题目:和什么国家合拍更可能产生烂片?
要求:
①
按照“制片国家/地区”字段分类,筛选不同电影的制片地
②
整理数据,按照“题材”汇总,查看不同题材的烂片比例
提示:
①
删除“制片国家/地区”字段空值的数据
②
删除“制片国家/地区”中不包括“中国大陆”的数据
③
制片地删除“中国大陆”、“中国”、“台湾”、“香港”等噪音数据
④
筛选合作电影大于等于3部以上的国家
筛选分析所需的目标数据
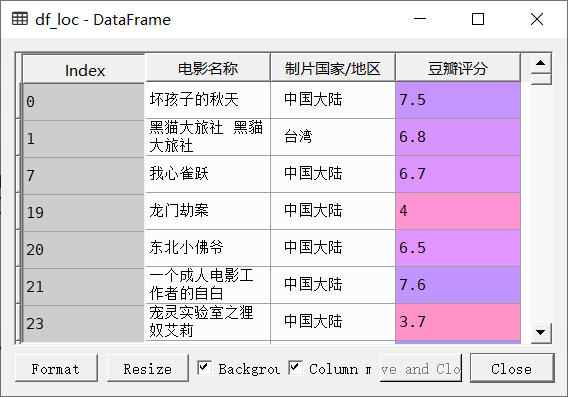
根据题目要求,需要从总的数据‘df’中筛选出‘电影名称’、‘制片国家/地区’和‘豆瓣评分’三个字段的数据进行分析,并且‘制片国家/地区’字段内的值不允许为空值,将其存储在‘df_loc’变量中,代码和结果如下:
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings('ignore')from bokeh.plotting import figure,show, output_filefrom bokeh.models import ColumnDataSource()'''(1)与什么国家合拍更可能产生烂片'''df_loc = df[['电影名称', '制片国家/地区', '豆瓣评分']][df['制片国家/地区'].notnull()]
数据清洗,去除噪音数据
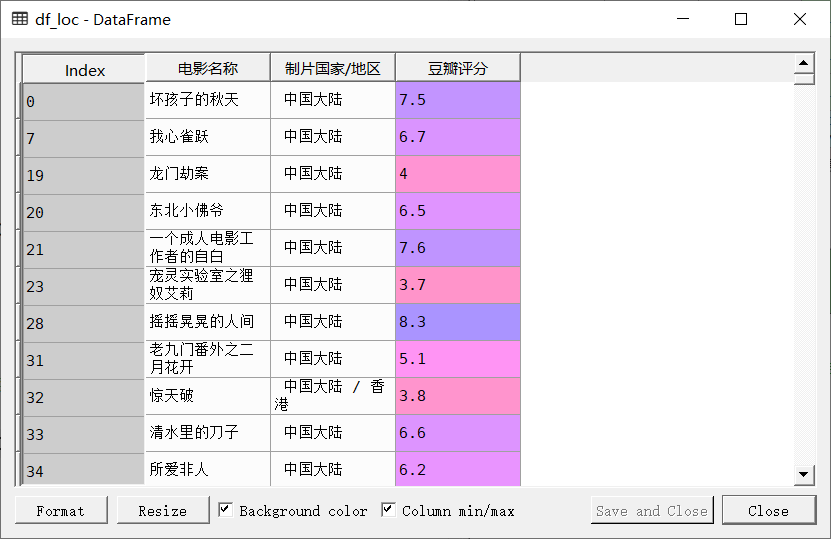
根据题目要求,需要筛选出‘制片国家/地区’字段中包含‘中国大陆’的电影进行分析,在这里使用contains()函数进行筛选,在下方代码中,contains()函数的作用是,将‘制片国家/地区’字段中,有字符‘中国大陆’的数据保留下来,其他的去除,代码结果如下:
df_loc = df_loc[df_loc['制片国家/地区'].str.contains('中国大陆')]
筛选出制片地
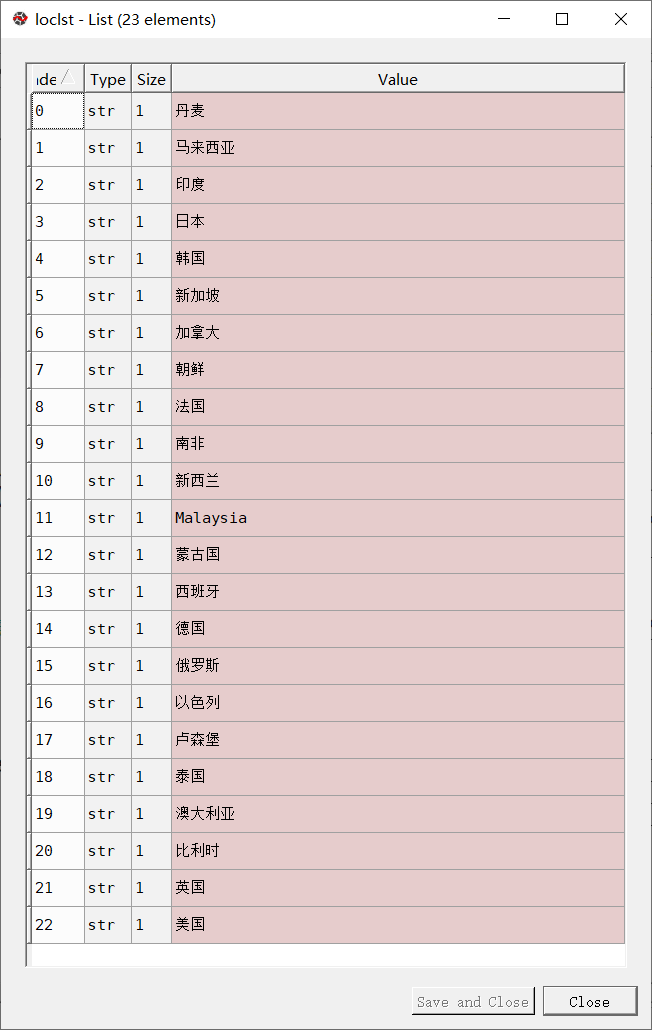
按照题目要求,需要分析中国与其他国家合作产生的烂片比例,因此在得到数据中所有的合作国家后,需要将中国相关的数据全部删除,代码、结果如下:
loclst = [] #存储电影拍摄合作国家for i in df_loc['制片国家/地区'].str.replace(' ','').str.split('/'):loclst.extend(i)loclst = list(set(loclst))#筛选出所有的制片地loclst.remove('中国')loclst.remove('中国大陆')loclst.remove('香港')loclst.remove('台湾')#主要是分析中国与其他国家合作产生的烂片,需要去除中国相关的字符
计算各个国家的烂片比例
希望能够计算得到和每一个国家合作的烂片比例,需要获得与该国家合作的电影数目,合作的电影数目中豆瓣评分小于4.3的电影数据,步骤、代码、结果如下:
- 创建函数‘f2()’用于计算与每一个国家合作的烂片比例
- 设置函数需要的参数为data和loci,分别代表事前准备好的数据和国家
- 定义一个字典,存放电影合作的国家名车、电影数量、以及烂片比例
- 筛选data中字段‘制片国家/地区’数据中包含‘制片国家’loci的数据,将其存储给变量datai
- 通过筛选该国家‘豆瓣评分’<4.3的数据,与该国家参拍的总电影数据进行比较,得到烂片比例
- 将‘制片国家’、该国参拍的‘电影数量’与‘烂片比例’写入字典中,并返回
- 创建一个列表,用于存储函数‘f2()’返回的信息
- 循环取出列表‘loclst’中每一个国家,调用函数‘f2()’,将结果存储在列表中
将结果转化为DataFrame数据格式,并按照要求筛选出合作影片数量大于等于3部以上的影片,然后将其排序,筛选出前20名
```python def f2(data, loci): dic_loc_lp = {} datai = data[data[‘制片国家/地区’].str.contains(loci)]创建字典,筛选该题材的数据
lp_pre_i = len(datai[datai[‘豆瓣评分’]<4.3])/len(datai)
dic_loc_lp[‘locname’] = loci dic_loc_lp[‘loccount’] = len(datai) dic_loc_lp[‘loc_lp_pre’] = lp_pre_i return dic_loc_lp
创建函数
lst_loc_lp = [] for i in loclst: dici = f2(df_loc, i) lst_loc_lp.append(dici)
df_loc_lp = pd.DataFrame(lst_loc_lp) #将其转换为Datafarme数据格式
df_loc_lp = df_loc_lp[df_loc_lp[‘loccount’]>=3] loc_lp_top20 = df_loc_lp.sort_values(by = ‘loc_lp_pre’, ascending = False).iloc[:20] ```


若有收获,就点个赞吧
0 人点赞
