AI 的风已经吹向了每一个人,在这篇文章中我们一起来聊一聊 AI 图像生成的原理以及未来。
作为一个非职业的摄影爱好者,我通常会在 Instagram 上面搜罗各种各样的优质图片并将其放进我的收藏夹。其中,有一位我关注了很久的德国摄影师,他的作品有很多值得我学习的地方。
在经历了一段时间因 ChatGPT 带来的职业发展焦虑后,我开始有意无意地在生活中关注 AI 相关的消息。当我回看我的收藏夹,我惊讶地发现发现自今年一月份以来,这位德国摄影师发布的大部分照片都是由 AI 生成的。而我在收藏和欣赏这些图片的时候,居然一点也没有察觉出这些图片是 AI 制作的。

图片来源:Instagram freaksplace,由 AI 生成
所以我想在这篇文章里和大家一起聊一聊 AI 图像生成的原理、过程,以及我是怎么看待 AI 图像生成这股浪潮的。
AI 生成图片的原理
生成与转换:AI 绘画的两大核心算法
AI 绘画的原理并不是简单地将多个图片数据拼接在一起所生成的图像。与 ChatGPT 的本质逻辑相似,AI 绘画生成图片的过程是通过对训练数据的学习,让 AI 模型能够理解和提取图像的基本特征、结构和样式。然后,根据给定的描述或关键词,尝试在新的图像中融合和组合这些特征,以生成与输入相关的图像。完成这一任务的两种核心算法分别是生成模型和转换模型。
生成模型:生成对抗网络(GAN)
生成模型是一种能够根据给定条件生成新数据的算法。在 AI 绘画中,生成模型通常采用生成对抗网络(generative adversarial networks, GAN),其中包括两个神经网络:一个生成器和一个判别器,生成器负责生成新图像,判别器则评估生成器的性能。通过反复训练生成器和判别器,生成模型可以逐步提高生成图像的质量。
简单来说,生成器负责学习并尝试生成新的图像,而判别器则会对生成的图像进行判定。这种生成器和判别器之间的竞争与对抗关系促使生成器不断改进其生成能力,从而创造出更加逼真和高质量的图像。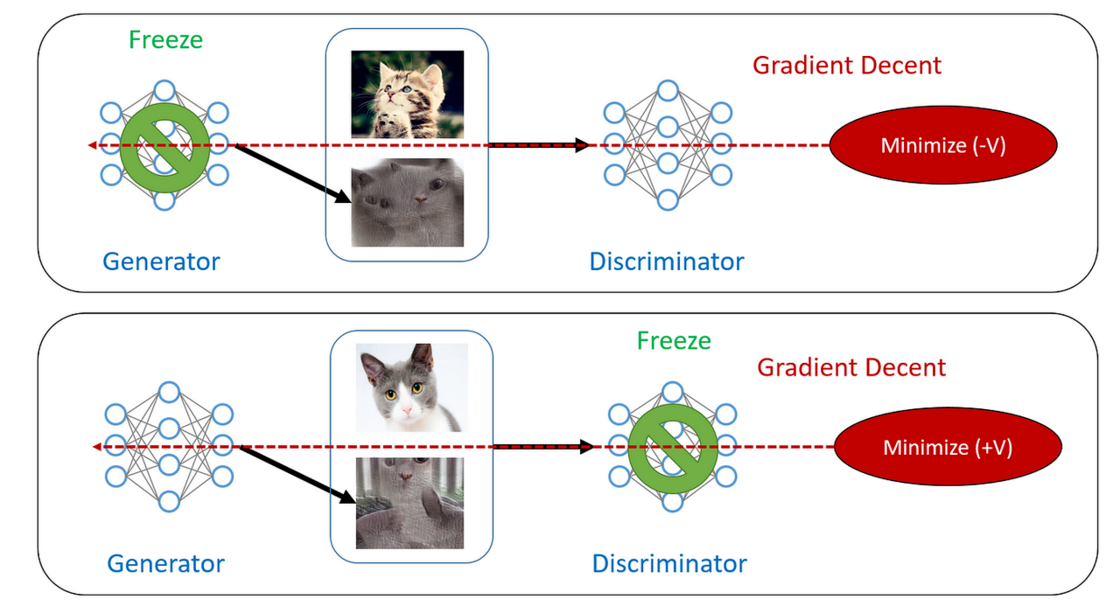
除了 GAN 对抗模型以外,还有一种扩散模型(Diffusion)同样可以生成图像。
扩散模型的核心思想是通过向原始图像添加噪声,将其扩散到一个噪声图像,然后逐步从噪声图像中还原原始图像。在接受训练后,模型学会接受用户提供的文本提示,创建低分辨率图像,然后逐渐添加新细节以变成完整图像。
转换模型:卷积神经网络(CNN)
转换模型用于将输入图像转换成另一种风格的图像。在 AI 绘画中,转换模型通常采用卷积神经网络(convolutional neural network, CNN)实现。
这些模型通过学习如何将输入图像转换为特定的风格,例如梵高的星空或毕加索的风格。模型的训练通常依赖于拥有大规模图片数据的训练数据集,例如 ImageNet 和 COCO 数据集。
以 ImageNet 数据集为例,目前最新的版本是 ImageNet-21K,该数据集包含 21841 个物体类别,共有超过 2100 万张图片。其中,训练集包含超过 1400 万张图片,验证集包含超过 5 万张图片,测试集包含超过 10 万张图片。
ImageNet 的物体类别包括各种动物、物体和场景等,如动物类别包括「狗」「猫」「鸟」等,物体类别包括「汽车」「椅子」「电视」等,场景类别包括「海滩」「山脉」「公园」等。每个物体和场景类别都有大量的图片来支持模型的训练和评估,这些图片都是高分辨率的彩色图片,具有不同的角度、光照、背景等多种变化。
图像字幕技术:让 AI「看懂」图片
图像字幕技术(Image Captioning)指的是通过深度学习算法生成图像文本描述的过程。
图像字幕的过程通常涉及将图像输入神经网络,该网络提取相关的视觉特征,然后生成描述这些特征的单词序列。神经网络是在大量图像及其相应字幕的数据集上训练的,使用卷积神经网络进行图像分析,并使用递归神经网络(recurrent neural network, RNN)生成文本。
简单来说,就是让计算机「看懂」一张图片,然后自动为这张图片生成一句话的描述。神经网络会通过对图像中的物体、场景、动作等元素进行识别和分析,并利用语言模型将图像的内容转化为文本。例如,对于以下这张图片,AI会生成类似于「一只 狗 在 草地 上 奔跑」的描述。

当然,这只是举了一个简单的例子,而计算机提取的特征比我们想象的要多得多。比如,对于图二中奔跑的边牧,计算机在使用图像字幕技术时,不仅会对图像进行特征提取,还会识别出狗的形状、大小、肢体运动等特征,并将其转换为文字描述。
在训练过程中,图像字幕技术会接收大量的图像,如模糊的边牧、有残影的边牧、歪头撅屁股的边牧。经过大量训练后,技术可以生成相关的文字标签,形成准确的判断和生成,从而实现真正的「看懂」效果。
AI 如何将图像中提取出的文字特征组合在一起?
事实上,文字、词语或是诗句等文字描述对于 AI 来说还是太过于抽象,它们目前来说并不能像人一样理解。这时就需要将文字、文本、词汇等非连续性数据转化为计算机可以处理的连续型数据1。
简而言之,这意味着将不可计算和非结构化的文字描述、词汇等转换为可计算和结构化的嵌入向量。
嵌入向量(Embedding Vectors)是一种技术,可以将离散符号(例如单词、标签等)转换为连续的实数向量。通过学习得到的嵌入向量,计算机能够更好地理解符号之间的关系,从而实现各种任务,例如语言翻译、情感分析、推荐等,并保留符号之间的语义相似性。
常见的词嵌入向量模型用于表示单词的语义信息。例如,Google 的 Word2Vec 模型可以给每个单词分配一个固定长度的向量表示,这个长度可以自行设定。两个单词向量之间的夹角值可以作为它们之间关系的衡量。下面是一些单词和它们对应的嵌入向量的 2D 可视化示例,可以将它们想象为空间中的三维或多维坐标来更容易理解。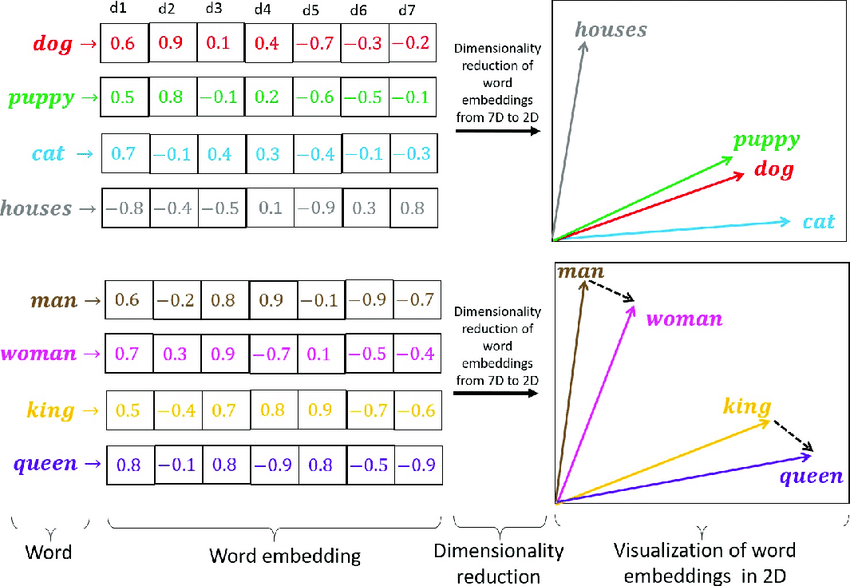
两个单词向量之间的夹角值可以作为词语之间关系的衡量
比如「狗」「猫」这两个词在 Word2Vec 中的嵌入向量非常接近,这两个单词的词向量(单词所在的点与原点连接的直线所在的向量)就离得比较近。这样做的好处就是同义词或者同语境的词之间的向量就会很接近,可以保留文章的语义。
AI 绘画对于处理嵌入向量的逻辑流程与 ChatGPT 等大型语言模型有相似之处,根据图像特征来寻找匹配相似词的原理是相同的。
AI 如何生成图像?
AI 生成图像的原理其实并不复杂。在生成图片的过程中,生成器会首先生成一个较低分辨率的图像,然后逐渐增加细节和复杂性。每一层神经网络都会处理不同级别的特征,从低级特征(如边缘和纹理)到高级特征(如物体和场景的组成)。
生成器的神经网络层之间存在连接关系,这些连接使得生成器可以在不同层次上对特征进行组合。例如,生成器可能会先确定一个场景的大致布局,然后在这个布局的基础上添加物体和其他细节。在整个生成过程中,生成器会根据输入的描述或关键词调整特征的组合,以创造出与输入相关的图像。
下面通过一个简化的例子来说明生成器是如何将输入的文本等语言转换为一张包含多个特征的图像。
假设我们使用一个 AI 绘画模型,输入的文本描述是「一座雪山下的小木屋」,希望生成器能够根据这个描述创建一张真实的图像。当我们输入「A cabin under a snow mountain」这句话后,AI 会将文本描述转换为嵌入向量。类似于拆分词语,这句话会首先被转换为「一座」「雪山」「下」「小木屋」,并捕捉了描述中的语义信息,并将其转换为计算机可以处理的数值形式。
首先是低级特征生成。生成器接收到嵌入向量后,开始生成图像。在神经网络的较低层,生成器会处理低级特征,例如边缘、颜色和纹理。在这个阶段,生成器会确定雪山和小木屋的大致轮廓、颜色和纹理。
接下来是高级特征生成。随着神经网络层数的增加,生成器开始处理更高级的特征,例如:物体形状和场景组成。在这个阶段,生成器会根据输入的描述,在画面中放置雪山和小木屋,并确定它们之间的相对位置和大小。
紧接着就是细节添加。在神经网络的较高层,生成器会进一步细化图像,添加更多细节。例如,生成器可能会在小木屋上添加窗户、门和烟囱,在雪山上添加雪的纹理等。
这张图的烟囱和楼梯的位置生成错误,判别器工作——修改烟囱的位置
最后完成图像。经过生成器的多层神经网络处理,最后得到一张包含雪山和小木屋的图像。这张图像将包含从低级到高级的各种特征,使其看起来既真实又具有视觉吸引力。

另辟蹊径的生成方式
OpenAI 的 DALL-E2 则提供了 AI 生成图片另一种方式,即通过设定蒙版与区域来合成图片。简单一点来讲,就是通过「傻瓜式」的操作让普通人也能完成图片合成的效果。
以这张图为例,我觉得这个小房子太古典了,我想要现代一点的景观,于是我就用画笔工具将这个小房子的区域抠掉,AI 会在这片被扣掉的区域帮我重新生成图片,例如画一个现代一点的建筑。

又比如,我觉得 AI 生成的方形图像不符合我的要求,想要 AI 帮我补充一下画幅,加一点极光和星空进去,我只需要再拖一个蒙板进去,并输入一些关键词就可以了。

那么 AI 是摄影的未来吗?
AI 生成图片的进步从未停止,从最初的「一眼假」到现在的以假乱真。除非主题比较新颖和魔幻,AI 生成的图片已经足以商业用途并且能够达到以假乱真的效果。
我的本职工作并不是一名职业摄影师,与大多数人一样,我的日常工作是从事数据处理,工作繁忙而且劳累。对于一个刚入行的新人来说,分配给我的任务难度不是很大,其中大多数都是简单且具有机械重复性的劳作。
在我的工作中,拥有 ChatGPT 的提升是巨大的,极大地改变了我的工作流程。对于一个只了解编程皮毛的外行人来说,在重复而又繁琐的工作中,我可以毫不费力地使用它来帮助我编写程序以实现半自动化的工作流程。
对于摄影行业也是一样,通过熟练地使用 AI 技术,足不出户的我一天之内就可以生成几十张还算不错的创意图片。对于没有绘画和艺术技巧的我,现在也可以发挥自己的想象力,创作出曾经只存在于我的大脑中的构想。这些想法有些超越了现实摄影的界限,有些超越了时间的跨度。曾经看似无法实现的照片和图像作品,现在只需一瞬间就可以创造出来。



AI 创造的图片影调很好,色彩几乎完美。如果将这些图片发布在 AI 绘图出现之前的社交媒体软件上,肯定会获得大量点赞和好评。
但随着 AI 图片创意产业的加速发展,我相信很多人对于图片质量的评判标准也将改变。这自然也带来了新的问题,AI 生成的摄影作品是否能够真正地称之为摄影作品?对于未来高质量图片的爆炸式增长,我们又该以何种标准和审美来评判一张照片是否为好照片?相机实拍的「真实」与 AI 生成的「虚拟」的界限又在哪里?
在 AI 绘画出现之前,我们依靠 PS 等软件也可以完成这样简单的合成图片,卷积神经网络这种算法早已被用于 PS 的多种工具中。
举例来说,如果我想修补一个图像中并不存在的区域,填充工具和修补图章会分析图像中的纹理、颜色和其他特征,找到与需要修补的区域相似的其他区域进行特征提取和匹配,然后将这些相似区域的像素值与需要修补的区域像素值进行融合,以实现自然且无缝的修补效果。另外,手机上早已应用了 AI 算法,帮助我们实现影像质量的大幅提升。在我们已经拥抱算法带来便利的时代,我们又有什么理由拒绝 AI 生成的摄影作品呢?
想要区分所谓「真实」和「虚拟」的摄影艺术,恐怕这个界限早已模糊了。对于「人」的摄影来说,商业或非商业的照片更多的是记录生活和捕捉那些令人感动、震撼或悲伤的瞬间。每个影像都是一个故事的载体,传达着拍摄者的情感和观点。以风光摄影师为例,拍摄这样的图片可能需要提前在谷歌地球上规划好拍摄角度和机位,然后在野外蹲守一两天等待合适的天气和时间。得到满意的 RAW 文件之后,后期制作也需要费点心思才能修出惊艳的效果。
AI 逐渐打破了创作摄影作品的繁琐过程和普通人难以逾越的技术鸿沟,随着摄影技术的下沉,在可预见的未来,更多的普通人可以轻松地拍摄或制作高质量的照片,无需实际经历那些艰难的时刻或注入情感,也能获得同样令人愉悦或震撼的结果。
在未来,不受技术和器材限制的时代,也许最珍贵的摄影产物不是图片,而是创意和思想。

若有收获,就点个赞吧
0 人点赞
