不同导演每年电影产量情况是如何的?
要求:
- 通过“上映日期”筛选出每个电影的上映年份
- 查看不同导演的烂片比例、这里去除掉拍过10次电影以下的导演
- 查看不同导演每年的电影产量制作散点图 → 横坐标为年份,纵坐标为每年电影平均分,点大小该年电影数量
- 注意要删除“上映日期”中的空格字符
- 绘制图表时,分开建立数据绘制
导入库
import numpy as npimport pandas as pdimport matplotlib.pyplot import pltimport warningswarnings.filterwarnings('ignore')from bokeh.plotting import figure, show, output_filefrom bokeh.models import ColumnDataSource
电影上映时间整理
根据题目要求,我们首先筛选数据,步骤如下:
- 从‘df’中筛选出导演不为空的数据,将字段‘电影名称’,‘导演’,‘豆瓣评分’,‘上映日期’的数据存储到变量‘df_year’中
- 去除‘df_year’变量中字段‘上映日期’为空的数据
- 将变量‘df_year’中字段‘上映日期’数据的空格去掉
- 将变量‘df_year’中字段‘上映日期’数据中的年份筛选出来,存储在变量‘df_year’的‘year’字段中
- 筛选出上映日期在2000年及以后的数据
- 将‘df_year’数据中字段‘year’的数据由字符串转化为数据
- 筛选出2006年以后上映的数据
```python
‘’’
(1)电影上映时间整理
‘’’
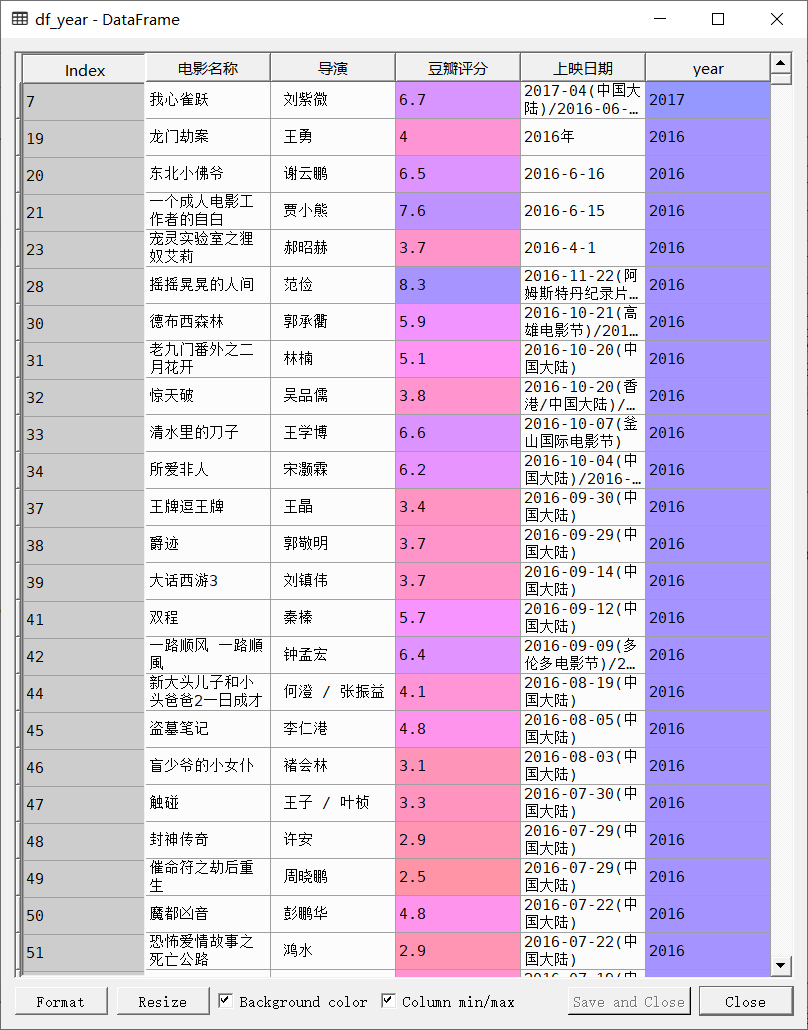
df_year= df[[‘电影名称’,’导演’, ‘豆瓣评分’, ‘上映日期’]][df[‘导演’].notnull()]
df_year = df_year[df_year[‘上映日期’].notnull()]
筛选导演和上映日期字段都不为空的数据
df_year[‘上映日期’] = df[‘上映日期’].str.replace(‘ ‘, ‘’) df_year[‘year’] = df_year[‘上映日期’].str[:4]
清洗数据,提起上映日期的年份
df_year = df_year[df_year[‘year’].str[0] == ‘2’]
筛选上映日期在2000之后的数据
df_year[‘year’] = df_year[‘year’].astype(np.int)
将year字段的数据,由字符串转化为数字
df_year = df_year[df_year[‘year’]>2006]
筛选出2006年以后上映的数据
---<a name="Oneyc"></a># 筛选导演筛选出‘df_year’数据中所有的导演,并且将重复的导演名称去掉,代码如下:```python'''(2)筛选导演'''dircetorlst = []for i in df_year['导演'].str.replace(' ', '').str.split('/'):dircetorlst.extend(i)dircetorlst = list(set(dircetorlst))

查看不同导演的烂片比例
筛选出2007~2017年之间,拍摄电影数量超过10部的导演,并计算其10内拍摄电影的数量,以及拍摄电影的烂片比例,代码如下:
'''
(3)查看不同导演的烂片比例
'''
lst_lp_pre = []
for i in dircetorlst:
datai = df_year[df_year['导演'].str.contains(i)]
if len(datai) > 10:
dic_dir_lp = {}
lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai )
dic_dir_lp['dir'] = i
dic_dir_lp['dircount'] = len(datai)
dic_dir_lp['dir_lp_pre'] = lp_pre_i
lst_lp_pre.append(dic_dir_lp)
df_dir_lp = pd.DataFrame(lst_lp_pre)
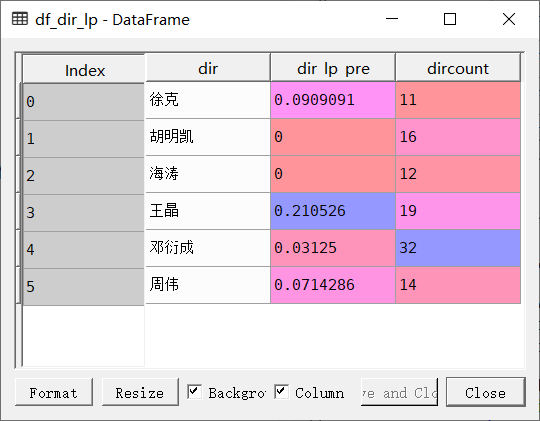
不同导演的电影产量及电影均分
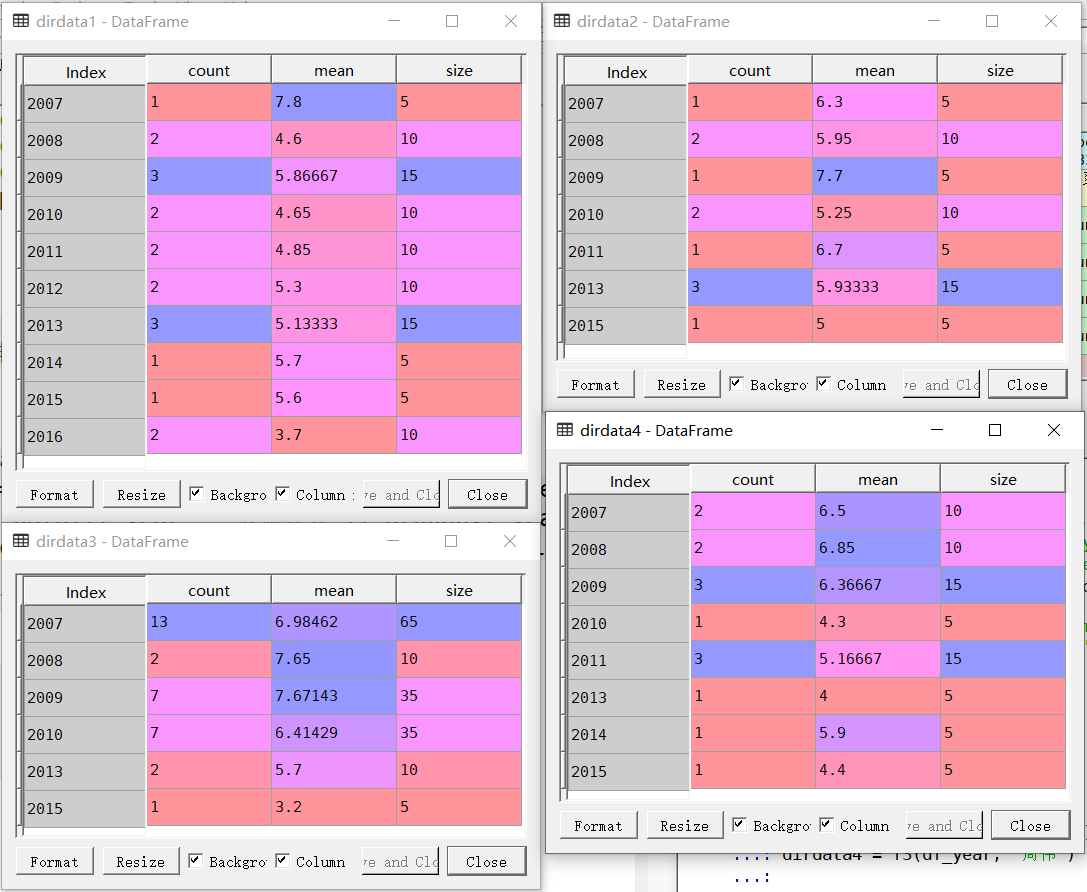
接下来我们要分析一下,不同导演每一年拍摄的电影数量,以及该年份电影豆瓣评分的平均数,代码如下:
'''
(4)不同导演的电影产量及电影均分
'''
def f3(data, diri):
datai = data[data['导演'].str.contains(diri)]
data_moviecount = datai[['year', '电影名称']].groupby('year').count()
data_scoremean = datai[['year', '豆瓣评分']].groupby('year').mean()
df_i = pd.merge(data_moviecount, data_scoremean, left_index = True, right_index = True)
df_i.columns = ['count', 'mean']
df_i['size'] = df_i['count']*5
return df_i
dirdata1 = f3(df_year, '王晶')
dirdata2 = f3(df_year, '徐克')
dirdata3 = f3(df_year, '邓衍成')
dirdata4 = f3(df_year, '周伟')
Bokeh制图
'''
Bokeh制图
'''
from bokeh.models.annotations import BoxAnnotation
#导入BoxAnnottation
from bokeh.models import HoverTool
hover = HoverTool(tooltips = [
('该年电影均分', '@score'),
('该年电影产量', '@count')
]) #设置标签内容
output_file('pic2.html')
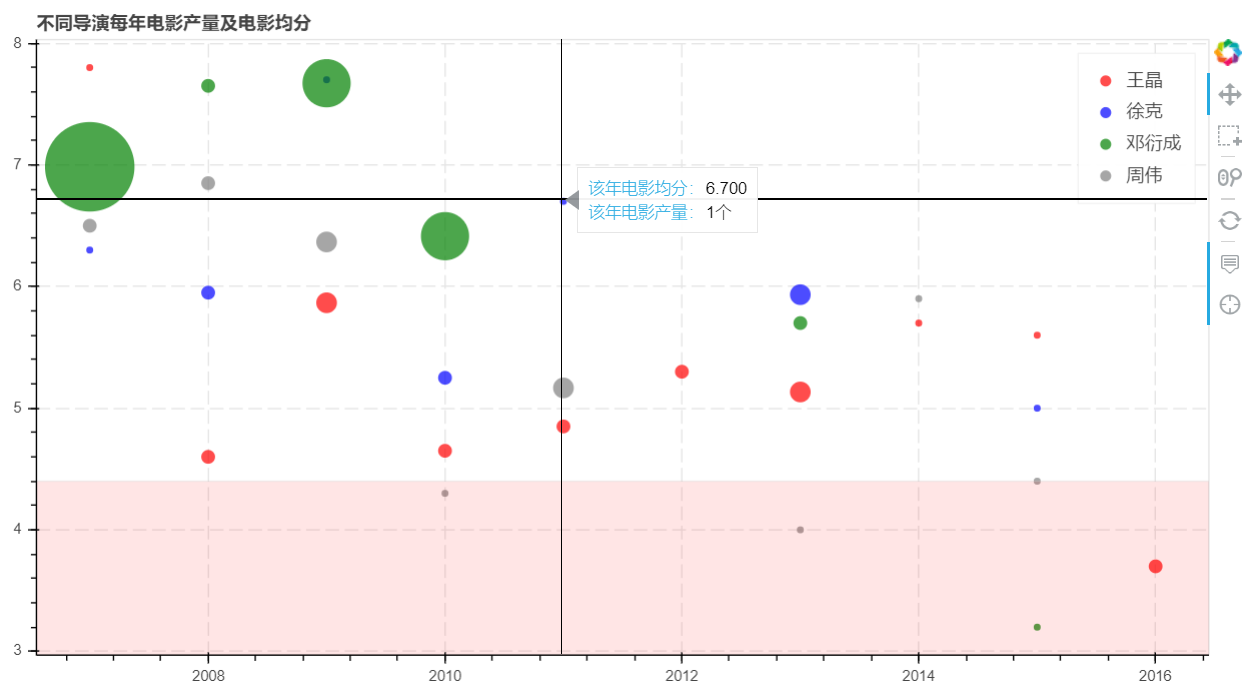
p = figure(plot_width = 900, plot_height = 500, title = '不同导演每年电影产量及电影均分',
tools = [hover, 'reset,xwheel_zoom,pan,crosshair,box_select'])
#构建绘图空间
source1 = ColumnDataSource(dirdata1)
p.circle(x = 'year', y = 'score', source = source1, size = 'size', legend = '王晶',
fill_color = 'red', fill_alpha = 0.7, line_color = None)
#绘制散点图1
source2 = ColumnDataSource(dirdata2)
p.circle(x = 'year', y = 'score', source = source2, size = 'size', legend = '徐克',
fill_color = 'blue', fill_alpha = 0.7, line_color = None)
#绘制散点图2
source3 = ColumnDataSource(dirdata3)
p.circle(x = 'year', y = 'score', source = source3, size = 'size', legend = '邓衍成',
fill_color = 'green', fill_alpha = 0.7, line_color = None)
#绘制散点图3
source4 = ColumnDataSource(dirdata4)
p.circle(x = 'year', y = 'score', source = source4, size = 'size', legend = '周伟',
fill_color = 'gray', fill_alpha = 0.7, line_color = None)
#绘制散点图4
bg = BoxAnnotation(top = 4.4, fill_alpha = 0.1, fill_color = 'red')
p.add_layout(bg)
#绘制烂片分割区域
p.xgrid.grid_line_dash = [10, 4]
p.ygrid.grid_line_dash = [10, 4]
p.legend.location = 'top_right'
#设置其他参数
show(p)

若有收获,就点个赞吧
0 人点赞
