1、为什么要学习scrapy
![A42MT]1UJWZ93886.png](/uploads/projects/xiaobink@vbqyep/31390e0854bcb78eb2597dfaa5b6fcdc.png)
2、什么是Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取;
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
3、异步和非阻塞的区别
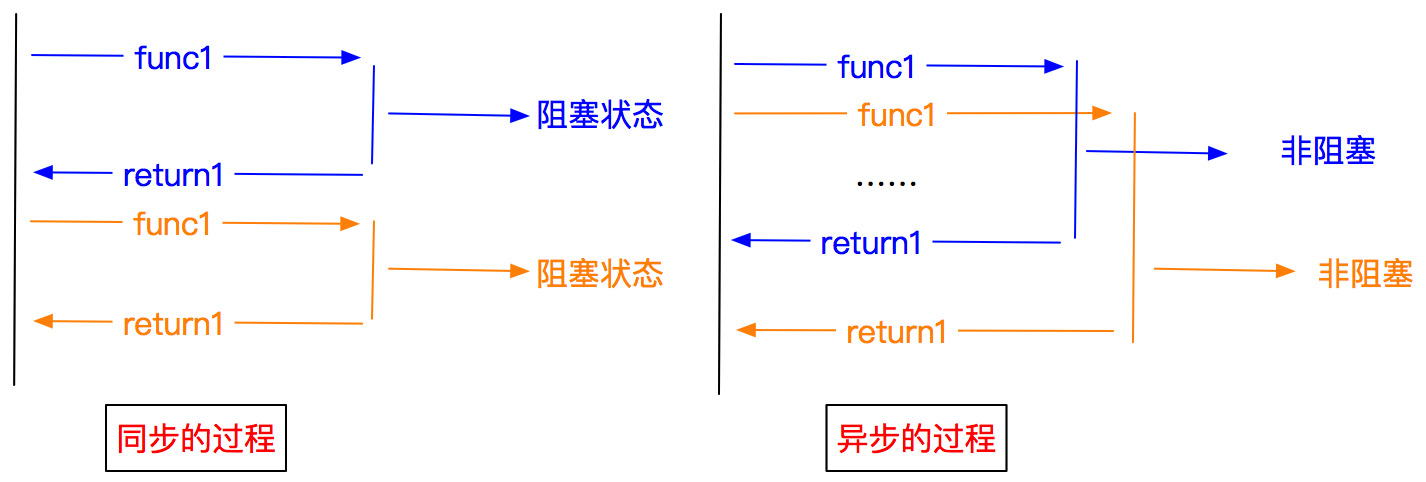
异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程。
4、Scrapy工作流程
回顾之前的爬虫流程
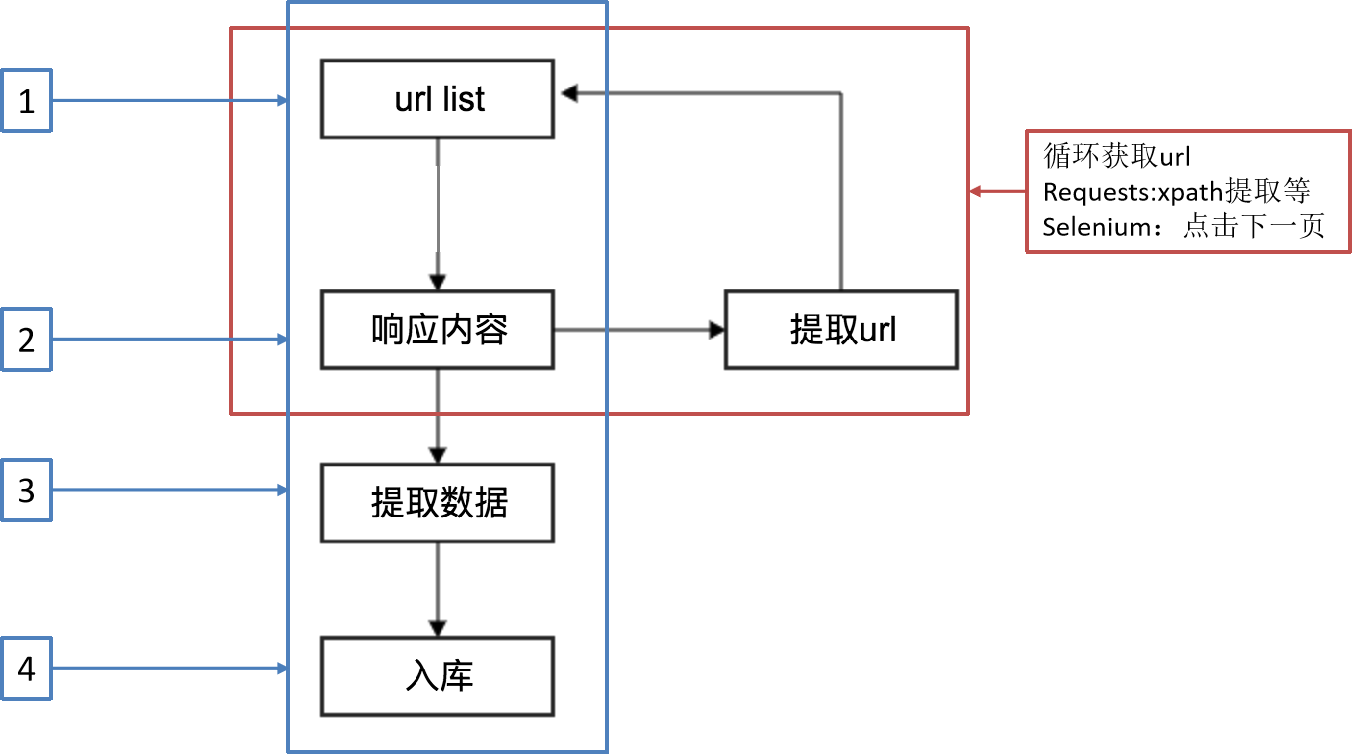
另外一种爬虫方式
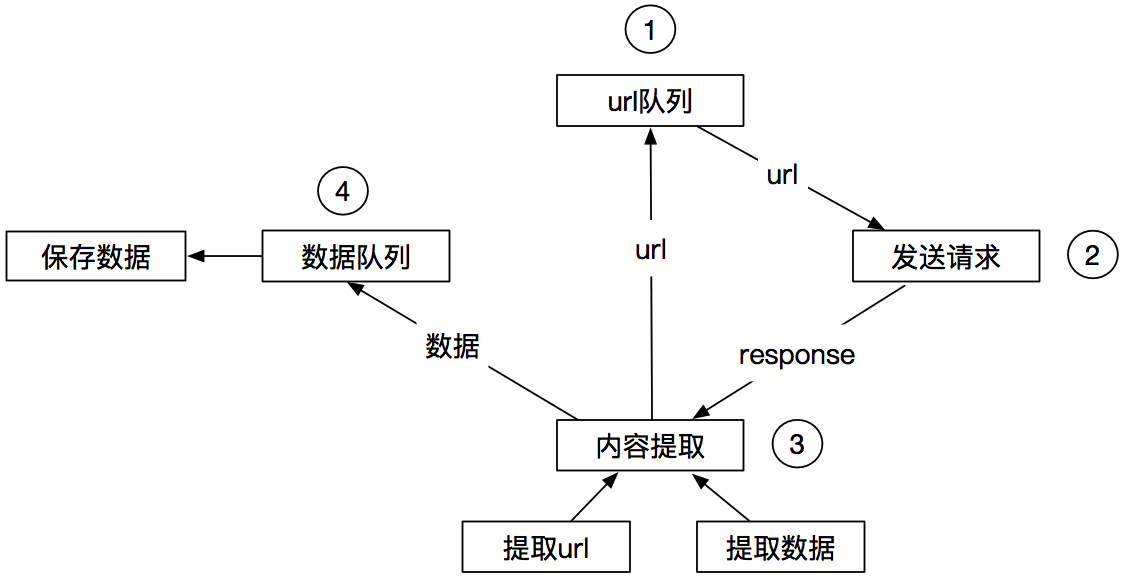
Scrapy的爬虫流程
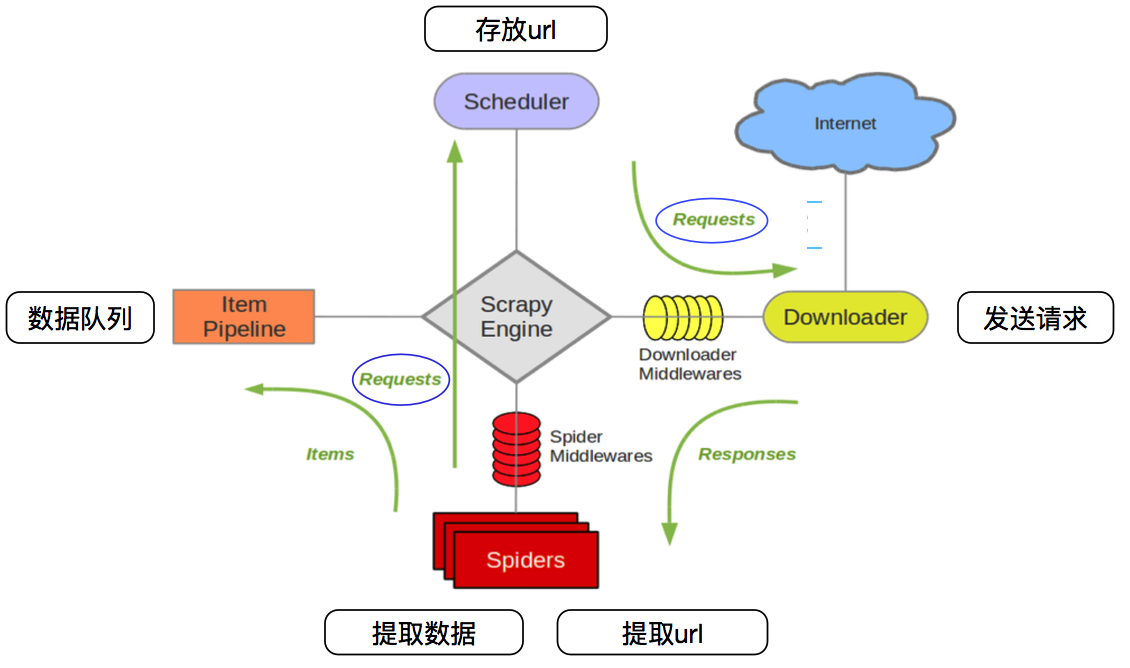
| Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider Middlewares(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
5、Scrapy项目创建
cmd进入到要创建项目的文件夹中执行下面命令1 创建一个scrapy项目scrapy startproject mySpider(项目的名称)2 生成一个爬虫scrapy genspider demo "url"demo:爬虫的名称url:爬取的范围,一般不写http那些3 提取数据完善spider 使用xpath等4 保存数据pipeline中保存数据
6、Scrapy运行
在命令中运行爬虫
scrapy crawl qb # qb爬虫的名字
在pycharm中运行爬虫
在scrapy框架项目的根目录下新建py文件
from scrapy import cmdline
cmdline.execute("scrapy crawl qb".split())
7、Scrapy使用小技巧
- 要用pipelines.py文件,需要在settings文件中将ITEM.PIPELINES的注释去掉
- 不看其他中间件的输出信息,在settings文件中添加:LOG_LEVEL = “WARNING” 即可
- 使用.xpath()方法获取到标签后,通过extract()或get_all、extract_first()或get()方法来取值,而不是简单的列表取值;
- 爬虫文件只能yield返回以下几种数据类型,否则报错
- Request
- BaseItem
- dict
- None
- 项目名和爬虫名不可同名,否则无法创建爬虫文件
- 当在start.py 开启多个爬虫时,只会执行第一个爬虫,其它都不会执行; ```python from scrapy import cmdline
cmdline.execute(‘scrapy crawl bj’.split())
cmdline.execute([‘scrapy’, ‘crawl’, ‘jd’]) # 执行 cmdline.execute([‘scrapy’, ‘crawl’, ‘bj’]) # 不执行 ```

若有收获,就点个赞吧
0 人点赞
