1.bash
bash是什么
- bash是一个命令处理器,运行在文本窗口中,并能执行用户直接输入的命令
- bash还能从文件中读取Linux命令,称之为脚本
- bash支持通配符、管道、命令替换、条件判断等逻辑控制语句
bash特性
1.命令行展开
```shell [root@chaogelinux ~]# echo {tom,bob,chaoge,jerry} tom bob chaoge jerry
[root@chaogelinux ~]# echo chaoge{666,888} chaoge666 chaoge888
[root@chaogelinux ~]# echo chaoge{1..5} chaoge1 chaoge2 chaoge3 chaoge4 chaoge5
[root@chaogelinux ~]# echo chaoge{1..10..2} # 奇数创建 chaoge1 chaoge3 chaoge5 chaoge7 chaoge9
[root@chaogelinux ~]# echo chaoge{01..10..2} chaoge01 chaoge03 chaoge05 chaoge07 chaoge09
<a name="uWQx7"></a>#### 2.命令别名`alias,unalias`<a name="MpnaQ"></a>#### 3.命令历史```shellhistory!行号!! 上一次的命令
4.快捷键
ctrl + a 移动到行首ctrl + e 移动到行尾ctrl + u 删除光标之前的字符ctrl + k 删除光标之后的字符ctrl + l 清空屏幕终端内容,同于clear
5.补全命令
tab键
补全
$PATH中存在的命令
6.文件路径补全
2.基本正则与扩展正则表达式
由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于表示控制或通配的功能;
- grep:文本过滤工具,(模式:pattern)工具
- sed:stream editor,流编辑器;文本编辑工具
- awk:Linux的文本报告生成器(格式化文本),Linux上是gawk
1.基本正则表达式
| 符号 | 作用 | | —- | —- | | ^ | 尖角号,用于模式的最左侧,如 “^oldboy”,匹配以oldboy单词开头的行 | | $ | 美元符,用于模式的最右侧,如”oldboy$”,表示以oldboy单词结尾的行 | | ^$ | 组合符,表示空行 (以空开头、以空结尾,就是空行的意思) | | . | 匹配任意一个且只有一个字符,不能匹配空行 | | \ | 转义字符,让特殊含义的字符,现出原形,还原本意,例如\.代表小数点 | | | 匹配前一个字符(连续出现)0次或1次以上 ,重复0次代表空,即匹配所有内容 | | . | 组合符,匹配任意长度的任意字符 | | ^. | 组合符,匹配任意多个字符开头的内容 | | .$ | 组合符,匹配以任意多个字符结尾的内容 | | [abc] | 匹配[]集合内的任意一个字符,a或b或c,可以写[a-c] | | [^abc] | 匹配除了^后面的任意字符,a或b或c,^表示对[abc]的取反 | |BRE对应元字符有 ^$.[]*| 匹配完整的内容 | | <或> | 定位单词的左侧,和右侧,如 可以找出”The chao ge”,缺找不出”yuchao” |
2.扩展正则表达式
ERE在在BRE基础上,增加上 (){}?+| 等字符
扩展正则必须用 grep -E 才能生效
| 字符 | 作用 |
|---|---|
| + | 匹配前一个字符1次或多次,前面字符至少出现1次 |
| [:/]+ | 匹配括号内的”:”或者”/“字符1次或多次 |
| ? | 匹配前一个字符0次或1次,前面字符可有可无 |
| | | 表示或者,同时过滤多个字符串 |
| () | 分组过滤,被括起来的内容表示一个整体 |
| a{n,m} | 匹配前一个字符最少n次,最多m次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{n} | 匹配前一个字符正好n次 |
| a{,m} | 匹配前一个字符最多m次 |
3.Linux三剑客grep与正则表达式
grep
全拼:Global search REgular expression and Print out the line.作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
语法:
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
-i:ignorecase,忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v, --invert-match:显示不能被模式匹配到的行;
-E:支持使用扩展的正则表达式元字符;
-q, --quiet, --silent:静默模式,即不输出任何信息;
| 参数选项 | 解释说明 |
|---|---|
| -v | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配的行数 |
| -E | 使用egrep命令 |
| —color=auto | 为grep过滤结果添加颜色 |
| -w | 只匹配过滤的单词 |
| -o | 只输出匹配的内容 |
| -l | 只输出文件 |
# 案例
cat /etc/passwd > /tmp/test_grep.txt
#找出login有关行
grep "login" /tmp/test_grep.txt -n
#找出没有login的行
grep "login" /tmp/test_grep.txt -n -v
#忽略大小写,找出root有关行
grep "ROOT" /tmp/test_grep.txt -i
#同时过滤出root和sync有关行
grep -E "root|sync" /tmp/test_grep.txt --color=auto
#统计匹配结果的行数
grep "login" /tmp/test_grep.txt -c
#只输出匹配出的内容
grep "login" /tmp/test_grep.txt -n -o
#完整匹配,字符串精确匹配,整个单词
grep "oldboy" /tmp/test_grep.txt -w
#过滤掉空白和注释行
grep -Ev "^#|^$" /tmp/test_grep.txt
grep '^#' luffy.txt -v | grep '^$' -v
# 找出空行
grep '^$' luffy.txt -n
# 找出非空行
grep '^$' luffy.txt -n -v
^
# 找到所有M开头的行
# -i忽略大小写 -n 显示仪行号
[root@pylinux data]# grep -i -n "^m" luffy.txt
5:My qq is 877348180.
7:My name is chaoge.
$
# 找到所有以.结尾的
1.注意不加转义符的结果,正则里"."是匹配任意1个字符,grep把.当做正则处理了,因此把有数据的行找出来了,
[root@pylinux data]# grep -i -n ".$" luffy.txt
1:I am oldboy teacher
2:I teach linux.
3:I like python.
5:My qq is 877348180.
7:My name is chaoge.
9:Our school website is http://oldboyedu.com
2.加上转义符,当做普通的小数点过滤
[root@pylinux data]# grep -i -n "\.$" luffy.txt
2:I teach linux.
3:I like python.
5:My qq is 877348180.
7:My name is chaoge.
# 找到所有允许登录的用户,解释器是bin/bash的行
grep -n "/bin/bash$" pwd.txt
[root@pylinux data]# grep -i -n "r$" luffy.txt
1:I am oldboy teacher
注意在Linux平台下,所有文件的结尾都有一个$符可以用cat -A 查看文件
^$
1.找出文件的空行,以及行号
[root@pylinux data]# grep "^$" luffy.txt -n
4:
6:
8:
10:
11:
.
# "."点表示任意一个字符,有且只有一个,不包含空行
[root@pylinux data]# grep -i -n "." luffy.txt
1:I am oldboy teacher
2:I teach linux.
3:I like python.
5:My qq is 877348180.
7:My name is chaoge.
9:Our school website is http://oldboyedu.com
# 匹配出 ".ac",找出任意一个三位字符,包含ac
[root@pylinux data]# grep -i -n ".ac" luffy.txt
1:I am oldboy teacher
2:I teach linux.
*
# 找出前一个字符0次或多次,找出文中出现"i"的0次或多次
[root@pylinux data]# grep -n "i*" luffy.txt
1:I am oldboy teacher
2:I teach linux.
3:I like python.
4:
5:My qq is 877348180.
6:
7:My name is chaoge.
8:
9:Our school website is http://oldboyedu.com
10:
11:
12:
.*
.表示任意一个字符,*表示匹配前一个字符0次或多次,因此放一起,代表匹配所有内容,以及空格
[]
中括号表达式,[abc]表示匹配中括号中任意一个字符,a或b或c,常见形式如下
- [a-z]匹配所有小写单个字母
- [A-Z]匹配所有单个大写字母
- [a-zA-Z]匹配所有的单个大小写字母
- [0-9]匹配所有单个数字
- [a-zA-Z0-9]匹配所有数字和字母
# 找到所有的小写字母 [root@pylinux data]# grep '[a-z]' luffy.txt I am oldboy teacher I teach linux. I like python. My qq is 877348180. My name is chaoge. Our school website is http://oldboyedu.com[^abc]中括号中取反
[^abc]或[^a-c]这样的命令,”^”符号在中括号中第一位表示排除,就是排除字母a或b或c
扩展
此处使用grep -E进行实践扩展正则,egrep官网已经弃用
+

?
匹配0次或一次
[root@pylinux data]# grep -E 'go?d' luffycity.txt
god #字母o出现了一次
gd #字母o出现了0次
|
# 找出系统中的txt文件,且名字里包含a或b的字符
[root@pylinux data]# find / -maxdepth 3 -name "*.txt" |grep -i -E "a|b"
/data/luffycity.txt
/data/luffy.txt
/test_find/chaoge.txt
/test_find/alex.txt
/opt/all.txt
/opt/_book/123.txt
/opt/Python-3.7.3/pybuilddir.txt
/opt/alltxt.txt
/opt/s15oldboy/qiong.txt
/opt/IIS/keystorePass.txt

()
将一个或多个字符捆绑在一起,当作一个整体进行处理;
- 小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
- 括号()内的内容可以被后面的”\n”正则引用,n为数字,表示引用第几个括号的内容
[root@pylinux data]# grep -E ‘good|glad’ luffycity.txt #我们希望能够实现这这样的匹配 good glad
[root@pylinux data]# grep -E ‘g(oo|la)d’ luffycity.txt good glad

<a name="v5mfG"></a>
### {n,m}匹配次数
重复前一个字符各种次数,可以通过-o参数显示明确的匹配过程<br />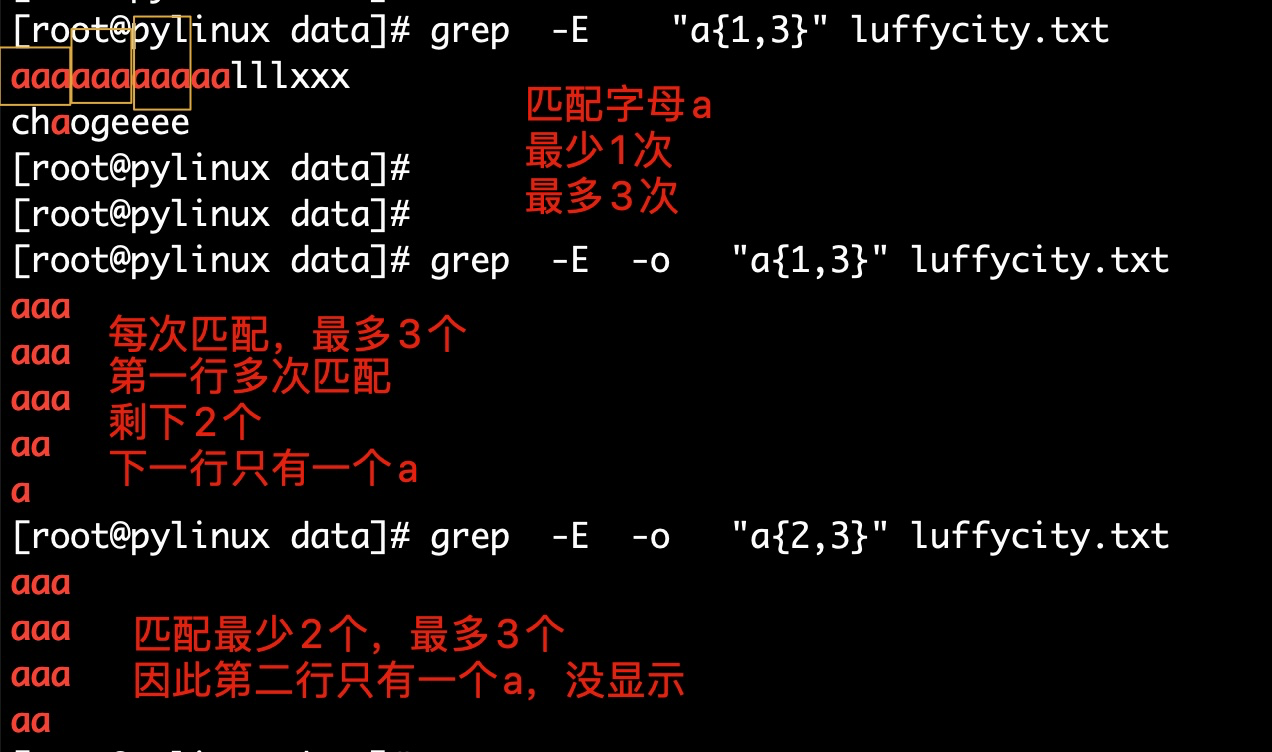<br />
<a name="Vz11a"></a>
#### 分组之后向后引用
```shell
[root@chaogelinux data]# cat lovers.txt
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.
[root@chaogelinux data]# grep -E '(l..e).*\1' lovers.txt
I love my lover.
He love his lovers.
[root@chaogelinux data]# grep -E '(r..t).*\1' /etc/passwd #案例2
root:x:0:0:root:/root:/bin/bash
4.Linux三剑客sed
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具。
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。
语法
sed [选项] [sed内置命令字符] [输入文件]
sed参数
| 参数选项 | 解释 |
|---|---|
| -n | 取消默认sed的输出,常与sed内置命令p一起用 |
| -i | 不用-i,sed修改的是内存数据 用-i 直接将修改结果写入文件, |
| -e | 多次编辑,不需要管道符了 |
| -r | 支持正则扩展 |
| sed的内置命令字符 | 解释 |
|---|---|
| a | append,对文本追加,在指定行后面添加一行/多行文本 |
| d | Delete,删除匹配行 |
| i | insert,表示插入文本,在指定行前添加一行/多行文本 |
| p | Print ,打印匹配行的内容,通常p与-n一起用 |
| s/正则/替换内容/g | 匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配 |
| 范围 | 解释 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
| /pattern/ | 被模式匹配到的每一行 |
| 范围区间 | 10,20 十到二十行,10,+5第10行向下5行,/pattern1/,/pattern2/ |
| 步长 | 1~2,表示1、3、5、7、9行,2~2两个步长,表示2、4、6、8、10、偶数行 |
案例
[root@pylinux data]# cat -n luffycity.txt
1 My name is chaoge.
2 I teach linux.
3 I like play computer game.
4 My qq is 877348180.
5 My website is http://pythonav.cn.
1.输出文件第2,3行的内容
# p代表打印 -n取消默认输出
[root@pylinux data]# sed -n '2,3p' luffycity.txt
I teach linux.
I like play computer game.
2.过滤出含有linux的字符串行
#sed可以实现grep的过滤效果,必须把要过滤的内容放在双斜杠中
[root@pylinux data]# sed -n '/linux/p' luffycity.txt
I teach linux.
3.删除含有game的行
[root@pylinux data]# sed '/game/d' luffycity.txt
My name is chaoge.
I teach linux.
My qq is 877348180.
My website is http://pythonav.cn.
[root@pylinux data]# sed -i '/game/d' luffycity.txt #不会输出结果,直接写入文件
删除第5行到结尾
[root@pylinux data]# sed '5,$d' luffycity.txt
My name is chaoge.
----------
I teach linux.
----------
4.将文件中的My全部替换为His
sed "s/找到的内容/替换后的内容/g"
[root@pylinux data]# sed 's/My/His/g' luffycity.txt
His name is chaoge.
I teach linux.
I like play computer game.
His qq is 877348180.
His website is http://pythonav.cn.
5.替换所有My为His,同时换掉QQ号为8888888
[root@pylinux data]# sed -e 's/My/His/g' -e 's/877348180/88888/g' luffycity.txt
His name is chaoge.
I teach linux.
I like play computer game.
His qq is 88888.
His website is http://pythonav.cn.
6.在文件第二行追加内容 a字符功能,写入到文件,还得添加 -i
[root@pylinux data]# sed -i '2a I am useing sed command' luffycity.txt
My name is chaoge.
I teach linux.
I am useing sed command
I like play computer game.
My qq is 877348180.
My website is http://pythonav.cn.
添加多行信息,用换行符”\n”
[root@pylinux data]# sed -i "3a i like linux very much.\nand you?" luffycity.txt
[root@pylinux data]#
[root@pylinux data]# cat -n luffycity.txt
1 My name is chaoge.
2 I teach linux.
3 I am useing sed command
4 i like linux very much.
5 and you?
6 I like play computer game.
7 My qq is 877348180.
8 My website is http://pythonav.cn.
在每一行下面插入新内容
[root@pylinux data]# sed "a ----------" luffycity.txt
My name is chaoge.
----------
I teach linux.
----------
I am useing sed command
----------
i like linux very much.
----------
and you?
----------
I like play computer game.
----------
My qq is 877348180.
----------
My website is http://pythonav.cn.
----------
7.在第二行上面插入内容
[root@pylinux data]# sed '2i i am 27' luffycity.txt
My name is chaoge.
i am 27
----------
I teach linux.
----------
I am useing sed command
----------
i like linux very much.
----------
and you?
----------
I like play computer game.
----------
My qq is 877348180.
----------
My website is http://pythonav.cn.
----------
sed实战
1.删除网卡信息
ifconfig eth0 | sed "2p" -n | sed "s/^.*inet//" | sed "s/net.*$//"
思路:
1.首先取出第二行
[root@pylinux ~]# ifconfig | sed -n '2p'
inet 10.141.32.137 netmask 255.255.192.0 broadcast 10.141.63.255
2.找到第二行后,去掉ip之前的内容
[root@pylinux ~]# ifconfig eth0|sed -n '2s#^.*inet##gp'
10.141.32.137 netmask 255.255.192.0 broadcast 10.141.63.255
解释:
-n是取消默认输出
2s是处理第二行内容
#^.*inet## 是匹配inet前所有的内容
gp代表全局替换且打印替换结果
3.再次处理,去掉ip后面的内容
[root@pylinux tmp]# sed -n '2s/^.*inet//gp' ip.txt | sed -n 's/net.*$//gp'
10.141.32.137
解释:
net.*$ 匹配net到结尾的内容
s/net.*$//gp #把匹配到的内容替换为空
ifconfig eth0 | sed -e "2s/^.*inet//" -e "2s/net.*$//p" -n
[root@pylinux tmp]# ifconfig eth0 | sed -ne '2s/^.*inet//g' -e '2s/net.*$//gp'
10.141.32.137
5.Linux三剑客awk
awk文本格式化
- grep,擅长单纯的查找或匹配文本内容
- sed,更适合编辑、处理匹配到的文本内容
- awk,更适合格式化文本内容,对文本进行复杂处理
语法
awk [option] 'pattern[action]' file ...
awk 参数 '条件动作' 文件

Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是print和printf
执行的命令是awk ‘{print $2}’,没有使用参数和模式,$2表示输出文本的第二列信息
awk默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符
awk是按行处理文件,一行处理完毕,处理下一行,根据用户指定的分割符去工作,没有指定则默认空格
- $0表示整行
- $NF表示当前分割后的最后一列
- 倒数第二列可以写成$(NF-1)
awk内置变量
| 内置变量 | 解释 | | —- | —- | | $n | 指定分隔符后,当前记录的第n个字段 | | $0 | 完整的输入记录 | | FS | 字段分隔符,默认是空格 | | NF(Number of fields) | 分割后,当前行一共有多少个字段 | | NR(Number of records) | 当前记录数,行数 | | 更多内置变量可以man手册查看 | man awk |
一次性输出多列

自动定义输出内容
awk,必须外层单引号,内层双引号
内置变量$1、$2都不得添加双引号,否则会识别为文本,尽量别加引号
[root@pylinux tmp]# awk '{print "第一列",$1,"第二列",$2,"第三列",$3}' alex.txt
第一列 alex1 第二列 alex2 第三列 alex3
第一列 alex6 第二列 alex7 第三列 alex8
第一列 alex11 第二列 alex12 第三列 alex13
第一列 alex16 第二列 alex17 第三列 alex18
第一列 alex21 第二列 alex22 第三列 alex23
第一列 alex26 第二列 alex27 第三列 alex28
第一列 alex31 第二列 alex32 第三列 alex33
第一列 alex36 第二列 alex37 第三列 alex38
第一列 alex41 第二列 alex42 第三列 alex43
第一列 alex46 第二列 alex47 第三列 alex48
输出整行信息
[root@pylinux tmp]# awk '{print}' alex.txt #两种写法都可以
[root@pylinux tmp]# awk '{print $0}' alex.txt
awk参数
| 参数 | 解释 |
|---|---|
| -F | 指定分割字段符 |
| -v | 定义或修改一个awk内部的变量 |
| -f | 从脚本文件中读取awk命令 |
显示文件第五行
# NR在awk中表示行号,NR==5表示行号是5的那一行
# 注意一个等于号,是修改变量值的意思,两个等于号是关系运算符,是"等于"的意思
[root@pylinux tmp]# awk 'NR==5' pwd.txt
operator:x:11:0:operator:/root:/sbin/nologin
awk 'NR==5{print $0}' chaoge.txt # 输出第五行信息
awk 'NR==5,NR==6{print $0}' chaoge.txt # 输出第五行、第六行信息
显示文件2-5行
#告诉awk,我要看行号2到5的内容
[root@pylinux tmp]# awk 'NR==2,NR==5' pwd.txt
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
给每一行的内容添加行号
添加变量,NR等于行号,$0表示一整行的内容
{print }是awk的动作
[root@pylinux tmp]# awk '{print NR,$0}' alex.txt
1 alex1 alex2 alex3 alex4 alex5
2 alex6 alex7 alex8 alex9 alex10
3 alex11 alex12 alex13 alex14 alex15
4 alex16 alex17 alex18 alex19 alex20
5 alex21 alex22 alex23 alex24 alex25
6 alex26 alex27 alex28 alex29 alex30
7 alex31 alex32 alex33 alex34 alex35
8 alex36 alex37 alex38 alex39 alex40
9 alex41 alex42 alex43 alex44 alex45
10 alex46 alex47 alex48 alex49 alex50 alex51
显示pwd.txt文件的第一列,倒数第二和最后一列

awk分隔符
- 输入分隔符,awk默认是空格,空白字符,英文是field separator,变量名是FS
- 输出分隔符,output field separator,简称OFS
awk逐行处理文本的时候,以输入分割符为准,把文本切成多个片段,默认符号是空格
当我们处理特殊文件,没有空格的时候,可以自由指定分隔符特点
FS输入分隔符

# 除了使用-F选项,还可以使用变量的形式,指定分隔符,使用-v选项搭配,修改FS变量
# 效果与上图一摸一样
[root@pylinux tmp]# awk -v FS='#' '{print $1}' chaoge.txt
超哥c
超哥f
超哥i
超哥l
超哥o
超哥r
超哥u
超哥x
OFS输出分割符
通过OFS设置输出分割符,记住修改变量必须搭配选项 -v
[root@pylinux tmp]# cat chaoge.txt
超哥c#超哥d#超哥e
超哥f#超哥g#超哥h
超哥i#超哥j#超哥k
超哥l#超哥m#超哥n
超哥o#超哥p#超哥q
超哥r#超哥s#超哥t
超哥u#超哥v#超哥w
超哥x#超哥y#超哥z
[root@pylinux tmp]#
[root@pylinux tmp]#
[root@pylinux tmp]# awk -v FS='#' -v OFS='---' '{print $1,$3 }' chaoge.txt
超哥c---超哥e
超哥f---超哥h
超哥i---超哥k
超哥l---超哥n
超哥o---超哥q
超哥r---超哥t
超哥u---超哥w
超哥x---超哥z
[root@pylinux tmp]#
awk变量
awk参数
| 参数 | 解释 |
|---|---|
| -F | 指定分割字段符 |
| -v | 定义或修改一个awk内部的变量 |
| -f | 从脚本文件中读取awk命令 |
对于awk而言,变量分为
- 内置变量
- 自定义变量 | 内置变量 | 解释 | | —- | —- | | FS | 输入字段分隔符, 默认为空白字符 | | OFS | 输出字段分隔符, 默认为空白字符 | | RS | 输入记录分隔符(输入换行符), 指定输入时的换行符 | | ORS | 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 | | NF | NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量 | | NR | NR:行号,当前处理的文本行的行号。 | | FNR | FNR:各文件分别计数的行号 | | FILENAME | FILENAME:当前文件名 | | ARGC | ARGC:命令行参数的个数 | | ARGV | ARGV:数组,保存的是命令行所给定的各参数 |
内置变量
NR,NF、FNR
- awk的内置变量NR、NF是不用添加$符号的
而$0 $1 $2 $3 … 是需要添加$符号的
[root@pylinux tmp]# cat -n alex.txt 1 alex1 alex2 alex3 alex4 alex5 2 alex6 alex7 alex8 alex9 alex10 3 alex11 alex12 alex13 alex14 alex15 4 alex16 alex17 alex18 alex19 alex20 5 alex21 alex22 alex23 alex24 alex25 6 alex26 alex27 alex28 alex29 alex30 7 alex31 alex32 alex33 alex34 alex35 8 alex36 alex37 alex38 alex39 alex40 9 alex41 alex42 alex43 alex44 alex45 10 alex46 alex47 alex48 alex49 alex50 alex51 [root@pylinux tmp]# [root@pylinux tmp]# awk '{print NR,NF}' alex.txt 1 5 2 5 3 5 4 5 5 5 6 5 7 5 8 5 9 5 10 6输出每行行号,以及指定的列
[root@pylinux tmp]# awk '{print NR,$1,$5}' alex.txt 1 alex1 alex5 2 alex6 alex10 3 alex11 alex15 4 alex16 alex20 5 alex21 alex25 6 alex26 alex30 7 alex31 alex35 8 alex36 alex40 9 alex41 alex45 10 alex46 alex50处理多个文件显示行号
# 普通的NR变量,会将多个文件按照顺序排序 [root@pylinux tmp]# awk '{print NR,$0}' alex.txt pwd.txt#使用FNR变量,可以分别对文件行数计数 [root@pylinux tmp]# awk '{print FNR,$0}' alex.txt pwd.txt内置变量RS
内置变量ORS
ORS是输出分隔符的意思,awk默认认为,每一行结束了,就得添加回车换行符
ORS变量可以更改输出符awk -v ORS='@@@' '{print NR,$0}' chaoge.txt内置变量FILENAME
显示awk正在处理文件的名字
[root@pylinux tmp]# awk '{print FILENAME,FNR,$0}' chaoge.txt alex.txt chaoge.txt 1 超哥a 超哥b chaoge.txt 2 超哥c 超哥d 超哥e chaoge.txt 3 超哥f 超哥g 超哥h chaoge.txt 4 超哥i 超哥j 超哥k chaoge.txt 5 超哥l 超哥m 超哥n chaoge.txt 6 超哥o 超哥p 超哥q chaoge.txt 7 超哥r 超哥s 超哥t chaoge.txt 8 超哥u 超哥v 超哥w chaoge.txt 9 超哥x 超哥y 超哥z alex.txt 1 alex1 alex2 alex3 alex4 alex5 alex.txt 2 alex6 alex7 alex8 alex9 alex10 alex.txt 3 alex11 alex12 alex13 alex14 alex15 alex.txt 4 alex16 alex17 alex18 alex19 alex20变量ARGC、ARGV
ARGV表示的是一个数组,数组中保存的是命令行所给的参数
数组是一种数据类型,如同一个盒子
盒子有它的名字,且内部有N个小格子,标号从0开始
给一个盒子起名字叫做months,月份是1~12,那就如图所示
自定义变量
顾名思义,是我们自己定义变量
方法一,-v varName=value
- 方法二,在程序中直接定义




[root@pylinux tmp]# studyLinux="超哥讲的linux是真滴好,嘿嘿"
[root@pylinux tmp]#
[root@pylinux tmp]#
[root@pylinux tmp]# awk -v myVar=$studyLinux 'BEGIN{print myVar}' # -v是给awk定义变量
超哥讲的linux是真滴好,嘿嘿
awk格式化输出
awk格式化
前面我们接触到的awk的输出功能,是{print}的功能,只能对文本简单的输出,并不能美化或者修改格式
printf格式化输出
如果你学过C语言或是go语言,一定见识过printf()函数,能够对文本格式化输出
printf和print的区别
format的使用
要点:
1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
printf修饰符:
-: 左对齐;默认右对齐,
+:显示数值符号; printf "%+d"
- printf动作默认不会添加换行符
- print默认添加空格换行符 ```shell [root@pylinux tmp]# awk ‘{print $1}’ 超哥nb.txt 超哥nb1 超哥nb4 超哥nb7 超哥nb10
[root@pylinux tmp]# awk ‘{print $1}’ 超哥nb.txt 超哥nb1 超哥nb4 超哥nb7 超哥nb10 [root@pylinux tmp]# [root@pylinux tmp]# awk ‘{printf $1}’ 超哥nb.txt 超哥nb1超哥nb4超哥nb7超哥nb10[root@pylinux tmp]#
给printf添加格式
- 格式化字符串 %s 代表字符串的意思
```shell
[root@pylinux tmp]# awk '{printf "%s\n",$1}' 超哥nb.txt
超哥nb1
超哥nb4
超哥nb7
超哥nb10
案例
- awk通过空格切割文档
- printf动作对数据格式化

awk -F ":" 'BEGIN{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户使用的解释器"} {printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %s\n",$1,$2,$3,$4,$5,$6,$7}' pwd.txt
参数解释
'BEGIN{printf "格式替换符 格式替换符2","变量1","变量2"}' 执行BEGIN模式
%s是格式替换符 ,替换字符串
%s\t 格式化字符串后,添加制表符,四个空格
%-25s 已然是格式化字符串, - 代表左对齐 ,25个字符长度
awk模式pattern
awk是按行处理文本,刚才讲解了print动作,现在讲解特殊的pattern:BEGIN和END
- BEGIN模式是处理文本之前需要执行的操作
- END模式是处理完所有行之后执行的操作 ```shell [root@pylinux tmp]# awk ‘BEGIN{print “超哥教你学awk”}’ 超哥教你学awk
上述操作没有指定任何文件作为数据源,而是awk首选会执行BEGIN模式指定的print操作,打印出如上结果,然后发现没有任何文件需要操作,就结束了
```shell
[root@pylinux tmp]# awk 'BEGIN{print "超哥带你学awk"}{print $1}' alex.txt
超哥带你学awk
alex1
alex6
alex11
alex16
alex21
alex26
alex31
alex36
alex41
alex46

- 再次总结,BEGIN就是处理文本前,先执行BEGIN模式指定的动作
- 再来看END的作用(awk处理完所有指定的文本后,需要执行的动作)

awk的模式
| 关系运算符 | 解释 | 示例 |
|---|---|---|
| < | 小于 | x<y |
| <= | 小于等于 | x<=y |
| == | 等于 | x==y |
| != | 不等于 | x!=y |
| >= | 大于等于 | x>=y |
| > | 大于 | x>y |
| ~ | 匹配正则 | x~/正则/ |
| !~ | 不匹配正则 | x!~/正则/ |
awk基础总结
空模式,没有指定任何的模式(条件),因此每一行都执行了对应的动作,空模式会匹配文档的每一行,每一行都满足了(空模式)
[root@pylinux tmp]# awk '{print $1}' alex.txt alex1 alex6 alex11 alex16 alex21 alex26 alex31 alex36 alex41 alex46关系运算符模式,awk默认执行打印输出动作
[root@pylinux tmp]# awk 'NR==2,NR==5' alex.txt alex6 alex7 alex8 alex9 alex10 alex11 alex12 alex13 alex14 alex15 alex16 alex17 alex18 alex19 alex20 alex21 alex22 alex23 alex24 alex25BEGIN/END模式(条件设置)

awk与正则表达式
正则表达式主要与awk的pattern模式(条件)结合使用
- 不指定模式,awk每一行都会执行对应的动作
- 指定了模式,只有被模式匹配到的、符合条件的行才会执行动作
找出pwd.txt中有以games开头的行1.用grep过滤
[root@pylinux tmp]# cat -n pwd.txt
1 sync:x:5:0:sync:/sbin:/bin/sync
2 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
3 halt:x:7:0:halt:/sbin:/sbin/halt
4 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
5 operator:x:11:0:operator:/root:/sbin/nologin
6 games:x:12:100:games:/usr/games:/sbin/nologin
7 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
8 nobody:x:99:99:Nobody:/:/sbin/nologin
9 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
10 dbus:x:81:81:System message bus:/:/sbin/nologin
11 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
12 libstoragemgmt:x:998:997:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
13 rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
14 ntp:x:38:38::/etc/ntp:/sbin/nologin
[root@pylinux tmp]# grep '^games' pwd.txt
games:x:12:100:games:/usr/games:/sbin/nologin
2.awk过滤
[root@pylinux tmp]# awk '/^games/{print $0}' pwd.txt
games:x:12:100:games:/usr/games:/sbin/nologin
#省略写法
[root@pylinux tmp]# awk '/^games/' pwd.txt
games:x:12:100:games:/usr/games:/sbin/nologin


awk命令执行流程
解读需求:从pwd.txt文件中,寻找我们想要的信息,按照以下顺序执行awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
- 优先执行BEGIN{}模式中的语句
- 从pwd.txt文件中读取第一行,然后执行pattern{commands}进行正则匹配/^n/ 寻找n开头的行,找到了执行{print} 进行打印
- 当awk读取到文件数据流的结尾时,会执行END{commands}
找出pwd.txt文件中禁止登录的用户(/sbin/nologin)
正则表达式中如果出现了 “/“则需要进行转义
找出pwd.txt文件中禁止登录的用户(/sbin/nologin)
1.用grep找出grep '/sbin/nologin$' pwd.txt
2.awk用正则得用双斜杠/正则表达式/[root@pylinux tmp]# awk '/\/sbin\/nologin$/{print $0}' pwd.txt
找出文件的区间内容
1.找出mail用户到nobody用户之间的内容
[root@pylinux tmp]# awk '/^mail/,/^nobody/ {print $0}' pwd.txt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
awk企业实战nginx日志
Access.log
39.96.187.239 - - [11/Nov/2019:10:08:01 +0800] "GET / HTTP/1.1" 302 0 "-" "Zabbix"
211.162.238.91 - - [11/Nov/2019:10:08:02 +0800] "GET /api/v1/course_sub/category/list/?belong=1 HTTP/1.1" 200 363 "https://www.luffycity.com/free" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
211.162.238.91 - - [11/Nov/2019:10:08:02 +0800] "GET /api/v1/degree_course/ HTTP/1.1" 200 370 "https://www.luffycity.com/free" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
统计日志的访客ip数量
#sort -n 数字从大到小排序
#wc -l 统计行数,也就是ip的条目数
[root@pylinux tmp]# awk '{print $1}' 500access.log |sort -n|uniq|wc -l
75
查看访问最频繁的前10个ip
#uniq -c 去重显示次数
#sort -n 从大到小排序
1.先找出所有ip排序,排序,然后去重统计出现次数
awk '{print $1}' 500access.log |sort -n |uniq -c
2.再次从大到小排序,且显示前100个ip
[root@pylinux tmp]# awk '{print $1}' 500access.log |sort -n |uniq -c |sort -nr |head -10
32 113.225.0.211
22 119.123.30.32
21 116.30.195.155
20 122.71.65.73
18 163.142.211.160
16 39.96.187.239
16 124.200.147.165
16 101.249.53.64
14 120.228.193.218
14 113.68.155.221


若有收获,就点个赞吧
0 人点赞
