题目:
要求:
- 以之前1万男+1万女实验的结果为数据
- 按照财富值、内涵值、外貌值分别给三个区间,以区间来评判“男女类型”
- 高分(70-100分),中分(50-70分),低分(0-50分)
- 按照此类分布,男性女性都可以分为27中类型:财高品高颜高、财高品中颜高、财高品低颜高、… (财→财富,品→内涵,颜→外貌)
bokhe制图
注意绘图的数据结构
- 这里散点图通过xy轴定位数据,然后通过设置颜色的透明度来表示匹配成功率
- alpha字段为每种类型匹配成功率标准化之后的结果,再乘以一个参数
- data[‘alpha’] = (data[‘chance’] - data[‘chance’].min())/(data[‘chance’].max() - data[‘chance’].min())*8
导入库
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport osimport time# 导入时间模块import warningswarnings.filterwarnings('ignore')# 不发出警告from bokeh.io import output_notebookoutput_notebook()# 导入notebook绘图模块from bokeh.plotting import figure,showfrom bokeh.models import ColumnDataSource,HoverTool# 导入bokeh绘图模块
数据清洗
首先在这里,我们作分析使用的数据是之前1万男性与1万女性样本最后的结果数据match_success1,同样的我们需要将match_success1数据复制后,使用样本数据进行操作。然后通过Pandas的merge方法合并数据,得到男女的各项分值,并筛选出分析作图所需要的字段,代码如下:
graphdata2 = match_success1.copy()graphdata2 = pd.merge(graphdata2,sample1_m1,left_on = 'm',right_index = True)graphdata2 = pd.merge(graphdata2,sample1_f1,left_on = 'f',right_index = True)# 合并数据,得到成功配对的男女各项分值graphdata2 = graphdata2[['m','f','apperance_x','character_x','fortune_x','apperance_y','character_y','fortune_y']]# 筛选字段
筛选得到所需的数据以后,我们需要对数据进行进一步处理,为数据设置三个区间,分别是高分(70-100分),中分(50-70分),低分(0-50分),然后根据不同字段的不同值,将数据按照财富、内涵、颜值的不同阶段划分成27个类型,代码如下:
graphdata2['for_m'] = pd.cut(graphdata2['fortune_x'],[0,50,70,500],labels = ['财低','财中','财高'])graphdata2['cha_m'] = pd.cut(graphdata2['character_x'],[0,50,70,500],labels = ['品低','品中','品高'])graphdata2['app_m'] = pd.cut(graphdata2['apperance_x'],[0,50,70,500],labels = ['颜低','颜中','颜高'])graphdata2['for_f'] = pd.cut(graphdata2['fortune_y'],[0,50,70,500],labels = ['财低','财中','财高'])graphdata2['cha_f'] = pd.cut(graphdata2['character_y'],[0,50,70,500],labels = ['品低','品中','品高'])graphdata2['app_f'] = pd.cut(graphdata2['apperance_y'],[0,50,70,500],labels = ['颜低','颜中','颜高'])# 指标区间划分
由于后期的作图,我们需要将每一个男性数据,或者女性数据的财富、颜值与内涵三个字段,其数据处于的范围合并在一起,例如“财低品高颜高”这种类型的数据,因此我们需要将每一条数据的区间描述转换成字符串,然后将其合并,并筛选出作图所需的字段,代码如下:
graphdata2['type_m'] = graphdata2['for_m'].astype(np.str) + graphdata2['cha_m'].astype(np.str) + graphdata2['app_m'].astype(np.str)graphdata2['type_f'] = graphdata2['for_f'].astype(np.str) + graphdata2['cha_f'].astype(np.str) + graphdata2['app_f'].astype(np.str)graphdata2 = graphdata2[['m','f','type_m','type_f']]# 筛选字段

匹配成功率计算
在这一步是为了计算每一种类型匹配成功的概率,例如“财低品高颜高”这种类型的男性与“财中品中颜中”匹配成功的概率,同时为了后期做散点图时,匹配的称功率越高,点的颜色越深,在此还需要做一个标准化处理用来设置点的透明度,代码如下:
# 匹配成功率计算success_n = len(graphdata2) #匹配成功的数据长度success_chance = graphdata2.groupby(['type_m','type_f']).count().reset_index()#统计每一种类型匹配成功的数量success_chance['chance'] = success_chance['m']/success_n #计算每一种类型,匹配成功的成功概率success_chance['alpha'] = (success_chance['chance'] - success_chance['chance'].min())/(success_chance['chance'].max() - success_chance['chance'].min())*8 # 设置alpha参数
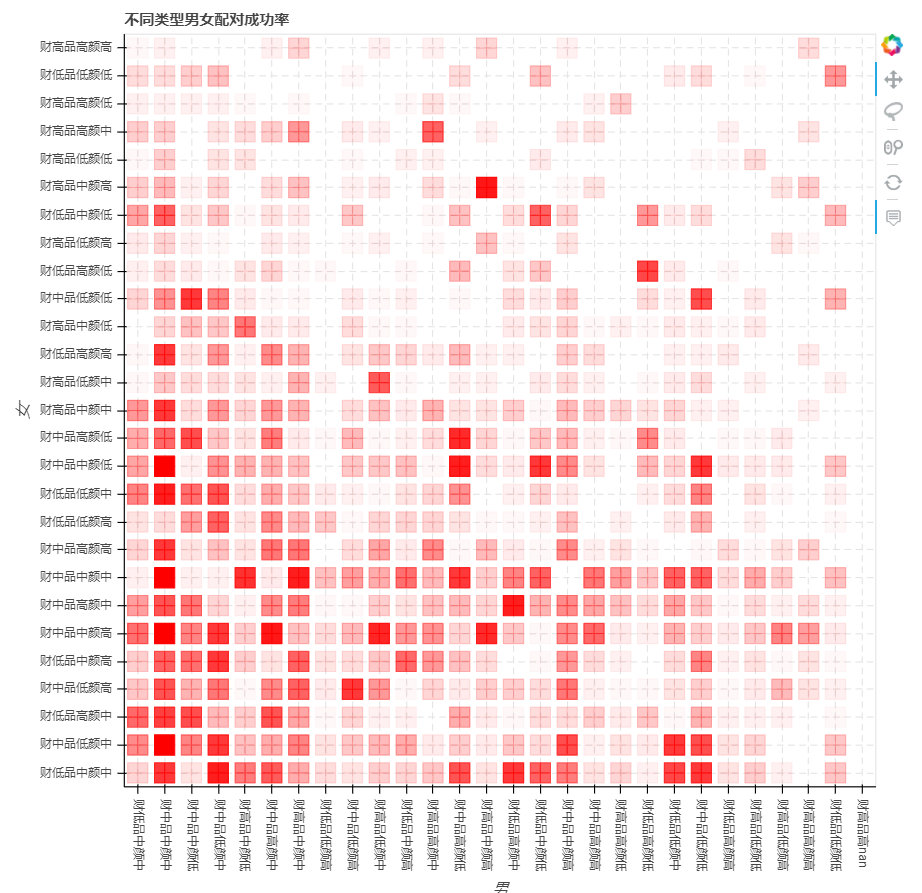
Bokeh绘图
# bokeh绘图output_file('C:\\Users\\RaingEye\\Desktop\\数据分析项目实战\\婚恋配对实验\\pic2.html')mlst = success_chance['type_m'].value_counts().index.tolist()flst = success_chance['type_f'].value_counts().index.tolist()source = ColumnDataSource(success_chance) # 创建数据hover = HoverTool(tooltips=[("男性类别", "@type_m"),("女性类别","@type_f"),("匹配成功率","@chance")]) # 设置标签显示内容p = figure(plot_width=800, plot_height=800,x_range = mlst, y_range = flst,title="不同类型男女配对成功率" ,x_axis_label = '男', y_axis_label = '女', # X,Y轴labeltools= [hover,'reset,wheel_zoom,pan,lasso_select']) # 构建绘图空间p.square_cross(x = 'type_m', y = 'type_f', source = source,size = 18 ,color = 'red',alpha = 'alpha')# 绘制点p.ygrid.grid_line_dash = [6, 4]p.xgrid.grid_line_dash = [6, 4]p.xaxis.major_label_orientation = "vertical"# 设置其他参数show(p)

若有收获,就点个赞吧
0 人点赞
