ChatGPT轻松搞定显著性校验,清宫大戏生动解析原理! 原创 58UXD 58UXD 2023-04-14 19:05 发表于北京
ChatGPT太火了!虽然是个大语言模型,能力覆盖面却极广,把数据分析的问题丢给它,也可以轻松解决!
AI咒语
最近我们就遇到了这样的数据问题:
- 问题1:A方案数据比B方案数据高了0.9%,是增长还是波动?
- 问题2:实验前期A方案比B方案数据高,一周后数据反转,B比A高了,到底哪个方案好?
把问题发给ChatGPT后,它给出了多种方法来做数据检验: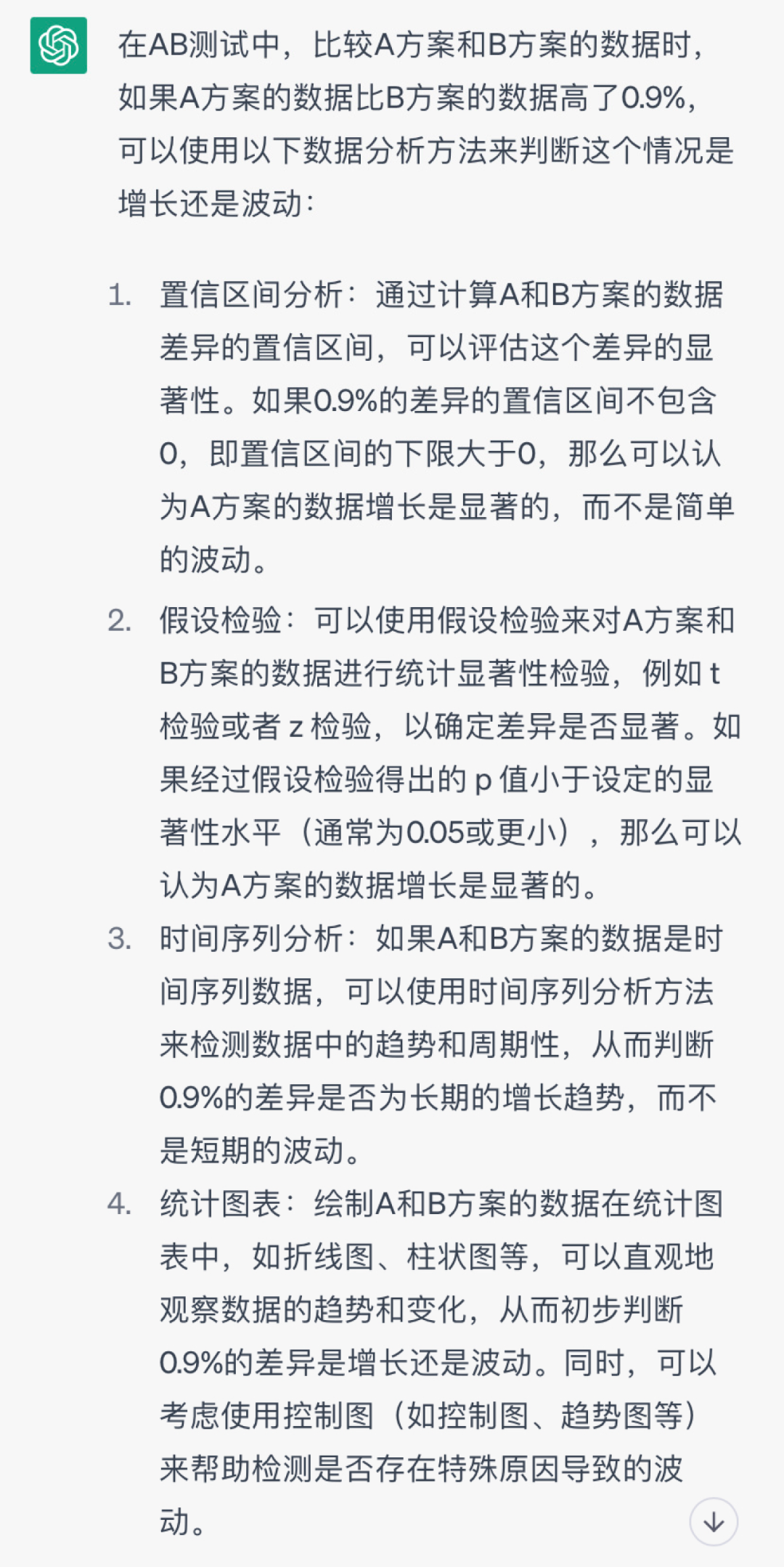
其中“显著”这个词被多次提到,我们就增加“显著性检验”的提问条件,再增加背景数据信息,看它能不能直接给出答案。
果然可行(ChatGPT-4)!我总结了一下咒语:AB测试中方案A样本量XX,转化数XX,方案B样本量XX,转化用户数XX,请进行显著性校验,判断数据增长还是波动。(大家在使用过程中替换XX为具体数据就可以)
数学原理
对于上面的咒语,细心的同学可能会问:把AB方案的两个转化率给ChatGPT,可以进行显著性校验吗?这涉及到显著性原理,我试图让ChatGPT讲一下原理,它虽然举了一个例子,却依然用了很多数学概念。没有统计学基础的同学看了还是一头雾水。
什么样算生动??ChatGPT内心独白:“臣妾做不到啊”
清宫大戏
既然让ChatGPT生动讲解有点为难,那么就让我充分利用设计师的脑洞,为大家导演一场清宫大戏,把显著性校验的原理给讲明白。
因为AB测试一般是小流量测试,把流量放大到整体全量用户,是否会得到与测试实验相同的数据结果?这是一个概率问题。
进入到清宫大戏中,这里有一个场景:太医诊断「娘娘,有喜了」
如果娘娘们在不知道自己是否真的怀孕的情况下,对太医的【诊断】 做出不同的反应。会有什么样的情况出现呢?一共四种情况,在这场大戏中对应四位娘娘。
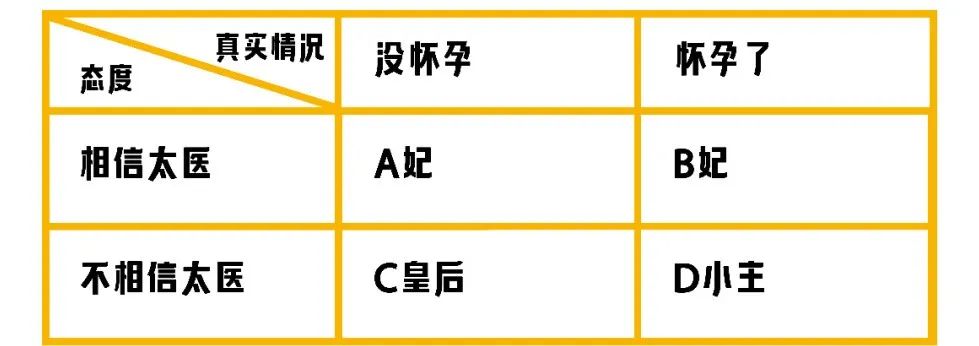
我们来看下每位娘娘的结局:



这四位娘娘中A妃娘娘和D小主的结局是我们不愿意看到的,在统计学上对应为第一类错误和第二类错误,如下图: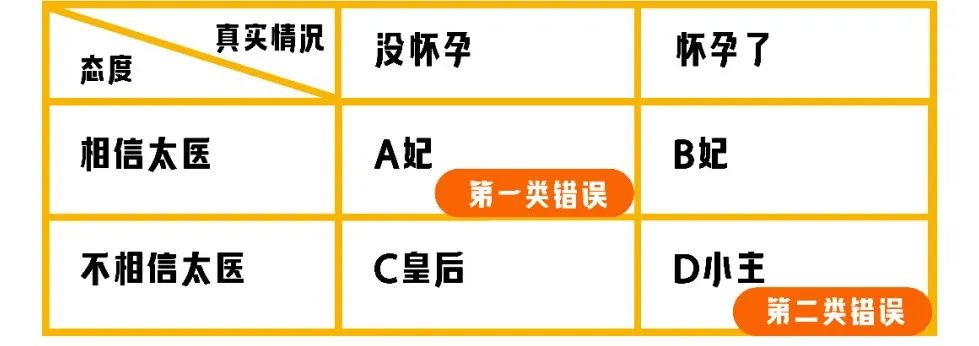
A妃娘娘出现的概率,就是统计学上犯第一类错误的概率,也就是「显著性水平」如果A妃娘娘出现的概率低,太医的诊断【有喜了】是可信的(显著)。相反,A妃娘娘出现的概率超出了我们可接受的范围(通常是0.05),那么太医的诊断就不可信了(不显著)。
统计学上有很多对A妃娘娘出现概率进行检验的公式,比如Z检验就是其中一种,里面会用到转化用户数和样本数,这就是为什么上面的咒语里,提供给ChatGPT样本量数据和转化用户数的原因了:是因为我希望它用Z检验对应的公式帮我做显著性校验。
问题回顾
回顾一下最初的数据问题:
问题1:A方案数据比B方案数据高了0.9%,是增长还是波动?
解法:直接用显著性校验是增长还是波动即可,如果结果是不显著,则可以认为是数据波动。
问题2:实验前期A方案比B方案数据高,一周后数据反转,B比A高了,到底哪个方案好?
解法:用显著性校验看一下当前是否处在波动期,一般需要积累到一定数据量结果才会显著,所以如果得到的是不显著的结论,那么可以拉长时间观测,以积累更多测试样本量,如果积累了足够多的样本量还是不显著,那么就说明AB方案从数据效果上看没有明显差别。
写在最后
因为ChatGPT是一个大语言模型,所以在提问的时候有可能会因为一个语气词或者一个空格而理解成另外的意思,导致给出的回答有偏差。在这里我提供一个线上做显著性校验的网站,数学原理是一样的,使用固定公式,所以获取答案的方式更稳定可靠,同样是只要输入样本量数据和转化用户数就可以进行显著性校验:
https://www.evanmiller.org/ab-testing/chi-squared.html
下面是这个网站的截图:
这个网站是个宝藏网站,里面还有很多其他数学工具,大家可以自行探索哦~

若有收获,就点个赞吧
0 人点赞
