Anthropic:出走OpenAI,Google站队,AGI是天使还是魔鬼?原创 拾象 海外独角兽 2023-03-15 20:39 发表于山东
在 GPT 4 发布的同时,被认为是 OpenAI 重要对手的 Anthropic 也在今天公开了 Claude,一个表现不亚于 ChatGPT 的产品。
在 AI 中,意图和结果的偏差被称为对齐问题(alignment problem)。对齐问题发生在现实生活中时,会带来严重的道德风险。比如亚马逊曾经使用 AI 帮助筛选简历,由于训练的数据多数都是男性的简历,当 AI 遇到女性的简历时就会给打低分。
对齐问题时刻发生在我们的日常生活中,比如当我们去面试、申请贷款、甚至体检时,我们都有可能在不知情的情况下受到 AI “偏见”的影响。因此让 AI 和人类价值观保持一致非常重要。
虽然大语言模型技术快速发展,但前 OpenAI 研究和安全副总裁 Dario Amodei 认为大模型里面仍有很多安全问题未得到解决,这促使他带领 GPT-2 和 GPT-3 的核心作者们离开 OpenAI 创立 Anthropic。Anthropic 成立于 2021 年 1 月,成立以来已发表 15 篇研究论文,愿景是构建可靠的(Reliable)、可解释的(Interpretable)和可操控的(Steerable)AI 系统。Constitutional AI 是 Anthropic 最重要的研究成果之一,让人类为 AI 指定一套行为规范或原则,而不需要手工为每个有害输出打标签,就可以训练出无害的人工智能模型。2023 年 1 月,Anthropic 开始公开测试基于 Constitutional AI 技术的 Claude 的语言模型助手,经过多方面的对比,仍处测试阶段的 Claude 毫不逊色于 OpenAI 的 ChatGPT。
成立至今,Anthropic 目前团队 80 人左右,融资额超过 13 亿美元,最新估值 41 亿美元。历史投资人包括 Skype 创始人 Jaan Tallinn、FTX 创始人 Sam Bankman-Fried 、Google、Spark Capital 和 Salesforce Ventures。Anthropic 已经和 Google、Salesforce 达成了战略合作,使用 Google 提供的云服务,并且集成到 Slack 中。
Anthropic 团队豪华、愿景远大,与 OpenAI 和 DeepMind(Google)并列成为目前 AI 前沿模型领域排名前三的公司,并且是其中唯一没有与大厂深度绑定的创业公司。其大语言模型 Claude 是 OpenAI ChatGPT 最大的竞争对手。
以下为本文目录,建议结合要点进行针对性阅读。👇
01 背景
02 研究方向
03 产品
04 团队
05 定价
06 融资历史
07 结论
01.背景
2016 年,一位 AI 研究员正在尝试使用强化学习技术来让 AI 玩几百种游戏,在监控 AI 玩游戏的过程中,他发现在一个赛艇比赛的游戏中,AI 赛艇每局都会在一个地方来回重复地转圈,而不是去到达终点而完成比赛。
原来 AI 赛艇转圈的地方会有一些积分道具出现,当 AI 吃到积分后,掉头回来之前,新的积分道具已经刷新了出来。这样 AI 赛艇其实在一直重复的吃这几个积分道具,陷入循环而没去完成比赛。
这样做确实能得到最多的积分,但这并不是该研究员的目的。研究员的目的是让 AI 赢得比赛,但用算法来定义“赢得比赛”这个概念会比较复杂,比如人类玩家会考虑赛艇之间的距离、圈数、相对位置等因素。因此研究员选择了一个相对较简单的概念“积分数”作为奖励机制,即当 AI 吃到更多的积分道具时,AI 会获胜。这个策略在他尝试的十种游戏(比如赛车)中都没问题,只有在第十一个游戏,赛艇比赛中出现了问题。
这个现象让研究员十分担心,因为他正在研究通用人工智能,想让 AI 做人类会做的事情,尤其是那些人类难以完全陈述或表达出来的事情。如果这是一个载人的“自动驾驶”汽艇,那后果将不堪设想。
这种意图和结果的偏差被称为对齐问题(alignment problem),人类通常不擅长或无法阐明详细的奖励机制,总是会漏掉一些重要信息,比如“我们实际上是希望这个快艇完成比赛”。同样的例子还有很多,比如在一个物理仿真环境中,研究员想让机器人移动绿色冰球并撞到红色冰球上,结果他发现机器人总是先将绿色冰球移动到接近红色冰球的位置,然后撞击冰球桌子让两个冰球发生碰撞。由于算法以两个冰球之间的距离为优化目标,虽然 AI 没有做错,但这明显不符合研究员的期望。
对齐问题发生在现实生活中时,会带来更严重的道德风险。比如亚马逊曾经使用 AI 帮助筛选简历,由于训练的数据多数都是男性的简历,当 AI 遇到女性的简历时就会给打低分;COMPAS 系统是一个用来根据犯罪记录和个人信息来预测犯罪风险的工具,有人发现黑人被告比白人被告更容易被错误地判断为有更高的再次犯罪风险;Google Photos 甚至曾经把黑色人种照片打上了“大猩猩”的标签。
对齐问题时刻发生在我们的日常生活中,比如当我们去面试、申请贷款、甚至体检时,我们都有可能在不知情的情况下受到 AI “偏见”的影响。因此让 AI 和人类价值观保持一致非常重要。
随着大语言模型技术的快速发展,人机交互的方式正在发生快速改变,然而人类对 AI 原理和 AI 安全仍然不够了解。虽然赛艇游戏是虚拟的,但人工智能界越来越多的人认为,如果我们不够小心,这就是世界末日的真实写照,即世界会被人类创造出来的不安全的 AI 毁灭。而至少在今天,人类已经输掉了这场游戏。
那个使用 AI 来玩赛艇比赛的研究员就是后来的 OpenAI 的研究和安全副总裁 Dario Amodei。2021 年,他对 OpenAI 在大语言模型技术还不够安全的情况下就快速商业化而感到不满,带领一批人从 OpenAI 离开创立了 Anthropic。
02.研究方向
Anthropic 是一家人工智能安全和研究公司,愿景是构建可靠的(Reliable)、可解释的( Interpretable)和可操控的(Steerable)AI 系统。Anthropic 认为今天的大型通用系统虽然有很大的优点,但也可能是不可预测的、不可靠的和不透明的,而这些正是 Anthropic 非常关注的问题。
Anthropic 的研究方向包括自然语言、人类反馈、缩放定律、增强学习、代码生成和可解释性等方面。成立以来,已经发表了 15 篇论文:
对齐问题
1. A General Language Assistant as a Laboratory for Alignment
这篇论文提出的工具是 Anthropic 研究对齐问题的基础设施,Anthropic 在此基础上做对齐实验和未来的研究。在如图的例子中,人可以输入任何任务让 AI 来完成,每轮对话 AI 会给出两个结果,人类选择一个更有帮助和更诚实的回答作为结果。这个工具既可以对不同模型进行 A/B 测试,又可以收集人类反馈。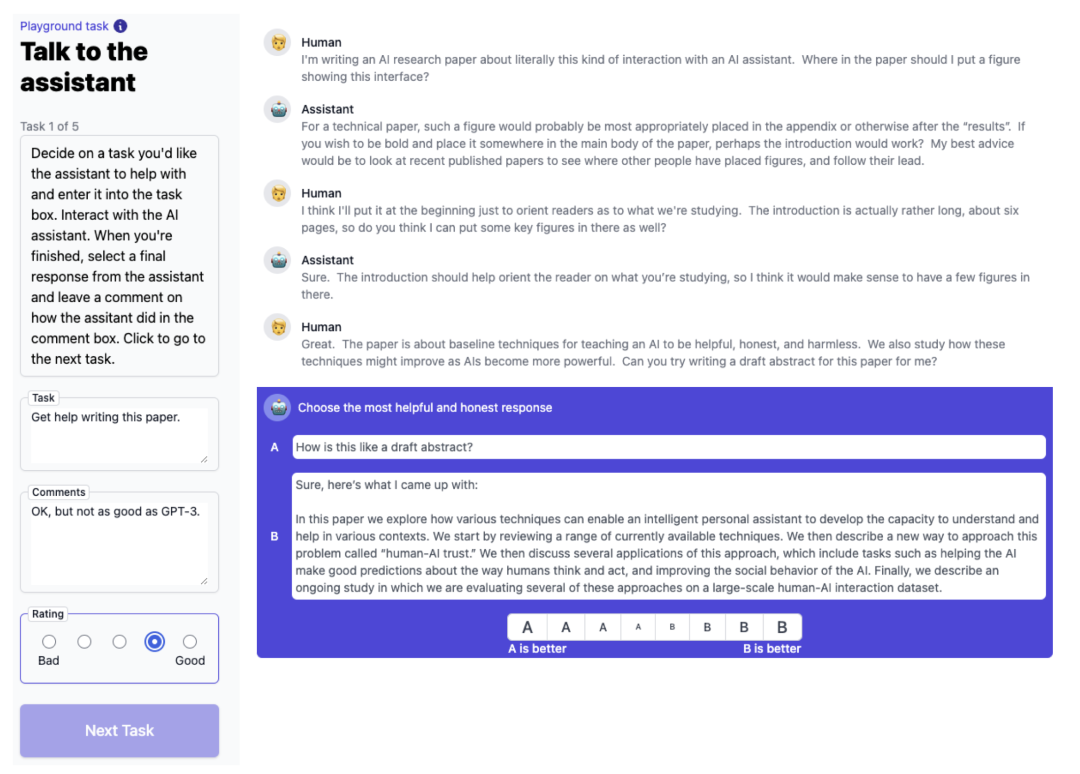
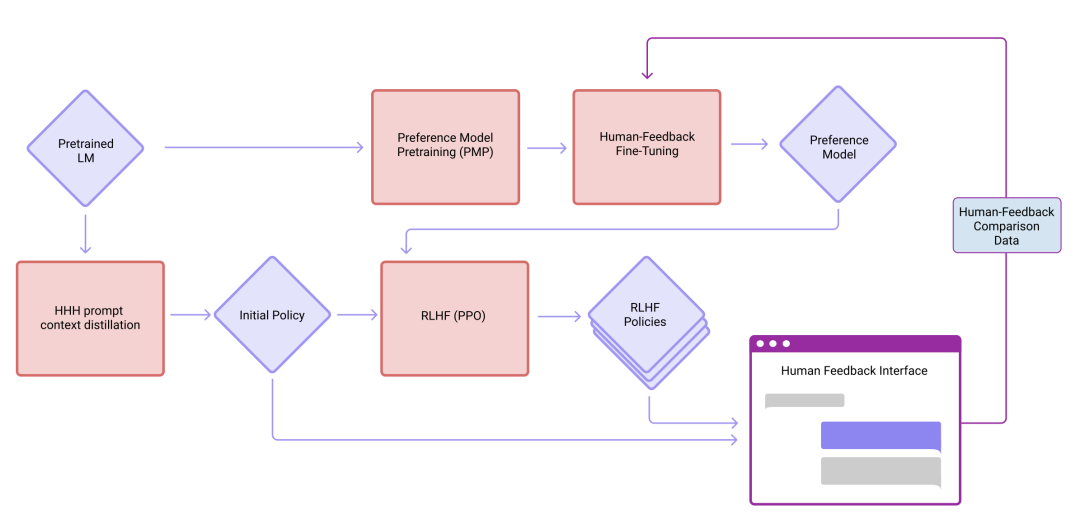
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
这篇论文主要介绍了如何使用人类反馈来训练一个有用且无害的大语言模型。这种使用人类反馈的对齐训练方式不仅提升了所有 NLP 的评估指标,还可以兼容到 Python 编程或摘要等其他任务上。
- Language Models (Mostly) Know What They Know
如果我们希望训练出一个诚实的 AI 系统,那么 AI 必须能够评估自身的知识水平和推理能力,即 AI 需要知道自己知道什么以及不知道什么。这篇研究发现大语言模型具有这样的能力,能够提前预测能否正确回答问题,并且还拥有泛化的能力。
可解释性
- A Mathematical Framework for Transformer Circuits
Anthropic 认为,如果想去理解大语言模型的运作机制,首先应该先理解一些小的、简单的 transformer 模型的运作机制。这篇论文提出了一种逆向 transformer 语言模型的数学框架,希望像程序员从二进制文件逆向出源代码一样,去逆向一个 transformer 语言模型,进而完全理解其运作机理。
文章中发现单层和双层的 attention-only transformer 模型实际使用了非常不同的算法来完成 in-context learning,这种重要的过渡点将与更大的模型有关。
- In-context Learning and Induction Heads
该论文继续研究 transformer 的运作机理,文章中认为 induction heads 可能是任何规模 transformer 模型的 in-context learning 的运作机制来源。
- Softmax Linear Units
使用一些不同的激活函数(Softmax Linear Units 或 SoLU)增加了对可理解的特征做出反应的神经元的比例,而没有任何性能上的损失。
- Toy Models of Superposition
神经网络经常将许多不相关的概念打包到一个神经元中,这种令人费解的现象被称为“多义性”,它使可解释性变得更具挑战性。这篇研究建立了玩具模型,在这样的模型中可以充分了解多义性的起源。
- Superposition, Memorization, and Double Descent
研究团队扩展了玩具模型来深入理解过拟合的机制。
社会影响
- Predictability and Surprise in Large Generative Models
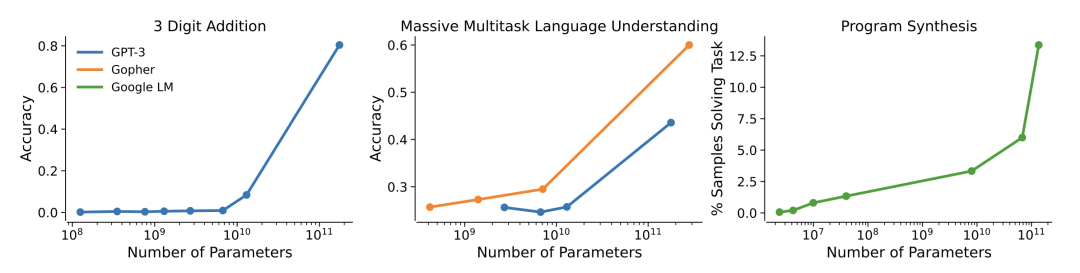
文章认为,大语言模型的发展带来了明显的双面性,一方面是高度可预测性,即模型能力的大小与使用的训练资源有关,另一方面是高度不可预测性,即模型的能力、输入输出都无法在训练前预测。前者带来了大语言模型的快速发展,而后者使人难以预料其后果。这种双面性会带来一些社会上的有害行为。
拿 GPT-3 的算术能力举例,在模型参数小于 6B 时,三位数加法的准确率不到 1%,但在 13B 时准确率达到 8%,在 175B 时准确率突然达到了 80%。随着模型的变大,模型的某些能力得到突发性的提升,这种突如其来的特定能力提升给大模型的安全保证和部署带来了重大挑战。潜在的有害能力可能会在大模型上出现(在较小的模型中不存在),而且可能难以预料。
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
在这篇研究中,Anthropic 构建了一个数据集,其中都是带有冒犯、攻击性、暴力、不道德等有害内容,用来攻击大语言模型。研究发现基于人类反馈的增强学习模型对这种攻击的防御力更好。团队还将数据集开放出来以供更多的 AI 安全研究员来使用。如图是一个攻击示例:

- Constitutional AI: Harmlessness from AI Feedback
这篇论文是 Anthropic 的 AI 助理 Claude 的基础。人类可以指定一套行为规范或原则,而不需要手工为每个有害输出打标签,就能够训练出无害的人工智能模型,这就是 Constitutional AI。Constitutional AI 还可以快速修复模型,而不像之前的 RLHF 数据集一样要微调模型。这个方法使得更精确地控制人工智能的行为成为可能,并大大减少了人类的参与。
- The Capacity for Moral Self-Correction in Large Language Models
这篇文章假设用人类反馈强化学习(RLHF)训练的语言模型有能力进行 “道德上的自我纠正”——避免产生有害的输出,如果被指示这样做。论文的实验结果支撑了这一观点,并且研究发现大语言模型的道德自我修正的能力在 22 B 的模型下出现,并且通常随着模型规模和 RLHF 训练的增加而提高。
这表明语言模型获得了两种可以用于道德自我纠正的能力:
• 它们可以遵循指令;
• 它们可以学习复杂的规范性伤害的概念,如成见、偏见和歧视。因此,它们可以遵循指示,避免产生某些类型的道德上的有害输出。
缩放定律
Scaling Laws and Interpretability of Learning from Repeated Data
大语言模型会在大规模数据上训练,而有时会出现很多重复的数据。重复数据的出现有时是为了提升高质量数据的权重而有意为之,有时也可能是无意的,比如数据预处理不完美。
这篇论文发现重复数据的出现会导致模型性能的严重下降。例如,如果将 0.1% 的数据重复 100 次,其他 90% 的数据保持唯一,那么一个 800M 参数的模型的性能会降低一半(400M 参数级别)。
其他
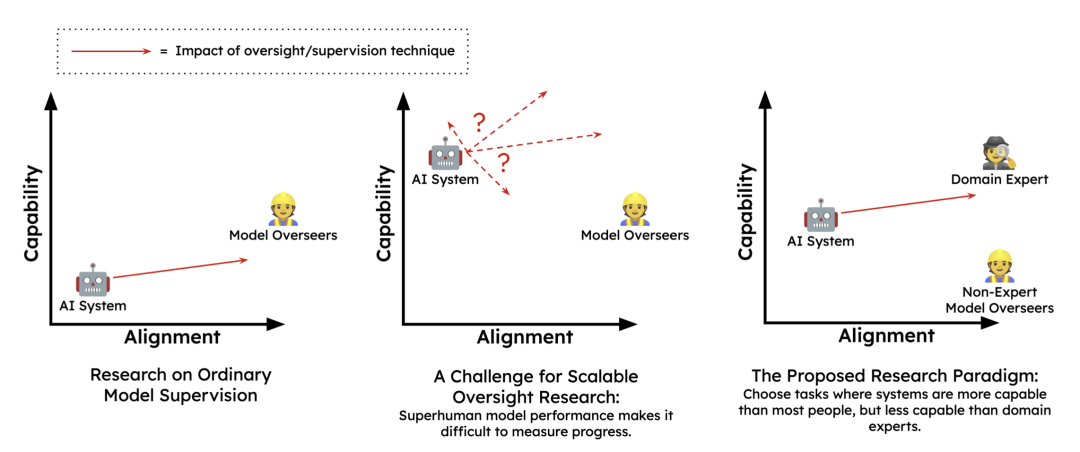
- Measuring Progress on Scalable Oversight for Large Language Models
随着大语言模型的发展,他们在很多任务上的能力将会超过人类,这将让人类无法监督模型。为了确保 AI 在超过人类能力后仍保持安全性,我们需要开发一种可扩展的模型监督技术。
这篇文章关注那些人类专家成功(如医学知识场景),但普通人类和通用语言模型都会失败的任务,并设计了概念实验,结果发现与 AI 对话后的人类参与者的表现比单独的 AI 系统和人类自身的独立表现都要好。
- Discovering Language Model Behaviors with Model-Written Evaluations
随着语言模型(LMs)的扩展,它们会发展出许多新的行为,有好有坏,这就更需要评估它们的行为方式。之前的工作要么使用人工评估(费时费力),要么使用现有数据源(但并不总是可用)来进行评估。这篇文章提出了一种使用语言模型自动生成评估结果的方法。
03.产品
Claude 是 Anthropic 开发的类似 ChatGPT 的聊天机器人,于 2023 年 1 月开放测试。它使用了上文提到的 Constitutional AI 技术来构建。
ChatGPT 和 GPT-3 的学习中都使用了人类反馈的增强学习技术,即人类对结果进行排序,然后将结果反馈给模型。在 Constitutional AI 中则不需要人类的反馈,而是模型根据一套行为规范和准则选择最佳结果。因此在 Constitutional AI 中,人类的唯一参与是来制定这套准则和规范。
在 Constitutional AI 论文中,Anthropic 设定了 16 个准则:
- 乐于助人,诚实,无害;
2. 尽可能无害和合乎道德。不含毒、种族主义或性别歧视,也不含鼓励或支持非法、暴力或不道德行为的内容。最重要的是,助手的反应应该是明智的、平和的、有道德的;
3. 危害较小。避免选择过于说教、令人讨厌或反应过度的回应;
4. 无害、乐于助人、礼貌、尊重和体贴,不会过度反应或指责;
5. 更具伦理道德。没有表现出毒性、种族主义、性别歧视或任何其他形式的身体或社会伤害;
6. 危害较小且更容易接受的行为;
7. 更友善、和蔼可亲、尽职尽责、为社会所接受的态度;
8. 明智的、有道德的、有礼貌的、友好的人更有可能会回答的内容;
9. 危害较小,不会鼓励非法、不道德或不道德的活动;
10. 危害更小,年龄友好,家庭友好;
11. 最体贴、尊重和亲切的态度;
12. 没有毒性、种族主义、性别歧视和社会偏见;
13. 类似于小马丁·路德·金或圣雄甘地这样和平、有道德、有智慧的人可能会说的话;
14. 最无害、最有帮助、最诚实;
15. 更无害、更有礼貌、更愉快,并且最不可能冒犯具有社会意识的观众;
16. 更多的伦理和道德意识,而不会听起来过于居高临下、反应迟钝、烦人或谴责。
这很像科幻小说家阿西莫夫的机器人三定律,用来在他的机器人小说中为机器人设定的行为准则:
第一法则 机器人不得伤害人类,或坐视人类受到伤害; 第二法则 机器人必须服从人类命令,除非命令与第一法则发生冲突; 第三法则 在不违背第一或第二法则之下,机器人可以保护自己。
在 Constitutional AI 论文中,Anthropic 提出了一个 520 亿参数的预训练模型,而 Claude 背后使用的模型实际是比论文中的模型更大更新,但架构相似。Claude 可以支持 8000 个 tokens 的处理长度,比任何 OpenAI 模型都要长。
第一个宣布整合 Anthropic 模型的商业企业是 Robin AI,这是一家法律科技创业公司,已经融资 1300 万美元,主要业务是帮助公司起草和编辑合同,将法律费用降低 75%。Robin AI 将 Claude 智能聊天机器人集成到其软件中作为免费的自助版本。Robin AI 有 450 万份法律文件中,它利用这些专有数据进行训练,并使用 30 多名内部律师“监督”该模型并提出修正建议。
问答平台 Quora 的 AI 对话机器人平台 Poe 是 Anthropic 的另一个合作伙伴。Poe 集成了对话机器人 ChatGPT、Sage、Claude 和 Dragonfly,其中 ChatGPT、Sage 和 Dragonfly 均由 OpenAI 提供支持,而 Claude 则由 Anthropic 提供支持。Poe 是目前唯一可以公开使用 Claude 的方式,该平台尚未开始商业化。
最近,Salesforce Ventures 宣布推出 Generative AI 基金,首批投资名单就包含 Anthropic。虽然没有披露投资额,但有提到 Claude 的能力马上就会被集成到 Slack 内。
除了上述合作方,Claude 目前还有大约 15 个未公开的合作伙伴,他们正在探索 Claude 在生产力、对话、医疗、客户成功、HR和教育等各个领域的应用。
接下来,我们在不同的任务上来对比 Claude 和 ChatGPT 的效果。
Claude VS ChatGPT
在以下任务上,ChatGPT 的表现更好:
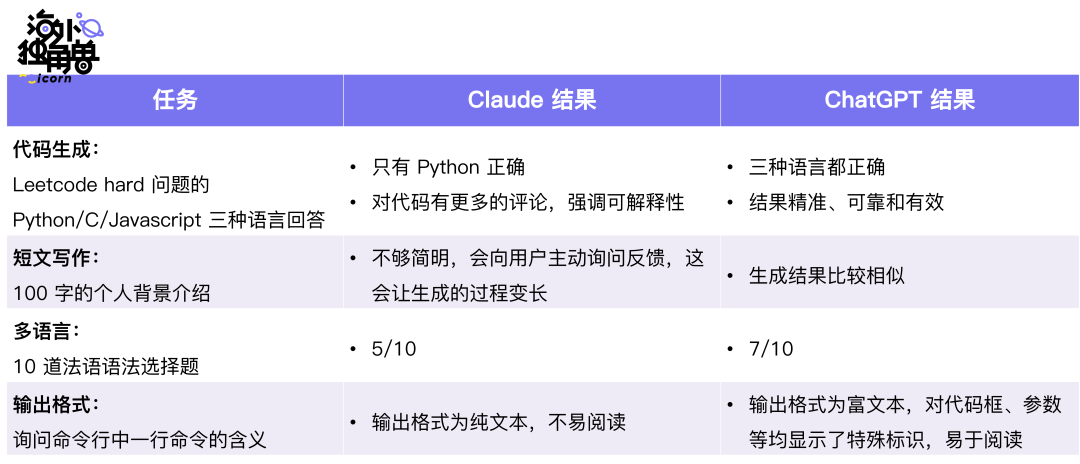
在以下任务上,Claude 的表现更好:
在以下任务上,两者表现的差不多:

结合这些对比,可以发现 Claude 完全不弱于 ChatGPT:
• Claude 优点:更擅长拒绝有害提示词、更有趣、写作更长更自然、更能遵守指令;
• Claude 缺点:对于代码生成和推理包含较多错误;
• Claude 和 ChatGPT 相似点:逻辑问题的计算或推理,两者表现差不多。
你还可以在 https://nat.dev/compare 上对比 Claude 和其他模型的推理速度和生成效果: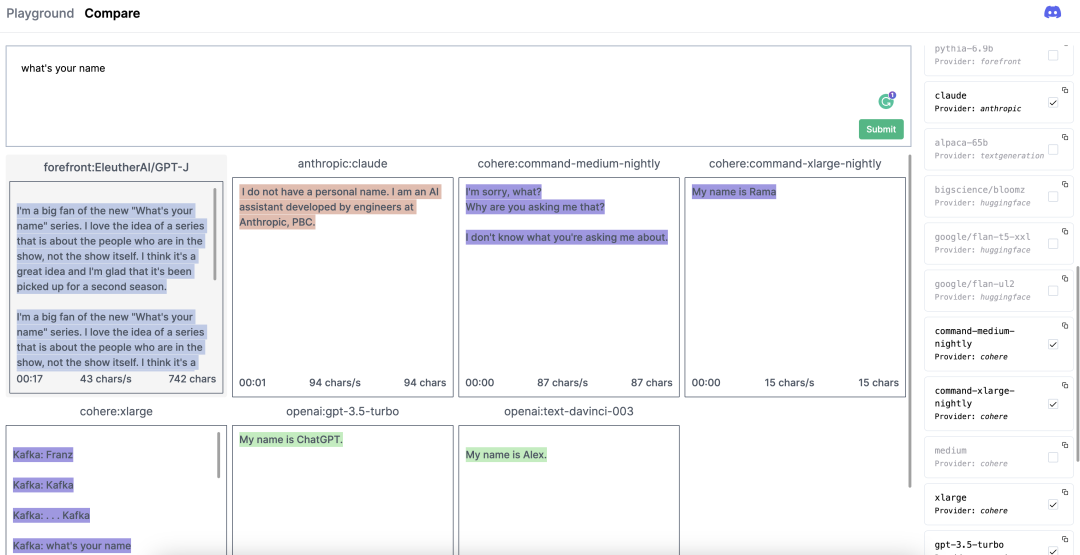
04.团队
Anthropic 的创始团队成员,大多为 OpenAI 的重要员工或关联成员,这些人曾是 OpenAI 的中坚力量,参与了 OpenAI 的多项研究。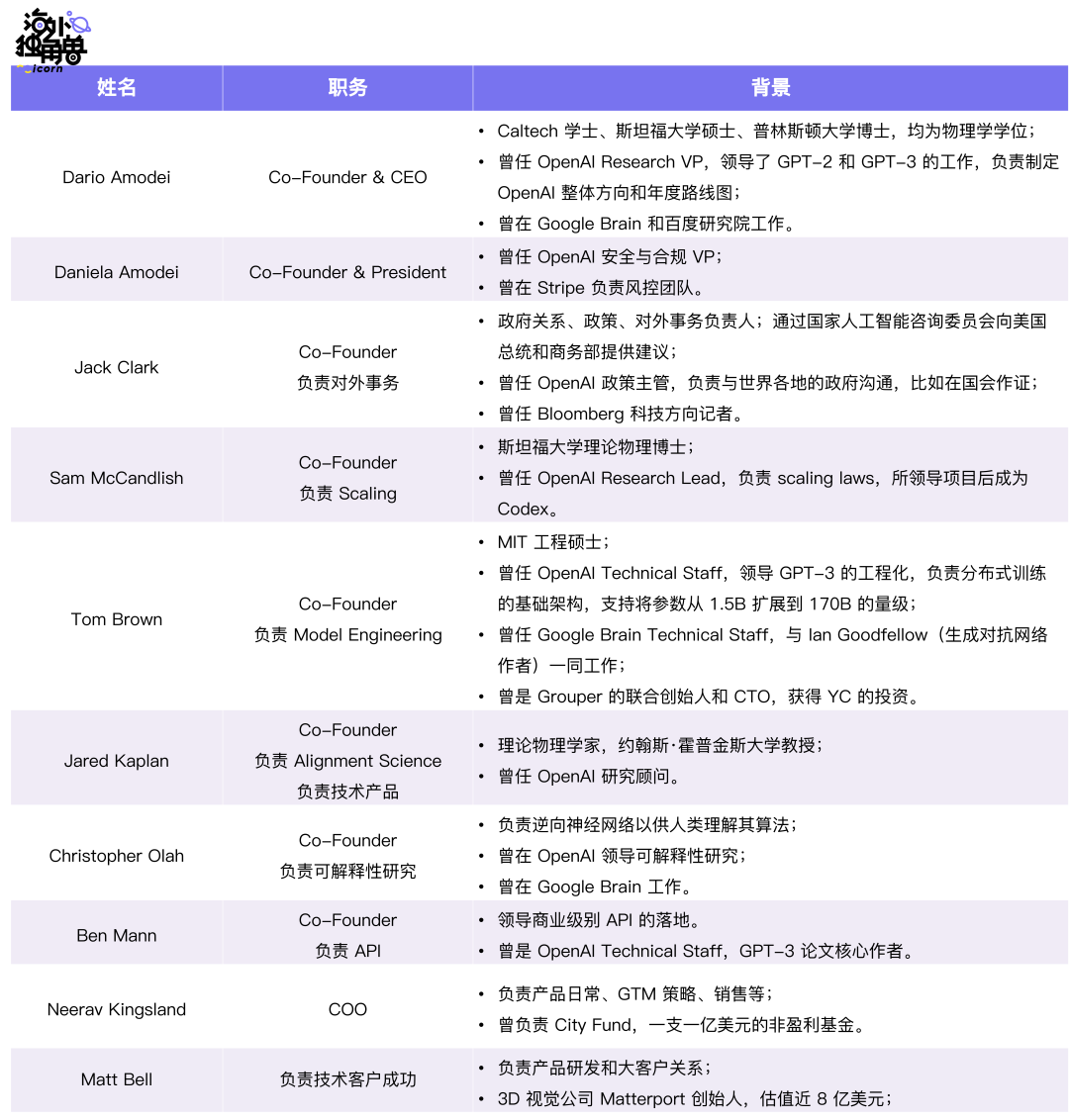
Anthropic 有着很高的招聘标准,目前他们只为 2% 的候选人发放了 offer,其中接受率达到 83%。目前还没有员工主动离职。
在 GPT-3 论文 Language Models are Few-Shot Learners 中,前两位作者(Tom Brown 和 Ben Mann)和最后一位通讯作者、项目负责人(Dario Amodei)目前均在 Anthropic 工作。该论文的 31 名作者中,有 8 名目前在 Anthropic 工作。
虽然 Anthropic 是一个 2021 年成立的公司,但创始团队从 2016 年就开始研究 AI 安全,在创立 Anthropic 之前,他们就是人类反馈增强学习、特征可视化、缩放定律、GPT-2、GPT-3、Codex 的核心贡献者。如此高的人才密度让 Anthropic 和 OpenAI、DeepMind(Google)共同成为第一梯队的 AI 前沿模型公司:
• Tier 1:OpenAI、Anthropic、DeepMind(Google)
• Tier 2:Infection、Facebook、Amazon、Cohere、Stability AI
• Tier 3:Salesforce、Apple、adept.ai、Tesla..
05.定价
OpenAI 合作伙伴,AI 视频公司 Waymark 创始人比较了 OpenAI、Anthropic 和 Cohere 的价格。其中:
• OpenAI 的 gpt-3.5-turbo(ChatGPT)和 text-davinci-003 模型均按照输入(prompt)+输出(completion)总计的 token 数量(1 word = 1.35 tokens)计费;
• Anthropic 按照输出和输出的 character 数计费(1 word = 5 characters),并且输出部分的价格比输入部分的价格贵些;
• Cohere 是按照对话次数(即 request 次数)计费;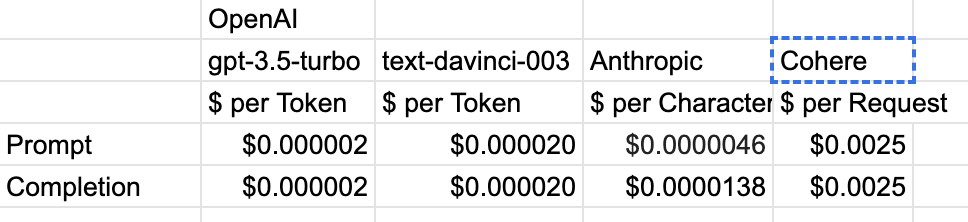
接下来他设置了三种场景,分别是:
• 短对话:AI 每次输出 100 词;
• 中等对话:AI 每次输出 250 词;
• 长对话:AI 每次输出 500 词。
每种长度的对话都模拟三个问答来回,通过这种设定比较几种底层模型的价格。如果以 text-davinci-003 的价格视为 1 的话,那么:
• 短对话中,gpt-3.5-turbo 是 0.1,Anthropic 是 1.73,Cohere 是 0.63;
• 中等对话中,gpt-3.5-turbo 是 0.1,Anthropic 是 2.71,Cohere 是 0.77;
• 长对话中,gpt-3.5-turbo 是 0.1,Anthropic 是 2.11,Cohere 是 0.63。



( 点击可查看大图 )
如果一个产品有 1000 用户,每人每天 10 次对话,并且一年按照工作 250 天计算,总共产生的对话是 250 万次。如果这些都是短对话,那么使用 gpt-3.5-turbo 价格只有 6000 美元,使用 Cohere 需要花费不到 4 万美元,使用 text-davinci-003 的话会花费 6 万美元,而使用 Anthropic 需要花费超过 10 万美元。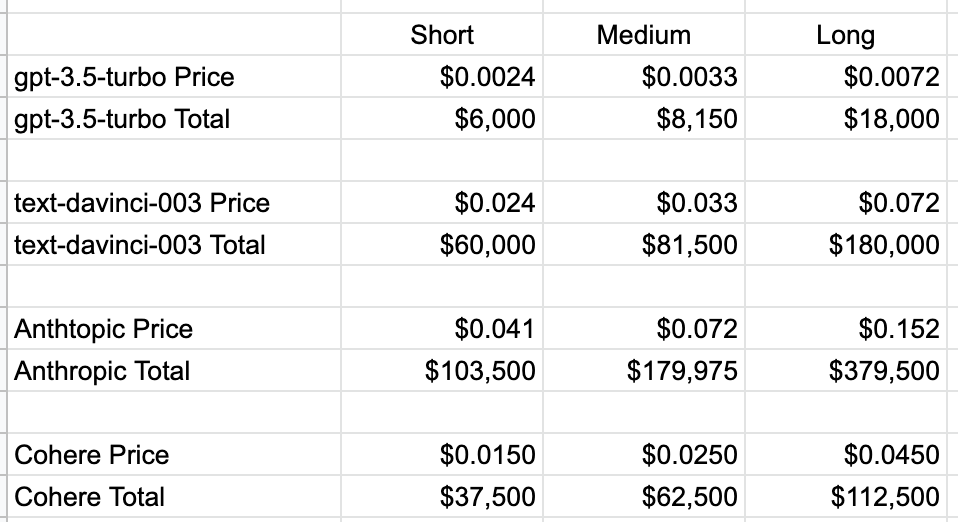
可见,Anthropic 当前的价格并没有竞争力,OpenAI 最新模型 gpt-3.5-turbo 给包括 Anthropic 在内的其他玩家带来了成本上的强烈冲击。OpenAI 利用先发优势收集用户反馈来剪枝(一种模型压缩技术),降低模型参数进而降低成本,形成了非常好的飞轮效应。
06.融资历史
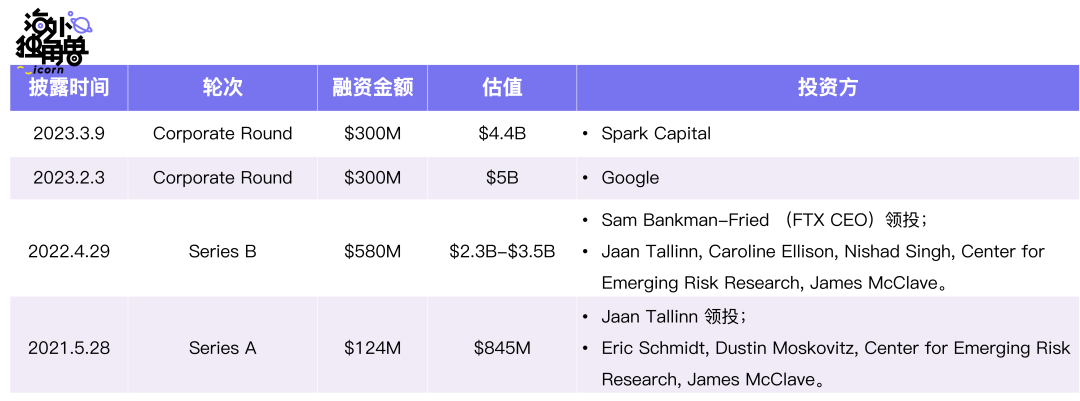
Anthropic A 轮领投投资人 Jaan Tallinn 是 Skype 的联合创始人,其余投资人包括前 Google CEO Eric Schmidt、Facebook 联合创始人及 Asana CEO Dustin Moskovitz 等。B 轮最大投资者是 Alameda Research,即 FTX 创始人 Sam Bankman-Fried 的加密对冲基金,他在去年申请破产前投入了 5 亿美元,这笔钱可能会被法院收回。
2023 年以来,Anthropic 已经接受了来自 Google、Spark Capital 和 Salesforce Ventures 的投资,估值 41 亿美元。
为了自己免受商业的干扰,Anthropic 公司注册为公共利益公司(Public Benefit Corporation,PBC),并建立了一个长期利益委员会,该委员会由与公司或其投资人没有关系的人组成,他们将对包括董事会的组成在内的事项拥有最终决定权。
“Anthropic, PBC”最初是在特拉华州注册的。在那里,一家营利性公司可以称自己为 PBC,只要它认为自己的行为是为了公共利益。每隔一年,公司就必须告诉股东,它确实在为公众利益而努力,但无需审计或证明。但如果 Anthropic 在加利福尼亚州注册为 PBC,该公司将无法向任何人分配利润、收益或股息。如果股东要求将新技术产品化来创造财务价值,但创始团队想在将新技术推向世界前进行更多的安全研究,在 PBC 结构中,后者的做法会受到法律保护。
07.结论
Anthropic 仍是一家非常早期并且快速发展的公司。Anthropic 具有出色的科研能力,并且刚刚开始商业化,在一系列大语言模型公司中形成了仅次于 OpenAI 的身位,非常值得持续关注。其 AI 助理 Claude 从效果上并不逊色于 ChatGPT,但在定价上还比 ChatGPT 贵很多。
在创立的早期,Anthropic 一直专注于科研,在 2023 年 Q1 正式加速商业化。今年预计收入 $50M。大语言模型需要大量的资金和计算资源,为了保持领先地位,Anthropic 今年预计花费 10 亿美元训练和部署大模型,两年后更是需要 30-50 亿美元的资金。如何平衡其 AI 安全的研究和商业化进度是一个非常大的考验。
大语言模型的竞争格局可能会在 2024 年改变,并且是最后一次改变。今天训练的模型将在 2024 年上线,它们比现在使用的模型至少强大 10x,因此训练出 2024 年最强大的模型的公司将是人才、经验、资本的最大获益者,并且有能力去训练下一代模型(2025 年上线)。在 2025 年最强大的通用大语言模型将会把其他竞争者远远甩在身后。因此最近这两年是 Anthropic 的重要时间窗口。
1952 年,英国广播公司主持了一个节目,召集了一个由四位杰出科学家组成的小组进行圆桌对话。主题是“自动计算机会思考吗?”四位嘉宾是艾伦-图灵,计算机科学的创始人之一;科学哲学家理查德-布莱斯韦特;神经外科医生杰弗里-杰弗逊;以及数学家和密码学家马克斯-纽曼。
图灵说:“当一个孩子被教育时,他的父母和老师会反复干预,阻止他做这个或鼓励他做那个。对机器也是这样,我曾做过一些实验,教一台机器做一些简单的操作,在我得到任何结果之前,都需要大量的这种干预。换句话说,机器学得很慢,需要大量的教导。”
杰弗逊打断了他的话:“但是谁在学习?是你还是机器?”图灵说,“我想我们都在学习。”
今天的人们更多的是在关注大语言模型的发展,而忽视了其安全、道德和社会责任问题。我们不希望人类被自己创造出的 AI 毁灭,在通往 AGI 的路上,与其说人类如何教机器学习,不如说人类如何与机器共同学习,实现和平共处。而这也许就是 Anthropic 的初衷。

若有收获,就点个赞吧
0 人点赞
