某沙发厂 ERP 系统出现大量 read by other session 等待,前台用户卡了一天。数据库版本是 Oracle11gR2,请求协助优化。利用脚本抓出系统当前正在运行的 SQL,如图 9-1 所示。
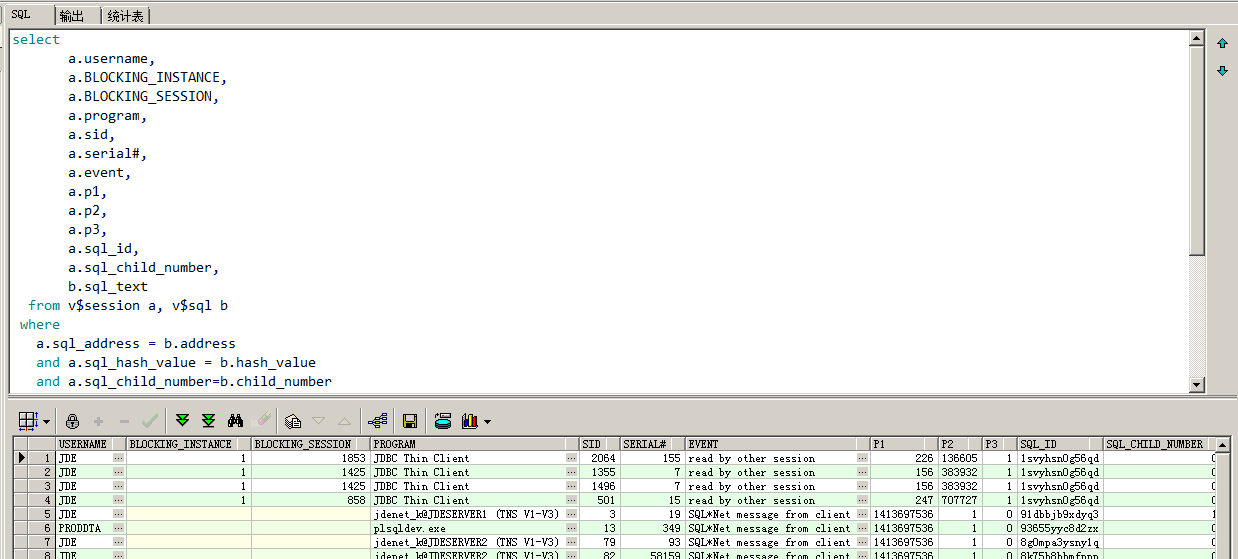
图 9-1
从上面查询中我们可以看到,同时运行 SQL:1svyhsn0g56qd,会引发 read by other session 等待,于是从共享池中抓出该 SQL 的执行计划,如图 9-2 所示。
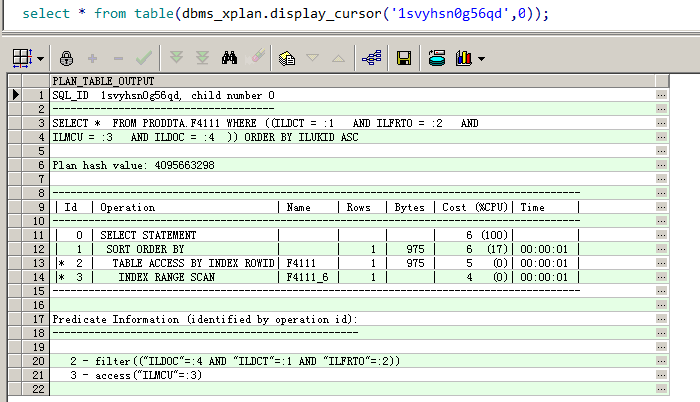
图 9-2
SQL 文本如下。
SELECT *FROM PRODDTA.F4111WHERE ((ILDCT = :1 AND ILFRTO = :2 AND ILMCU = :3 AND ILDOC = :4))ORDER BY ILUKID ASC
从执行计划中 Id=3 我们可以看到,该 SQL 走的是 ILMCU 这个列的索引。如图 9-3 所示,表中一共有 2 510 970 行数据。
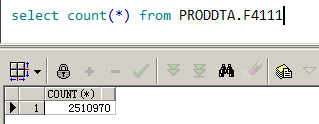
图 9-3
ILMCU 列的数据分布如下,如图 9-4 所示。
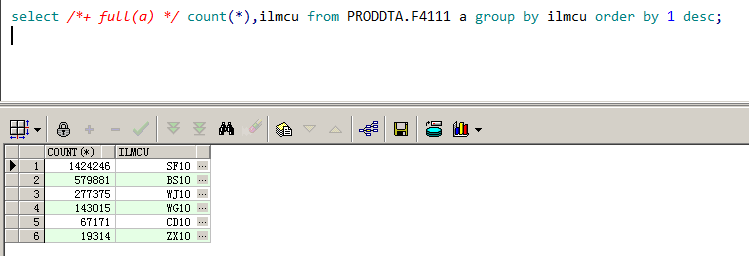
图 9-4
ILMCU 列的数据分布极不均衡。当询问当天做的是不是 SF10 的业务时,朋友确认是做的 SF10 的业务。这就不难解释为什么前台用户抱怨卡了一天。从 2 510 970 条数据中查询 1 424 246 条数据还走索引,这明显大错特错。这个错误的执行计划会导致产生大量的单块读,因为 SQL 执行缓慢,某些耐不住性子的用户可能会多次点击或刷新前台,并且因为做的是 SF10 的业务,前台操作人员可能多达几十位。正是因为有很多人在同时运行该 SQL,而且该 SQL 跑得很慢,又是单块读,所以就发生了多个进程需要同时读取同一个块的情况,这就是产生 read by other session 的原因。
该 SQL 一共有 4 个过滤条件,下面我们分别查看剩余 3 个过滤条件的数据分布,如图 9-5、图 9-6、图 9-7 所示。
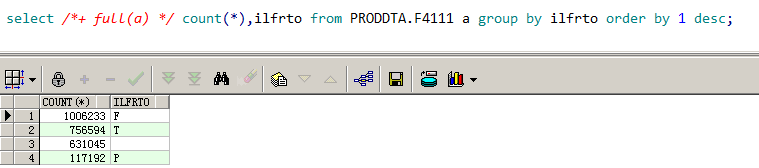
图 9-5
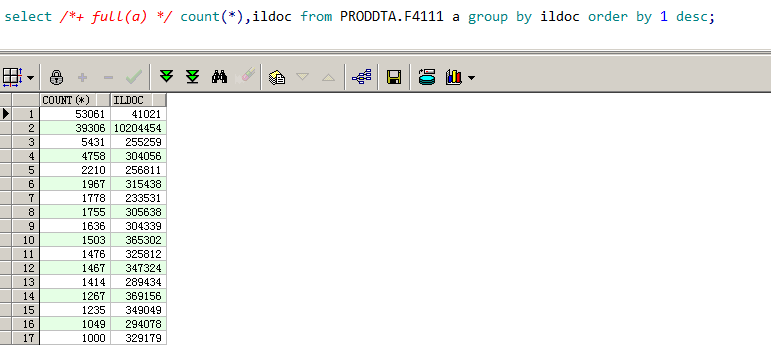
图 9-6
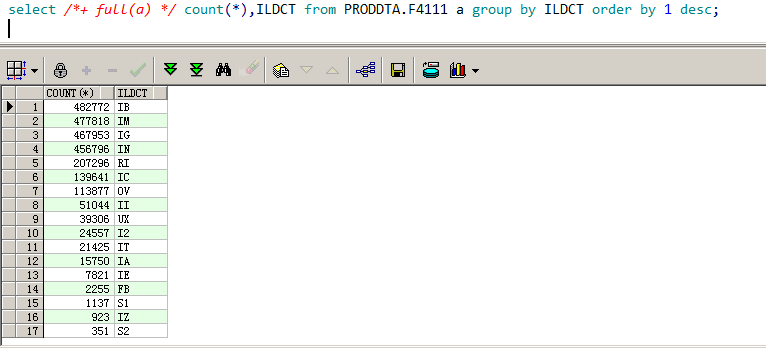
图 9-7
根据以上查询结果,我们发现,ILDOC 列的数据分布最为均匀,ILDCT 列的数据分布次之,ILMCU 列的数据分布倒数第二,ILFRTO 列的数据分布最不均衡。因为 SQL 都是根据这些列进行等值过滤,于是按分布均匀性建立如下组合索引。
create index idx_F4111_docdctilmcufrto on F4111(ILDOC,ILDCT,ILMCU,ILFRTO) online nologging;
创建完索引之后,系统中的 read other session 等待陆续消失,系统立刻恢复正常,前台用户原本执行了一天还没完成的业务现在可以瞬间完成。
为什么在查询 ILMCU 列的数据分布的时候会使用 HINT:FULL 呢?这是因为原本的 SQL 走该列的索引已经执行不出结果,如果不加 HINT,万一 SQL 查询又使用了该索引,这不是火上浇油吗?至于后面的 HINT,其一是因为复制粘贴,其二是因为表已经全表扫描过了,后面的全表扫描可以直接从 buffer cache 获取数据。
虽然通过创建组合索引优化了该 SQL,但是,在创建组合索引之前,如果优化器能够准确地知道 ILMCU 列的数据分布,那么执行计划也不会走该列的索引而会走其他列的索引(如果存在索引),或者走全表扫描。即使该 SQL 走全表扫描,那也比走索引扫描好太多,至少不会被卡死,不会引发前台用户被卡一天,最多被卡一小会儿。为什么优化器选择了走该列的索引呢?请注意观察执行计划中的 Id=3,Rows=1,优化器认为走 ILMCU 列的索引只返回一行数据。很明显该表统计信息有问题,而且该列很可能没有收集直方图。大家特别是 DBA,一定要重视表的统计信息,另外也要牢牢掌握索引知识,理解透了,就能解决 80% 左右的关于 OLTP 的 SQL 性能问题。如果数据库系统不是 OLTP(联机事务处理过程) 系统,而是 ERP(业务协作管理系统) 系统,或者是 OLAP(联机分析处理OLAP) 中的报表系统、ETL (数据仓库)系统等,只吃透索引没太大帮助,必须精通阅读执行计划、SQL、各种 SQL 等价改写,熟悉分区,同时熟悉系统业务,这样才能游刃有余地进行 SQL 优化。

若有收获,就点个赞吧
0 人点赞
