第一章
计算机硬件介绍
- 操作系统:程序员写出来的一个用于操控机器硬件的软件。
- 电脑就是一台计算机:计算机是能够接收用户输入的指令和资料,并且通过计算机的中央处理器进行数学和逻辑运算后,产出有用的信息,通过输出设备,给予展示。计算机一直在背后默默的执行被给予的任务。
第二章
Linux目录结构
Linux目录分割特点
- 第一个斜杠 路径的起点
- 第二个斜杠开始,目录之间的分隔符

Linux常见目录含义

可执行的二进制文件:ls命令等
经常变化的文件:/var/log日志等
/etc存放运维软件等
/boot系统启动时加载的文件
bin:只要发现目录中含有bin相关的字,说明这个文件夹里边存放可执行文件
/opt存放第三方软件等
etc重要配置文件
- /etc/sysconfig/network-scripts/ifcfg-ens33 网卡配置文件
- /etc/resolv.conf dns配置文件,提供域名解析服务
- /etc/hostname 主机名文件
- /etc/hosts 记录IP地址
- /etc/motd 开机显示信息文件
- /etc/os-release 机器版本号与信息文件
cd
. 当前目录.. 上一层目录- 前一个工作目录~ 当前【用户】所在的家目录/ 顶级根目录
ls
-a all 显示所有文件的内容,以及隐藏的
-l 详细的输出文件夹中的内容
-h 以人类可读的形式输出
--full-time 以完整的时间格式输出
-t 根据最后修改的时间排序文件
-F 能够在不同的文件结尾输出不同的特殊符号
/结尾是文件夹,*结尾是可执行文件,@结尾是软连接,普通文件类型结尾什么都没有
-d 显示文件夹本身的信息,不输出其中内部的内容
-r 逆转排序,
-S 大写的S,针对文件大小进行排序,默认是从大到小排序
-i 显示出文件的inode信息,文件的身份证号,存储了文件的元信息,大小、位置、权限等
命令: ls -la /
查看命令解释:man ls (Linux下的帮助指令)
结论:ls - list directory contens (列出目录内容)
ls -la / 以竖状格式化显示列出/目录所有内容
lrwxrwxrwx. 1 root root 7 Oct 3 02:33 bin -> usr/bin
第一个字符的含义:
- -:常规文件
- b:块特殊文件
- c:字符特殊文件
- C:高性能(”连续数据“)文件
- d:目录
- D:门(Solaris 2.5及以上版本)
- l:符号链接
- M:离线(”前已“)文件(Cray DMF)
- n:网络专用文件(HP-UX)
- p:FIFO(命名管道)
- P:断开(Solaros 10及以上)
- s:套接字
- ?:其他文件
- 第二个字符的含义:
- r:属主的读权限
- 第三个字符的含义:
- w:属主的写权限
- 第四个字符的含义:
- x:属主的执行权限
- S:设置了SUID,没有执行权限
- s:设置了SUID,具有执行权限
- 第五个字符的含义:
- r:属组的读权限
- 第六个字符的含义:
- w:属主的写权限
- 第七个字符的含义:
- x:属组执行权限
- S:设置了SGID,没有执行权限
- s:设置了SGID,具有执行权限
- 第八个字符的含义:
- r:其他人的读权限
- 第九个字符的含义:
- w:其他人的写权限
- 第十个字符的含义:
- x:其他人的执行权限
- T:设置了粘滞位,没有执行权限
- t:设置了粘滞位,具有执行权限
- 第十一个字符的含义:
- .:没有任何其他替代访问方法的SELinux安全上下文(没有设置ACL)
- +:具有任何其他组合访问方法的SELinux安全上下文(设置了ACL)
- 第十二个字符的含义:该文件的硬链接数量
- 第十三个字符的含义:该文件的属主
- 第十四个字符的含义:该文件的属组
- 第十五个字符的含义:该文件的大小
- 第十六到第十八个字符的含义:最后一次修改的时间
- 第十九个字符的含义:文件或目录的名称
- 第二十个字符的含义:链接符号
- 第二十一个字符的含义:链接文件的源文件
mkdir
mkdir {alex, mjj, peiqi, cunzhang} 创建了四个文件夹
-p 递归创建文件夹,创建多级目录
mkdir chaoge{1..100} 创建100个文件夹
touch
touch
有两个作用
- 创建普通文件,在Linux下,文件的后缀仅仅是一个名字,touch创建的都是普通文件
- 修改文件时间
-t 修改文件的时间 touch -t 10240606 mjj.exe 把时间改成10月24日06点06分
cp
1.复制普通文件
cp命令 想复制的文件 复制之后的文件名
2.复制普通文件,放入到另一个文件夹中
cp mjj.txt ./oldboy/ # 复制放入其他文件夹,保留源文件名
cp mjj.txt ./oldboy/mjj.txt2 # 复制文件放入其他文件夹,且改名
3.一次性复制多个文件,放入另一个文件夹中
cp mjj.exe mjj.gif ./mjj/
4.复制整个文件夹,必须加上-r参数
cp -r mjj mjj2
5.复制且保存文件属性不变 -p
6.复制的时候保持软连接 -d
7.覆盖文件前提示 -i
cp -i 文件1 文件2 # 如果文件2已经存在,则会覆盖,-i会让用户进行输入y确认覆盖
用法:cp [选项]... [-T] 源文件 目标文件
或:cp [选项]... 源文件... 目录
或:cp [选项]... -t 目录 源文件...
将源文件复制至目标文件,或将多个源文件复制至目标目录。
-r 递归式复制目录,即复制目录下的所有层级的子目录及文件 -p 复制的时候 保持属性不变
-d 复制的时候保持软连接(快捷方式)
-a 等于-pdr
-p 等于--preserve=模式,所有权,时间戳,复制文件时保持源文件的权限、时间属性
-i, --interactive 覆盖前询问提示

mv
1.移动文件到另一个文件夹
mv ./mjj.jj ./oldboy # 把当前的mjj.jj移动到oldboy文件夹中
2.移动多个文件,放到另一个文件夹中
mv luffy* ./oldboy/ # 将当前目录所有以luffy开头的文件,放到oldboy文件夹中
3.重命名的用法
mv 旧的文件名 新的文件名
4.覆盖前询问 -i
5.强制性覆盖 -f
rm
1.删除普通文件
rm 文件名
2.一次性删除多个文件
rm 文件名 文件名 # 删除多个文件,写入多个名字,空格分割就好
3.删除文件夹
rm -r 文件夹 # 删除文件夹及其里边的内容
4.删除空的文件夹
rm -d 空文件夹 # -d参数只能用来删除空文件夹
5.强制删除文件,且不提示
rm -f mjj* # 强制删除以mjj开头的文件,文件夹无法删除
6.强制删除所有的文件和文件夹
rm -f -r ./*
7.显示删除的过程 -v
帮助命令
语法
man 命令
如:
man ls
进入man帮助文档后,按下q退出
语法:
命令 --help
帮助命令的精简版
如 ls --help
语法:
info 命令
开机关机
| 命令 | 说明 |
|---|---|
| shutdown -h now | 立刻关机,企业用法 |
| shutdown -h 1 | 1分钟后关机,也可以写时间如 11:30 |
| halt | 立刻关闭系统,需手工切断电源 |
| init 0 | 切换运行级别为0,0表示关机 |
| poweroff | 立刻关闭系统,且关闭电源 |
| 重启 | |
| reboot | 立刻重启机器,企业用法 |
| Shutdown -r now | 立刻重启,企业用法 |
| shutdown -r 1 | 一分钟后重启 |
| Init 6 | 切换运行级别为6,此级别是重启 |
| 注销命令 | |
| logout | 注销退出当前用户 |
| exit | 注销退出当前用户,快捷键ctrl + d |
Linux命令行快捷键
ctrl + c cancel取消当前操作
ctrl + l 清空屏幕内容
ctrl + d 退出当前用户
ctrl + a 光标移到行首
ctrl + e 光标移到行尾
ctrl + u 删除光标到行首的内容
Linux的环境变量
执行命令:
echo $PATH
echo命令是有打印的意思
$符号后面跟上PATH,表示输出PATH的变量,分割符是:号
查看在哪,用which which ls
vim
vi如同Windows的记事本 vim如同notepad++
vim使用流程
vim默认是不安装的,需要手动安装这个工具命令yum install vim -y # 通过yum软件管理工具,安装命令vim,默认是yse
当vim打开不存在的文件的时候,默认会创建这个文件
vim 文件名 # 打开文件- 输入
字母 i 进入编辑模式,代表insert字母 o 在光标下一行开始编辑
- 按下esc,退出编辑模式
- 输入冒号,进入底线命令模式
:wq! 强制写入退出vim:q! 不保存强制退出
- 冒号需要是英文输入法
vim快捷键
- 上下左右
h 向左 j 向下 k 向上 l 向右
- 移动光标
w 移动到下一个单词b 移动到上一个单词0 移动到行首$ 移动到行尾g 移动到文章的开头G 移动到文章的结尾H 移动到屏幕的开头L 移动到屏幕的结尾M 移动到屏幕的中间
- 命令模式的查找
向下查找 /查找的内容 按下n跳转到下一个单词向上查找 ?查找的内容 按下n查找下一个单词
- 命令模式下的粘贴,删除
yy 复制光标所在行4yy 复制4行的内容p 打印粘贴的内容dd 删除光标当前行D 删除光标当前位置到行尾的内容x 删除光标当前字符,向后删除X 删除光标当前字符,向前删除u 撤销上一步的动作
快捷操作
C 删除光标所在位置到行尾的内容,且进入编辑模式 o 在光标的下一行开始编辑 O 在光标的上一行开始编辑 A 快速进入行尾,且进入编辑模式 ZZ 快速保存退出批量快捷的操作 ```shell 快捷删除 输入 ctrl + v 进入可视块 用上下左右命令,选择操作的块 选中块后,输入d,删除块内容
快捷插入多行 选中块后,输入大写的I,进行写代码 按下esc两次,会自动生成多行代码
<a name="eJCbc"></a>
### vim交换文件解决方法
`vim -r .chaochao.txt.swp `<br />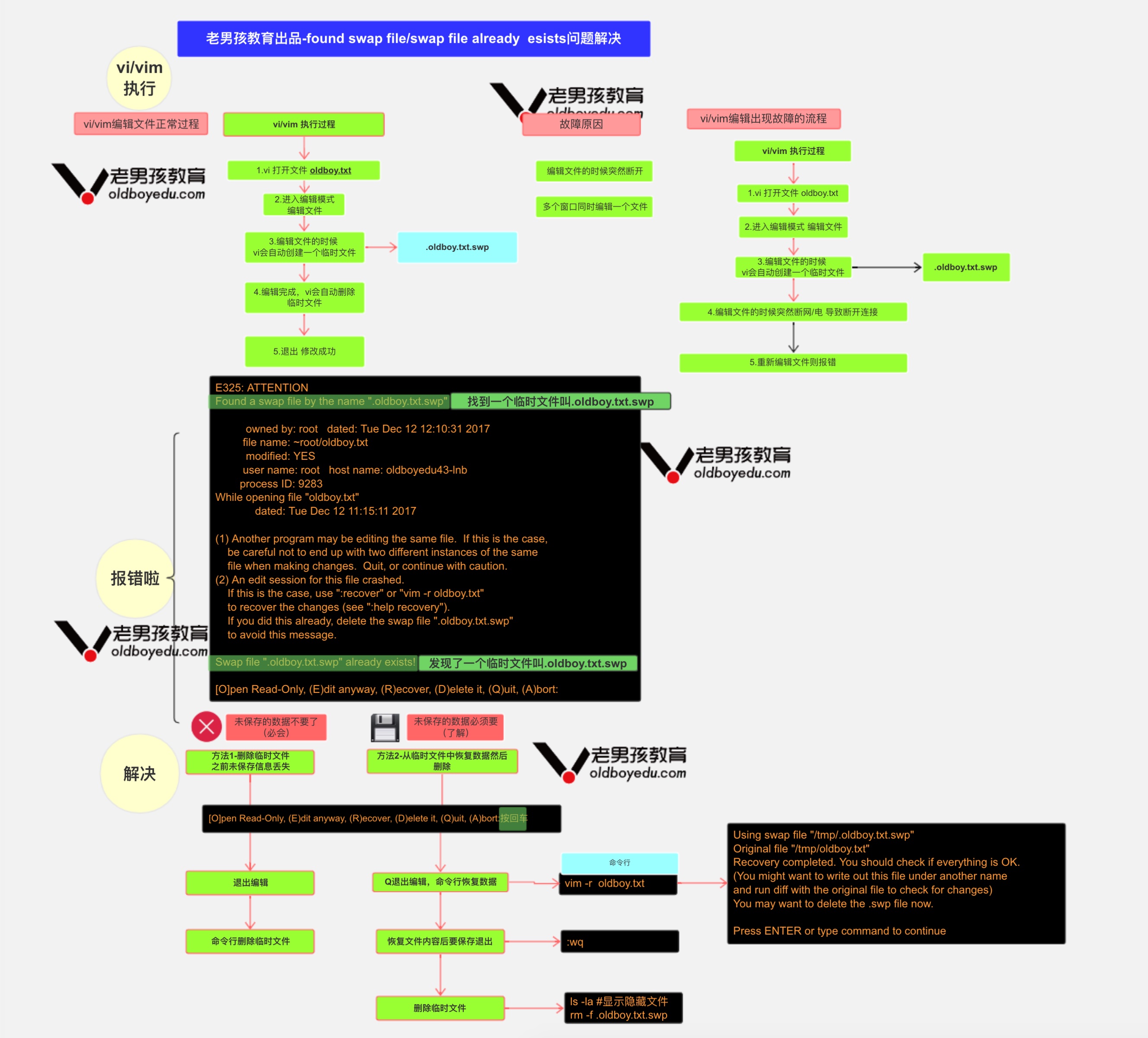
<a name="DTQ6h"></a>
### 重定向符号
1. 读取内容,写入到另一个文件中
`cat douyin.txt > kuaishou.txt`
2. 追加写入文件内容
`cat douyin.txt >> kuaishou.txt`
3. 重定向写入符
`cat < daouyin.txt # 把文件中的数据,发送给cat命令去读取 `<br />将文本内容拆分成多行<br />`xargs -n 4 < shuzi.txt # 把文本内容拆成多行 `
4. 重定追加写入符 <<
<a name="wUj7t"></a>
### cat命令
| **功能** | **说明** |
| --- | --- |
| 查看文件内容 | cat file.txt |
| 多个文件合并 | cat file.txt file2.txt > file3.tx |
| 非交互式编辑或追加内容 | cat >> file.txt << EOF<br />欢迎来到路飞学城<br />EOF |
| 清空文件内容 | cat /dev/null > file.txt 【/dev/null是linux系统的黑洞文件】 |
```shell
用法:cat [选项] [文件]...
将[文件]或标准输入组合输出到标准输出。
清空文件内容,慎用
> 文件名
-A, --show-all 等价于 -vET
-b, --number-nonblank 对非空输出行编号
-e 等价于 -vE
-E, --show-ends 在每行结束处显示 $
-n, --number 对输出的所有行编号
-s, --squeeze-blank 不输出多行空行
-t 与 -vT 等价
-T, --show-tabs 将跳格字符显示为 ^I
-u (被忽略)
-v, --show-nonprinting 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外
--help 显示此帮助信息并退出
--version 输出版本信息并退出
如果[文件]缺省,或者[文件]为 - ,则读取标准输入。
cat清空文件用法
- 直接清空文件
echo > gushi.txt # 只有一个空行
- 直接清空,不留空行
> gushi.txt
- 利用cat读取一个黑洞文件,然后清空其他文本
cat /dev/null > douyin2.txt
tac命令
与cat命令相反
管道符 |
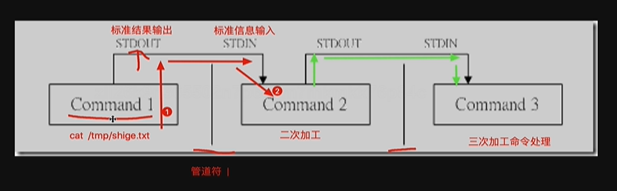
管道符用法
- 对字符串进行二次过滤
```shell
Linux提供的管道符“|”讲两条命令隔开,管道符左边命令的输出会作为管道符右边命令的输入。
常见用法:
检查python程序是否启动
ps -ef|grep “python”
找到/tmp目录下所有txt文件
ls /tmp|grep ‘.txt’
检查nginx的端口是否存活
netstat -tunlp |grep nginx
<a name="eS2jU"></a>
### grep 过滤字符串信息
<a name="ZHBlN"></a>
### more less
分屏查看大文本内容
```shell
语法
more 参数 文件
-num 指定屏幕显示大小为num行
+num 从num行开始显示
交互式more的命令:
空格 向下滚动一屏
Enter 向下显示一行
= 显示当前行号
q 退出
head
用法:head [选项]... [文件]...
将每个指定文件的头10 行显示到标准输出。
如果指定了多于一个文件,在每一段输出前会给出文件名作为文件头。
如果不指定文件,或者文件为"-",则从标准输入读取数据。
-c, --bytes=[-]K 显示每个文件的前K 字节内容;
如果附加"-"参数,则除了每个文件的最后K字节数据外
显示剩余全部内容
-n, --lines=[-]K 显示每个文件的前K 行内容;
如果附加"-"参数,则除了每个文件的最后K 行外显示
剩余全部内容
head -5 文件名 # 查看前5行内容
-q, --quiet, --silent 不显示包含给定文件名的文件头
-v, --verbose 总是显示包含给定文件名的文件头
--help 显示此帮助信息并退出
--version 显示版本信息并退出
tail
-c 数字 指定显示的字节数
-n 行数 显示指定的行数
-f 实时刷新文件变化
-F 等于 -f --retry 不断打开文件,与-f合用
--pid=进程号 进程结束后自动退出tail命令
-s 秒数 检测文件变化的间隔秒数
cut
语法
cut 参数 文件
-b 以字节为单位分割
-n 取消分割多字节字符,与-b一起用
-c 以字符为单位 截取每一行的第几个字符
cut -c -7 alex.txt
cut -c 8- alex.txt
cut -c 4-6 alex.txt
cut -c 4,6 zlex.txt
-d 自定义分隔符,默认以tab为分隔符
-f 与-d一起使用,指定显示哪个区域
cut -d ":" -f 7 password
cut -d ":" -f -4 password | head -n 5
N 第 N 个 字节, 字符 或 字段, 从 1 计数 起
N- 从 第 N 个 字节, 字符 或 字段 直至 行尾
N-M 从 第 N 到 第 M (并包括 第M) 个 字节, 字符 或 字段
-M 从 第 1 到 第 M (并包括 第M) 个 字节, 字符 或 字段
sort
用法:sort [选项]... [文件]...
或:sort [选项]... --files0-from=F
串联排序所有指定文件并将结果写到标准输出。
-b, --ignore-leading-blanks 忽略前导的空白区域
-n, --numeric-sort 根据字符串数值比较 默认是从小到大排序
-r, --reverse 逆序输出排序结果
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-k, --key=位置1[,位置2] 在位置1 开始一个key,在位置2 终止(默认为行尾)
sort -n -t "." -k 4 ip.txt
#sort 是默认以第一个数据来排序,而且默认是以字符串形式来排序,所以由字母 a 开始升序排序
[root@luffycity tmp]# cat /etc/passwd | sort
[root@luffycity tmp]# sort -n sort.txt #按照数字从大到小排序
[root@luffycity tmp]# sort -nr sort.txt #降序排序
[root@luffycity tmp]# sort -u sort.txt #去重排序
[root@luffycity tmp]# sort -t " " -k 2 sort.txt #指定分隔符,指定序列
10.0.0.15 a
10.0.0.12 e
10.0.0.22 e
10.0.0.54 f
10.0.0.34 q
10.0.0.63 q
10.0.0.3 r
10.0.0.34 r
10.0.0.4 v
10.0.0.44 w
10.0.0.5 x
[root@luffycity tmp]# cat /etc/passwd| sort -t ":" -k 3 #以分号分割,对第三列排序,以第一位数字排序
#以分号分割,对第一个区域的第2到3个字符排序
[root@luffycity tmp]# cat /etc/passwd | sort -t ":" -k 1.2,1.3
uniq
用法:uniq [选项]... [文件]
从输入文件或者标准输入中筛选相邻的匹配行并写入到输出文件或标准输出。
不附加任何选项时匹配行将在首次出现处被合并。
加上sort,去重更精准
sort -n luffy.txt | uniq
-c, --count 在每行前加上表示相应行目出现次数的前缀编号
-d, --repeated 只输出重复的行
-u, --unique 只显示出现过一次的行,注意了,uniq的只出现过一次,是针对-c统计之后的结果
sort -n luffy.txt | uniq -c -u
#测试数据文件
[root@luffycity tmp]# cat luffy.txt
10.0.0.1
10.0.0.1
10.0.0.51
10.0.0.51
10.0.0.1
10.0.0.1
10.0.0.51
10.0.0.31
10.0.0.21
10.0.0.2
10.0.0.12
10.0.0.2
10.0.0.5
10.0.0.5
10.0.0.5
10.0.0.5
[root@luffycity tmp]# uniq luffy.txt #仅仅在首次出现的时候合并,最好是排序后去重
10.0.0.1
10.0.0.51
10.0.0.1
10.0.0.51
10.0.0.31
10.0.0.21
10.0.0.2
10.0.0.12
10.0.0.2
10.0.0.5
[root@luffycity tmp]# sort luffy.txt |uniq -c #排序后去重且显示重复次数
4 10.0.0.1
1 10.0.0.12
2 10.0.0.2
1 10.0.0.21
1 10.0.0.31
4 10.0.0.5
3 10.0.0.51
[root@luffycity tmp]# sort luffy.txt |uniq -c -d #找出重复的行,且计算重复次数
4 10.0.0.1
2 10.0.0.2
4 10.0.0.5
3 10.0.0.51
[root@luffycity tmp]# sort luffy.txt |uniq -c -u #找到只出现一次的行
1 10.0.0.12
1 10.0.0.21
1 10.0.0.31
wc
-c, --bytes打印字节数
-m, --chars 打印字符数 (每一行结尾实际上是有$符号的)
-l, --lines 打印行数
wc -l luffy.txt
-L, --max-line-length 打印最长行的长度
-w, --words 打印单词数
[root@luffycity tmp]# wc -l luffy.txt #统计文本有多少行,如同cat -n 看到的行数
21 luffy.txt
#统计单词数量,以空格区分
[root@luffycity tmp]# echo "alex peiqi yuchao mjj cunzhang" | wc -w
5
[root@luffycity tmp]# echo "alex" |wc -m #统计字符数,由于结尾有个$
5
[root@luffycity tmp]# echo "alex" |cat -E #证明结尾有个$
alex$
[root@luffycity tmp]# wc -L alex.qq #统计最长的行,字符数
9 alex.qq
[root@luffycity tmp]# who|wc -l #当前机器有几个登录客户端
w
显示当前有几个人在登录这台机器
who
显示有几个终端
tr
用法:tr [选项]... SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
字符集1:指定要转换或删除的原字符集。
当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。
但执行删除操作时,不需要参数“字符集2”;
字符集2:指定要转换成的目标字符集。
替换标准输出中的大小写
echo "my name is alex" | tr '[a-z]' '[A-Z]'
tr 'a' 'A' < alex.txt
-c或——complerment:取代所有不属于第一字符集的字符;
-d或——delete:删除所有属于第一字符集的字符;
echo "my name is alex and i am 9999 years old" | tr -d 'a-z'
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
echo "iiii am aaaallllexxxx" | tr -s 'iax'
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
stat
stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细
-L, --dereference 跟随链接
-f, --file-system 显示文件系统状态而非文件状态
-c --format=格式 使用指定输出格式代替默认值,每用一次指定格式换一新行
--printf=格式 类似 --format,但是会解释反斜杠转义符,不使用换行作
输出结尾。如果您仍希望使用换行,可以在格式中
加入"\n"
-t, --terse 使用简洁格式输出
--help 显示此帮助信息并退出
--version 显示版本信息并退出
有效的文件格式序列(不使用 --file-system):
%a 八进制权限
find
find 查找目录和文件,语法:
find 路径 -命令参数 [输出形式]
参数说明:
路径:告诉find在哪儿去找你要的东西,
find . -maxdepth 1 ! -type d # 取反,不找文件夹
find . -path "./test_find" -prue -o -name "*.txt" -print # 不找test_find文件夹的内容
find . -type f -name "*.txt" -ok rm {} \;
| 参数 | 解释 |
|---|---|
| pathname | 要查找的路径 |
| options选项 | |
| -maxdepth | <目录层级>:设置最大目录层级; |
| -mindepth | <目录层级>:设置最小目录层级; |
| tests模块 | |
| -atime | 按照文件访问access的时间查找,单位是天 |
| -ctime | 按照文件的改变change状态来查找文件,单位是天 |
| -mtime | 根据文件修改modify时间查找文件【最常用】 |
| -name | 按照文件名字查找,支持* ? [] 通配符 |
| -group | 按照文件的所属组查找 |
| -perm | 按照文件的权限查找 |
| -size n[cwbkMG] | 按照文件的大小 为 n 个由后缀决定的数据块。 其中后缀为: b: 代表 512 位元组的区块(如果用户没有指定后缀,则默认为 b) c: 表示字节数 k: 表示 kilo bytes (1024字节) w: 字 (2字节) M:兆字节(1048576字节) G: 千兆字节 (1073741824字节) |
| -type 查找某一类型的文件 | b - 块设备文件。 d - 目录。 c - 字符设备文件。 p - 管道文件。 l - 符号链接文件。 f - 普通文件。 s - socket文件 |
| -user | 按照文件属主来查找文件。 |
| -path | 配合-prune参数排除指定目录 |
| Actions模块 | |
| -prune | 使find命令不在指定的目录寻找 |
| -delete | 删除找出的文件 |
| -exec 或-ok | 对匹配的文件执行相应shell命令 |
| 将匹配的结果标准输出 | |
| OPERATORS | |
| ! | 取反 |
| -a -o | 取交集、并集,作用类似&&和\ |
xargs
xargs 又称管道命令,构造参数等。
是给命令传递参数的一个过滤器,也是组合多个命令的一个工具它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理 。
简单的说就是把其他命令的给它的数据,传递给它后面的命令作为参数
-d 为输入指定一个定制的分割符,默认分隔符是空格
echo "akex,mjj,cunzhang,chaoge" | xargs -d "," -n 2
-i 用 {} 代替 传递的数据
find . -name "*txt" | xargs -i mv {} alltmptxt/
-I string 用string来代替传递的数据-n[数字] 设置每次传递几行数据
find . -name "*txt" | xargs -I alltxt mv alltxt ./
-n 选项限制单个命令行的参数个数
xargs -n 2 < chaoge.txt
-t 显示执行详情
-p 交互模式
-P n 允许的最大线程数量为n
-s[大小] 设置传递参数的最大字节数(小于131072字节)
-x 大于 -s 设置的最大长度结束 xargs命令执行
-0,--null项用null分隔,而不是空白,禁用引号和反斜杠处理
文件属性
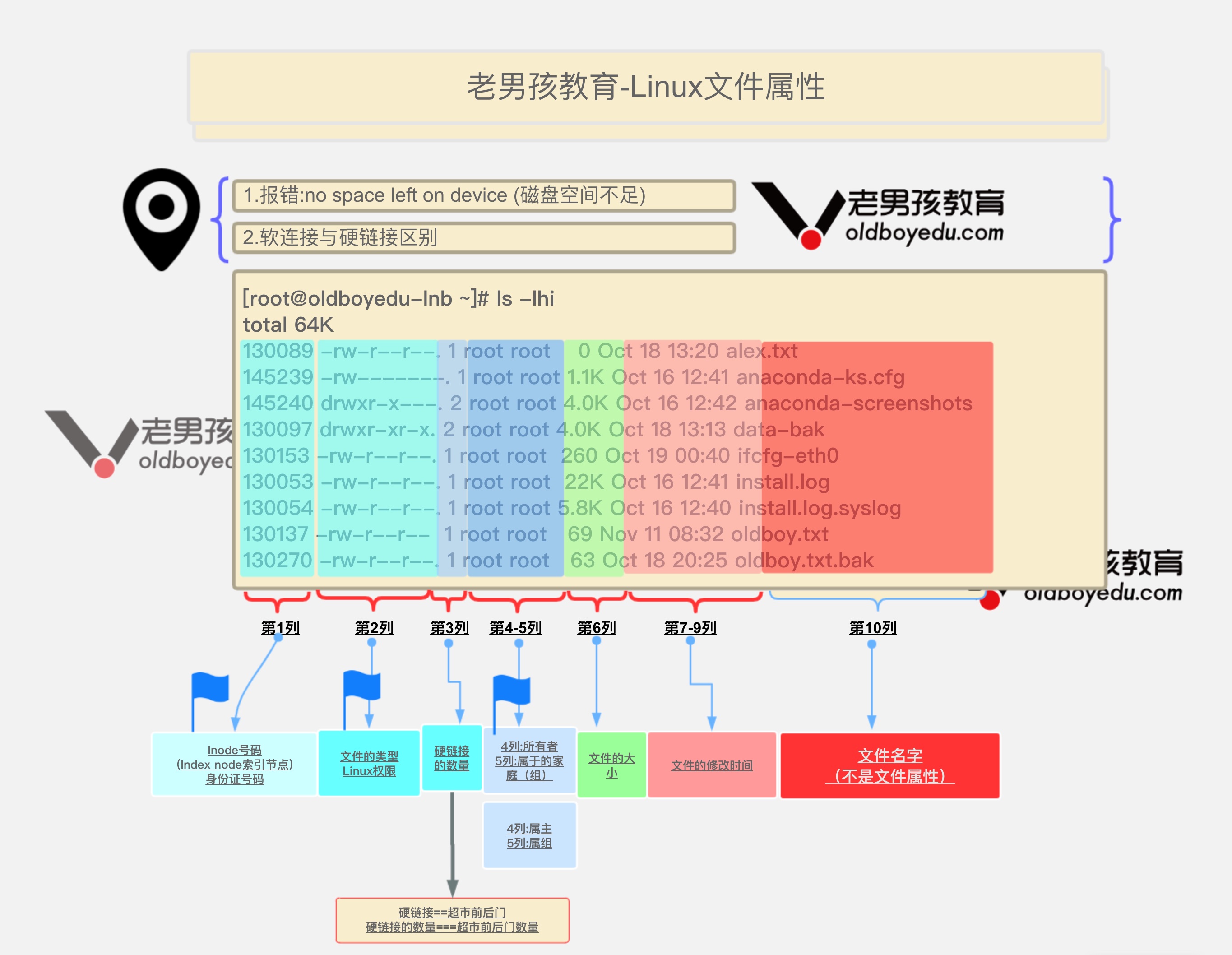
| 格式 | 类型 |
|---|---|
| ls -l看第一个字符 | |
| - | 普通文件regular file,(二进制,图片,日志,txt等) |
| d | 文件夹directory |
| b | 块设备文件,/dev/sda1,硬盘,光驱 |
| c | 设备文件,终端/dev/tty1,网络串口文件 |
| s | 套接字文件,进程间通信(socket)文件 |
| p | 管道文件pipe |
| l | 链接文件,link类型,快捷方式 |
file
[root@luffycity tmp]# file /usr/bin/python2.7 #二进制解释器类型
/usr/bin/python2.7: ELF 64-bit LSB executable
[root@luffycity tmp]# file /usr/bin/yum #yum是python的脚本文件
/usr/bin/yum: Python script, ASCII text executable
[root@luffycity tmp]# file /usr/bin/cd #shell脚本,内置命令
/usr/bin/cd: POSIX shell script, ASCII text executable
[root@luffycity tmp]# file hehe.txt #text类型
hehe.txt: ASCII text
[root@luffycity tmp]# file heihei #文件夹
heihei: directory
[root@luffycity tmp]# file /usr/bin/python2 #软链接类型
/usr/bin/python2: symbolic link to `python2.7'
tar
语法:
tar(选项)(参数)
-A或--catenate:新增文件到以存在的备份文件;
-B:设置区块大小;
-c或--create:建立新的备份文件;
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
-d:记录文件的差别;
-x或--extract或--get:从备份文件中还原文件;
-t或--list:列出备份文件的内容;
-z或--gzip或--ungzip:通过gzip指令处理备份文件;
-Z或--compress或--uncompress:通过compress指令处理备份文件;
-f<备份文件>或--file=<备份文件>:指定备份文件;
-v或--verbose:显示指令执行过程;
-r:添加文件到已经压缩的文件;
-u:添加改变了和现有的文件到已经存在的压缩文件;
-j:支持bzip2解压文件;
-v:显示操作过程;
-l:文件系统边界设置;
-k:保留原有文件不覆盖;
-m:保留文件不被覆盖;
-w:确认压缩文件的正确性;
-p或--same-permissions:用原来的文件权限还原文件;
-P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号;不建议使用
-N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;
--exclude=<范本样式>:排除符合范本样式的文件。
-h, --dereference跟踪符号链接;将它们所指向的文件归档并输出
- 对tmp下所有内容打包,生成alltmp.tar
tar -cvf alltmp.tar ./*
- 拆开备份文件,拆开快递
tar -xvf ../alltmp.tar ./
- 对tmp下所有文件进行打包且压缩,节省磁盘空间
tar -czvf alltmp2.tar.gz ./*
- 解压缩
tar -xzvf ../alltmp.tar.gz ./*
- 列出压缩文件中都有哪些内容
tar -ztvf alltmp2.tar.gz
- 单独的取出压缩文件中的内容
tar -zxvf alltmp2.tar.gz ./开心.txt
- 指定目录解压缩
tar -zxvf alltmp2.tar.gz -C ./alltmp/
- 排除文件解压缩
tar -zxvf ./alltmp2.tar.gz --exclude alex.txt
- tar命令压缩快捷方式的源文件,为不是压缩快捷方式
tar -zchf kx2.tar.gz ./kx.txt
gzip
gzip(选项)(参数)
-a或——ascii:使用ASCII文字模式;
-c或--stdout或--to-stdout 把解压后的文件输出到标准输出设备。
-d或--decompress或----uncompress:解开压缩文件;
-f或——force:强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接;
-h或——help:在线帮助;
-l或——list:列出压缩文件的相关信息;
-L或——license:显示版本与版权信息;
-n或--no-name:压缩文件时,不保存原来的文件名称及时间戳记;
-N或——name:压缩文件时,保存原来的文件名称及时间戳记;
-q或——quiet:不显示警告信息;
-r或——recursive:递归处理,将指定目录下的所有文件及子目录一并处理;
-S或<压缩字尾字符串>或----suffix<压缩字尾字符串>:更改压缩字尾字符串;
-t或——test:测试压缩文件是否正确无误;
-v或——verbose:显示指令执行过程;
-V或——version:显示版本信息;
-<压缩效率>:压缩效率是一个介于1~9的数值,预设值为“6”,指定愈大的数值,压缩效率就会愈高;
--best:此参数的效果和指定“-9”参数相同;
--fast:此参数的效果和指定“-1”参数相同。
笔记为本人在路飞学城教育课程学习中记录,如有侵权情况,及时联系本人,本人立刻删除。

若有收获,就点个赞吧
0 人点赞
