子查询非嵌套(Subquery Unnesting):当 where 子查询中有 in、not in、exists、not exists 等,CBO 会尝试将子查询展开(unnest),从而消除 FILTER,这个过程就叫作子查询非嵌套。子查询非嵌套的目的就是消除 FILTER。
现有如下 SQL 及其执行计划(Oracle11.2.0.1)。
select ename, deptnofrom empwhere exists (select deptnofrom deptwhere dname = 'CHICAGO'and emp.deptno = dept.deptnounionselect deptnofrom deptwhere loc = 'CHICAGO'and dept.deptno = emp.deptno);
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2705207488-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost(%CPU)|Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 5 | 45 | 15 (40)|00:00:01||* 1 | FILTER | | | | | || 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)|00:00:01|| 3 | SORT UNIQUE | | 2 | 24 | 4 (75)|00:00:01|| 4 | UNION-ALL | | | | | ||* 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)|00:00:01||* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01||* 7 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 11 | 1 (0)|00:00:01||* 8 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01|-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter( EXISTS ( (SELECT "DEPTNO" FROM "DEPT" "DEPT" WHERE"DEPT"."DEPTNO"=:B1 AND "DNAME"='CHICAGO')UNION (SELECT "DEPTNO" FROM "DEPT""DEPT" WHERE "DEPT"."DEPTNO"=:B2 AND "LOC"='CHICAGO')))5 - filter("DNAME"='CHICAGO')6 - access("DEPT"."DEPTNO"=:B1)7 - filter("LOC"='CHICAGO')8 - access("DEPT"."DEPTNO"=:B1)
执行计划中出现了 FILTER,驱动表因此被固定为 EMP。假设 EMP 有几百万甚至几千万行数据,那么该 SQL 效率就非常差。
现在将上述 SQL 改写如下。
select ename, deptnofrom empwhere exists (select 1from (select deptnofrom deptwhere dname = 'CHICAGO'unionselect deptno from dept where loc = 'CHICAGO') awhere a.deptno = emp.deptno);
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 4243948922------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 5 | 110 | 12 (25)| 00:00:01 ||* 1 | HASH JOIN SEMI | | 5 | 110 | 12 (25)| 00:00:01 || 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 || 3 | VIEW | | 2 | 26 | 8 (25)| 00:00:01 || 4 | SORT UNIQUE | | 1 | 24 | 8 (63)| 00:00:01 || 5 | UNION-ALL | | | | | ||* 6 | TABLE ACCESS FULL| DEPT | 1 | 13 | 3 (0)| 00:00:01 ||* 7 | TABLE ACCESS FULL| DEPT | 1 | 11 | 3 (0)| 00:00:01 |------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access("A"."DEPTNO"="EMP"."DEPTNO")6 - filter("DNAME"='CHICAGO')7 - filter("LOC"='CHICAGO')
对 SQL 进行等价改写之后,消除了 FILTER。为什么要消除 FILTER 呢?因为 FILTER 的驱动表是固定的,一旦驱动表被固定,那么执行计划也就被固定了。对于 DBA 来说这并不是好事,因为一旦固定的执行计划本身是错误的(低效的),就会引起性能问题,想要提升性能必须改写 SQL 语句,但是这时 SQL 已经上线,无法更改,所以,一定要消除 FILTER。
很多公司都有开发 DBA,开发 DBA 很大一部分的工作职责就是:必须保证 SQL 上线之后,每个 SQL 语句的执行计划都是可控的,这样才能尽可能避免系统中 SQL 越跑越慢。
下面我们继续对上述 SQL 进行等价改写。
select ename, deptnofrom empwhere deptno in (select deptnofrom deptwhere dname = 'CHICAGO'unionselect deptno from dept where loc = 'CHICAGO');
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2842951954----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 9 | 198 | 12 (25)| 00:00:01 ||* 1 | HASH JOIN | | 9 | 198 | 12 (25)| 00:00:01 || 2 | VIEW | VW_NSO_1 | 2 | 26 | 8 (25)| 00:00:01 || 3 | SORT UNIQUE | | 2 | 24 | 8 (63)| 00:00:01 || 4 | UNION-ALL | | | | | ||* 5 | TABLE ACCESS FULL| DEPT | 1 | 13 | 3 (0)| 00:00:01 ||* 6 | TABLE ACCESS FULL| DEPT | 1 | 11 | 3 (0)| 00:00:01 || 7 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 |----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - access("DEPTNO"="DEPTNO")5 - filter("DNAME"='CHICAGO')6 - filter("LOC"='CHICAGO')
将 SQL 改写为 in 之后,也消除了 FILTER。
如何才能产生 FILTER 呢?我们只需要在子查询中添加/*+ no_unnest */。
select ename, deptnofrom empwhere deptno in (select /*+ no_unnest */ deptnofrom deptwhere dname = 'CHICAGO'unionselect deptno from dept where loc = 'CHICAGO');
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2705207488-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost(%CPU)|Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 5 | 45 | 15 (40)|00:00:01||* 1 | FILTER | | | | | || 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)|00:00:01|| 3 | SORT UNIQUE | | 2 | 24 | 4 (75)|00:00:01|| 4 | UNION-ALL | | | | | ||* 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)|00:00:01||* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01||* 7 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 11 | 1 (0)|00:00:01||* 8 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01|-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter( EXISTS ( (SELECT /*+ NO_UNNEST */ "DEPTNO" FROM "DEPT" "DEPT"WHERE "DEPTNO"=:B1 AND "DNAME"='CHICAGO')UNION (SELECT "DEPTNO" FROM "DEPT""DEPT" WHERE "DEPTNO"=:B2 AND "LOC"='CHICAGO')))5 - filter("DNAME"='CHICAGO')6 - access("DEPTNO"=:B1)7 - filter("LOC"='CHICAGO')8 - access("DEPTNO"=:B1)
大家可能会问,既然能通过 HINT(NO_UNNEST)让执行计划产生 FILTER,那么执行计划中如果产生了 FILTER,能否通过 HINT(UNNEST)消除 FILTER 呢?执行计划中的 FILTER 很少能够通过 HINT 消除,一般需要通过 SQL 等价改写来消除。
现在我们对产生 FILTER 的 SQL 添加 HINT(UNNEST)来尝试消除 FILTER。
select ename, deptnofrom empwhere exists (select /*+ unnest */ deptnofrom deptwhere dname = 'CHICAGO'and emp.deptno = dept.deptnounionselect deptnofrom deptwhere loc = 'CHICAGO'and dept.deptno = emp.deptno);
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2705207488-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost(%CPU)|Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 5 | 45 | 15 (40)|00:00:01||* 1 | FILTER | | | | | || 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)|00:00:01|| 3 | SORT UNIQUE | | 2 | 24 | 4 (75)|00:00:01|| 4 | UNION-ALL | | | | | ||* 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)|00:00:01||* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01||* 7 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 11 | 1 (0)|00:00:01||* 8 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01|-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter( EXISTS ( (SELECT /*+ UNNEST */ "DEPTNO" FROM "DEPT" "DEPT" WHERE"DEPT"."DEPTNO"=:B1 AND "DNAME"='CHICAGO')UNION (SELECT "DEPTNO" FROM "DEPT""DEPT" WHERE "DEPT"."DEPTNO"=:B2 AND "LOC"='CHICAGO')))5 - filter("DNAME"='CHICAGO')6 - access("DEPT"."DEPTNO"=:B1)7 - filter("LOC"='CHICAGO')8 - access("DEPT"."DEPTNO"=:B1)
执行计划中还是有 FILTER。再次强调:执行计划中如果产生了 FILTER,一般是无法通过 HINT 消除的,一定要注意执行计划中的 FILTER。
请注意,虽然我们一直强调要消除执行计划中的 FILTER,本意是要保证执行计划是可控的,并不意味着执行计划产生了 FILTER 就一定性能差,相反有时候我们还可以用 FILTER 来优化 SQL。
哪些 SQL 写法容易产生 FILTER 呢?当子查询语句含有 exists 或者 not exists 时,子查询中有固化子查询关键词(union/union all/start with connect by/rownum/cube/rollup),那么执行计划中就容易产生 FILTER,例如,exists 中有 rownum 产生 FILTER。
select ename, deptnofrom empwhere exists (select deptnofrom deptwhere loc = 'CHICAGO'and dept.deptno = emp.deptnoand rownum <= 1);
6 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 3414630506-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes | Cost (%CPU)|Time |-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 5 | 45 | 6 (0)|00:00:01||* 1 | FILTER | | | | | || 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)|00:00:01||* 3 | COUNT STOPKEY | | | | | ||* 4 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 11 | 1 (0)|00:00:01||* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)|00:00:01|-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter( EXISTS (SELECT 0 FROM "DEPT" "DEPT" WHERE ROWNUM<=1 AND"DEPT"."DEPTNO"=:B1 AND "LOC"='CHICAGO'))3 - filter(ROWNUM<=1)4 - filter("LOC"='CHICAGO')5 - access("DEPT"."DEPTNO"=:B1)
exists 中有树形查询产生 FILTER。
select *from deptwhere exists (select nullfrom empwhere dept.deptno = emp.deptnostart with empno = 7698connect by prior empno = mgr);
Execution Plan----------------------------------------------------------Plan hash value: 4210865686-------------------------------------------------------------------------------------| Id |Operation | Name | Rows | Bytes |Cost (%CPU)|-------------------------------------------------------------------------------------| 0 |SELECT STATEMENT | | 1 | 20 | 9 (0)||* 1 | FILTER | | | | || 2 | TABLE ACCESS FULL | DEPT | 4 | 80 | 3 (0)||* 3 | FILTER | | | | ||* 4 | CONNECT BY NO FILTERING WITH SW (UNIQUE)| | | | || 5 | TABLE ACCESS FULL | EMP | 14 | 154 | 3 (0)|-------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter( EXISTS (SELECT 0 FROM "EMP" "EMP" WHERE "EMP"."DEPTNO"=:B1 START WITH"EMPNO"=7698 CONNECT BY "MGR"=PRIOR "EMPNO"))3 - filter("EMP"."DEPTNO"=:B1)4 - access("MGR"=PRIOR "EMPNO")filter("EMPNO"=7698)
为什么 exists/not exists 容易产生 FILTER,而 in 很少会产生 FILTER 呢?当子查询中有固化关键字(union/union all/start with connect by/rownum/cube/rollup),子查询会被固化为一个整体,采用 exists/not exists 这种写法,这时子查询中有主表连接列,只能是主表通过连接列传值给子表,所以 CBO 只能选择 FILTER。而我们如果将 SQL 改写为 in/not in 这种写法,子查询虽然被固化为整体,但是子查询中没有主表连接列字段,这个时候 CBO 就不会选择 FILTER。
START WITH CONNECT BY
SELECT ... FROM +表名 WHERE + 条件3 START WITH + 条件1 CONNECT BY PRIOR + 条件2
条件1表示我数据的切入点,也就是我第一条数据从哪里开始.
条件2是连接条件,其中用PRIOR表示上一条记录,例如CONNECT BY PRIOR ID = PID,意思就是上一条记录的ID是本条记录的PID
条件3表示条件12执行遍历结果之后再进行条件约束.
首先 我们查询所有表示这样的,
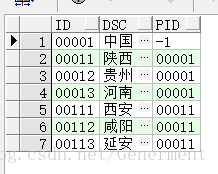
SELECT * FROM start_demo start with id = '00001' Connect By Prior id = pid
start with id = ‘00001’ 表示切入点,也就是我的第一条数据
Connect By Prior id = pid 表示我的上一条数据的id是我当前数据的pid(如果不是就表明不是当前节点)
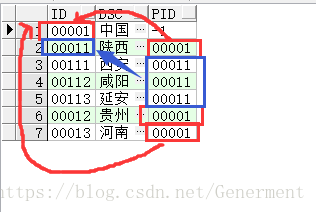
反之
SELECT * FROM start_demo start with id = '00113' Connect By Prior PID = id ---上一条记录的PID是本条记录的ID


若有收获,就点个赞吧
0 人点赞
