目标:
读取数据,以“豆瓣评分”为标准,看看电影评分分布,及烂片情况
要求:
① 读取数据“moviedata.xlsx”
② 查看“豆瓣评分”数据分布,绘制直方图、箱型图
③ 判断“烂片标准” → 这里以上四分位数(该样本中所有数值由小到大排列后第25%的数字)评分为“烂片标准”
⑤ 筛选出烂片数据,并做排名,找到TOP20
提示:
① 读取数据之后去除缺失值
导入库
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings('ignore')from bokeh.plotting import figure, show, output_filefrom bokeh.models import ColumnDataSource, HoverTool
数据读取
拿到数据(moviedata.xlsx)以后,首先要做的是提取数据,并去除评分小于0 的数据,代码如下:
import osos.chdir('C:\\Users\\RaingEye\\Desktop\\数据分析项目实战\\国产烂片深度揭秘\\')df = pd.read_excel('moviedata.xlsx') #加载数据df = df[df['豆瓣评分'] > 0] #去掉豆瓣评分小于0的数据
查看数据(豆瓣评分情况)
print(df['豆瓣评分'].describe())#做描述性统计df['豆瓣评分'].plot.hist(bins = 50, color = 'green', alpha = 0.6, figsize = (10, 4))#绘制柱状图df['豆瓣评分'].plot.box(vert = False, figsize = (10, 4), grid = True)#绘制箱型图#初步判断
上方代码,可以全部在Spyder的交互式工具栏中进行,如图所示: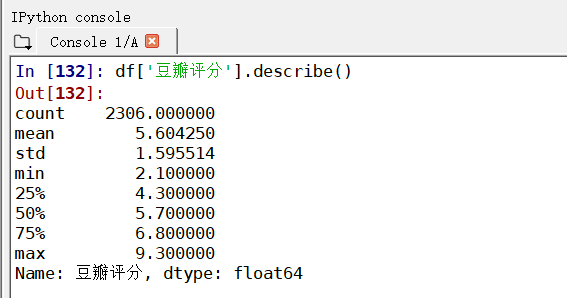
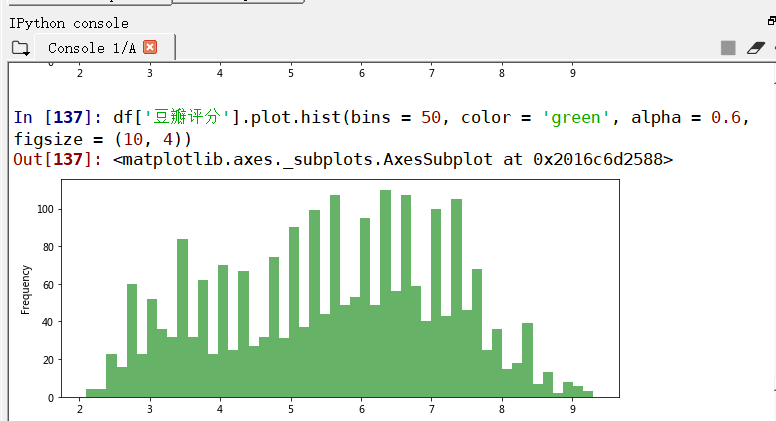
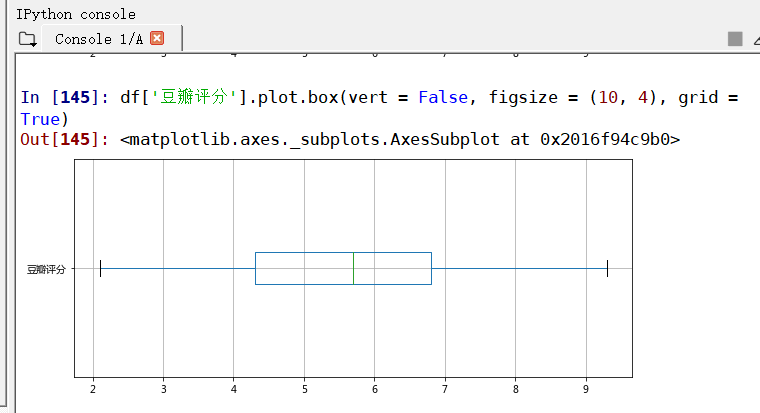
KS检验
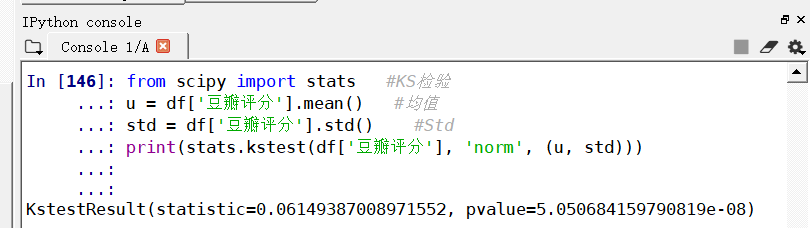
作出箱型图和柱状图、描述性统计、以及经过初步判断以后,下一步需要确认该数据是否服从正态分布,如下图代码:
from scipy import stats #KS检验u = df['豆瓣评分'].mean() #均值std = df['豆瓣评分'].std() #Stdprint(stats.kstest(df['豆瓣评分'], 'norm', (u, std)))#KS检验,statistic值大于0.05,表明其值为正态分布#norm是指做正太检验
烂片排名前TOP20
#根据以上实验,将4.3分作为一个烂片的评判标准data_lp = df[df['豆瓣评分']<4.3].reset_index()#reset_index()可以还原索引,重新变为默认的整型索引,即数据更整齐lp_top20 = data_lp[['电影名称', '豆瓣评分', '主演', '导演']].sort_values(by = '豆瓣评分').iloc[:20].reset_index()del lp_top20['index']
根据上述结果的值可以表明,‘statistic’的值大于0.05,表明电影数据符合正态分布,烂片的评分标准为“小于4.3,”,根据结果筛选出烂片排名前20的电影数据,上方代码,依旧可以在交互式工具中实现,结果如图: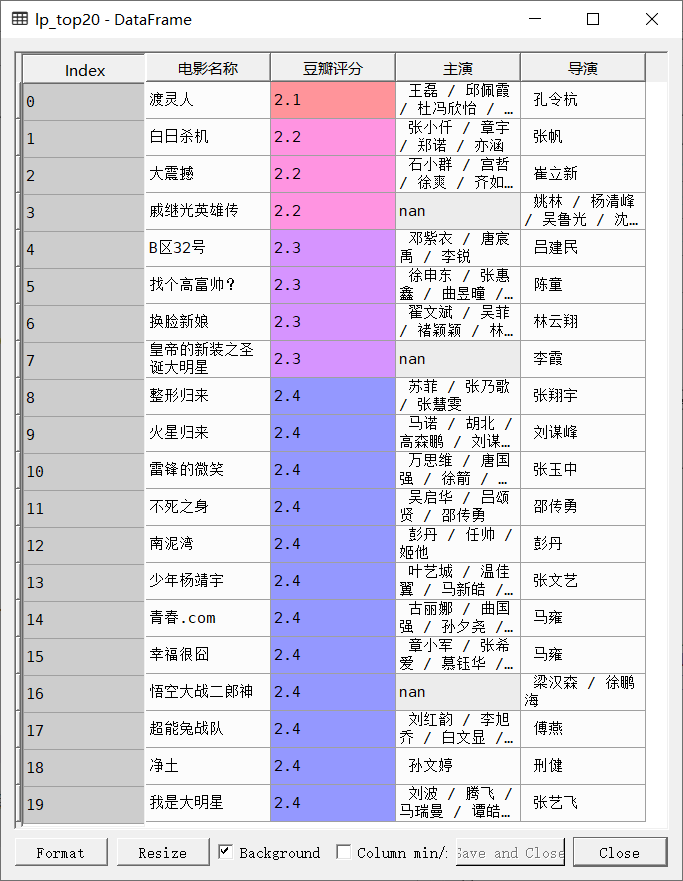

若有收获,就点个赞吧
0 人点赞
