1、数据分类
非结构化数据:HTML
处理方法:正则表达式、xpath、os4
结构化数据:json、xml
处理方法:转化为Python数据类型
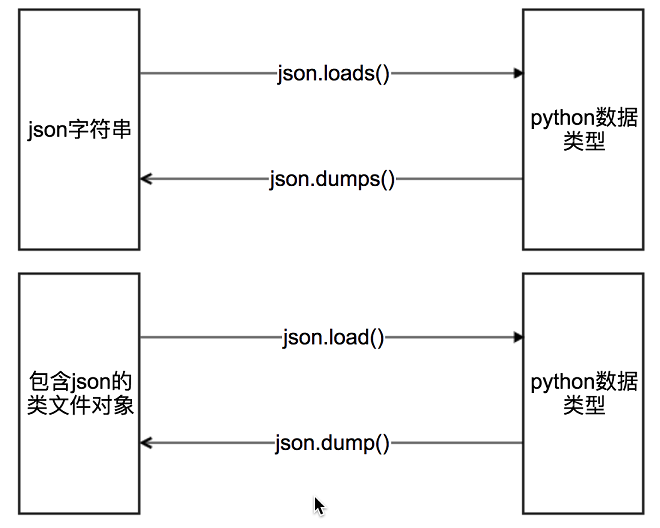
数据提取之json
由于把json数据转化为python内建数据类型很简单,所以爬虫中,如果我们能够找到返回json数据的URL,就会尽量使用这种URL
JSON是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
使用json注意点
- json中的字符串都是双引号
案例:抓取掘金动态
import requestsfrom urllib.request import urlretrieveclass WangzheSpider(object):def __init__(self):self.url = "http://gamehelper.gm825.com/wzry/hero/list"self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}def wangzhe_parse(self):res = requests.get(self.url, headers=self.headers)return resdef parse_data(self, res):datas = res.json()["list"]for data in datas:hero_url = data["cover"]hero_name = data["name"]# img_content = requests.get(hero_url, headers=self.headers)self.save_img(hero_name, hero_url)def cbk(self, a, b, c):"""回调函数@a:已经下载的数据块个数@b:数据块的大小@c:远程文件的大小"""per = 100 * a * b / cprint(a, b, c)if per > 100:per = 100print('%.2f%%' % per)def save_img(self, hero_name, hero_url):filename = "img/{}.png".format(hero_name)urlretrieve(hero_url, filename, self.cbk)# img = img_content.content# with open(filename, "wb") as f:# f.write(img)def run(self):# 1请求数据res = self.wangzhe_parse()# 2解析数据# 3保存图片self.parse_data(res)passif __name__ == '__main__':wangzhe_spider = WangzheSpider()wangzhe_spider.run()
案例:抓取王者荣耀英雄图片
注意urlretrieve(url, filename)的使用,可以直接将图片下载下来并且保存到指定路径;
import requestsclass WangzheSpider(object):def __init__(self):self.url = "http://gamehelper.gm825.com/wzry/hero/list"self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}def wangzhe_parse(self):res = requests.get(self.url, headers=self.headers)return resdef parse_data(self, res):datas = res.json()["list"]for data in datas:hero_url = data["cover"]hero_name = data["name"]img_content = requests.get(hero_url, headers=self.headers)self.save_img(hero_name, img_content)def save_img(self, hero_name, img_content):filename = "img/{}.png".format(hero_name)img = img_content.contentwith open(filename, "wb") as f:f.write(img)def run(self):# 1请求数据res = self.wangzhe_parse()# 2解析数据# 3保存图片self.parse_data(res)passif __name__ == '__main__':wangzhe_spider = WangzheSpider()wangzhe_spider.run()

若有收获,就点个赞吧
0 人点赞
