧为连接的方向
select t.teacher_name, s.student_name from teacher t, student swhere t.id = s.teacher_id(+);
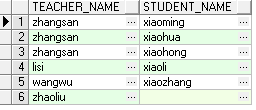
右连接
根据右表的记录,在被连接的左表中找出符合条件的记录与之匹配,如果找不到匹配的,用null填充。[x right [outer] join y on...]
第一种写法:(right join .. on..)
select t.teacher_name, s.student_name from teacher t right join student s on t.id = s.teacher_id;
第二种写法:right outer join .. on ..
select t.teacher_name, s.student_name from teacher t right outer join student s on t.id = s.teacher_id;
第三种写法:(+) 所在位置的另一侧为连接的方向
select t.teacher_name, s.student_name from teacher t, student s where t.id(+) = s.teacher_id;
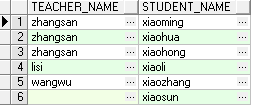
全连接
返回符合条件的所有表的记录,没有与之匹配的,用null表示(结果是左连接和右连接的并集)
第一种写法:(full join .. on ..)
select t.teacher_name, s.student_name from teacher t full join student s on t.id = s.teacher_id;
第二种写法:(full outer join .. on)
select t.teacher_name, s.student_name from teacher t full outer join student s on t.id = s.teacher_id;
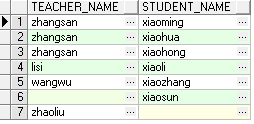
自连接
自连接,连接的两个表都是同一个表,同样可以由内连接,外连接各种组合方式,按实际应用去组合。
SELECT a.*, b.* FROM table_1 a,table_1 b WHERE a.[name] = b.[name]
半连接
半连接返回左表中与右表至少匹配一次的数据行,通常体现为EXISTS 或者IN子查询。左表驱动右表。只返回左表的数据,右表作为筛选条件。
可以用EXISTS、IN 或者 =ANY
举例:表t1和表t2做半连接,t1是驱动表,t2是被驱动表,半连接条件为t1.x=t2.y。
这里t1.x semi= t2.y的含义是只要在表t2中找到一条记录满足t1.x=t2.y,则马上停止搜索表t2,并直接返回表T1中满足条件t1.x=t2.y的记录。表t2中满足半连接条件t1.x=t2.y的记录即使有多条,表t1中也只会返回第一条满足条件的记录。
所以半连接和普通的内连接不同,半连接实际上会去重。
反连接
反连接返回左表中与右表不匹配的数据行,通常体现为 NOT EXISTS或者 NOT IN子查询。反连接的逻辑与半连接正好相反
可以用NOT EXISTS、NOT IN 或者 !=ALL操作符
反连接只返回左表的数据,右表负责条件判断
半连接、反连接等价于首先通过左外连接获取所有满足条件的数据,然后使用 WHERE 条件找出右表中存在/不存在的数据,最后执行 DISTINCT 操作去除重复值;效率低,不过大多数数据库可以实现这两者的等价转换。

若有收获,就点个赞吧
0 人点赞
