题目:卡司数量是否和烂片有关?
要求:
①
计算每部电影的主演人数
②
按照主演人数分类,并统计烂片率
** 分类:’1-2人’,’3-4人’,’5-6人’,’7-9人’,’10以上’
③
查看烂片比例最高的演员TOP20
提示:
①
通过“主演”字段内做分列来计算主演人数
②
需要分别统计不同主演人数的电影数量及烂片数量,再计算烂片比例
③
这里可以按照明星再查看一下他们的烂片率,比如:吴亦凡、杨幂、黄晓明、甄子丹、刘亦菲、范冰冰….
获取主演人数及其电影数量与烂片数量
根据题目要求,我们分析的目标是“主演数量是否与烂片有关”,因此步骤如下:
- 获取主演人数:
- 首先提取数据中“主演”字段的信息,将其转换为字符串格式,并使用‘split()’函数切片
- 统计切片后主演的数量
- 通过主演人数将影片分类,并计算主演人数相同的电影数量,赋值给变量df_leadrole1
- 通过主演人数将影片分类,筛选出评分小于4.3的影片,并计算主演人数相同的烂片数量,并赋值给变量df_leadrole2
- 将df_leadrole1与df_leadrole2合并,赋值给变量df_leaderole_pre
- 更正df_leaderole_pre数据中columns的名称
'''(2)卡司数量与烂片关系'''df['主演人数'] = df['主演'].str.split('/').str.len()df_leadrole1 = df[['主演人数', '豆瓣评分']].groupby('主演人数').count()df_leadrole2 = df[['主演人数', '豆瓣评分']][df['豆瓣评分']<4.3].groupby('主演人数').count()df_leaderole_pre = pd.merge(df_leadrole1, df_leadrole2, left_index = True, right_index = True)df_leaderole_pre.columns = ['电影数量', '烂片数量']
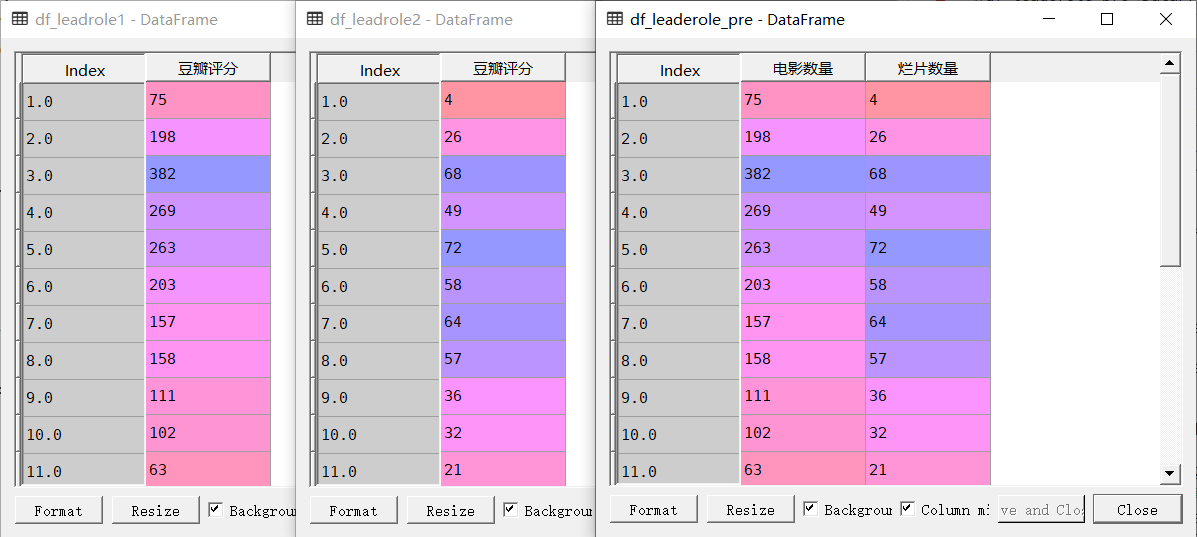
获取不同范围主演人数的烂片比例
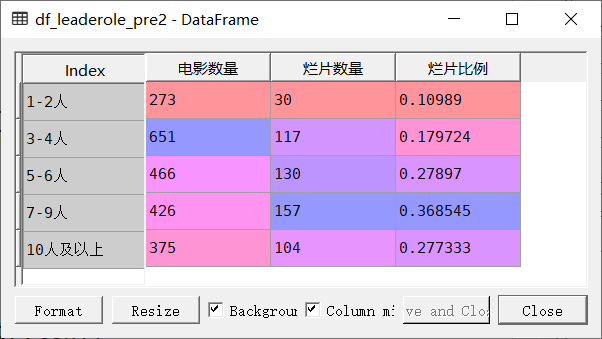
在这一部分,我们需要将主演人分成五部分,分别是’1-2人’、’3-4人’、’5-6人’、’7-9人’、’10人及以上’五个等级,然后统计不同等级电影数量和烂片数量,算出不同人数等级烂片的比例步骤如下:
- 将df_leaderole_pre数据的index索引还原
- 使用Python中的‘cut()’函数,将df_leaderole_pre数据按照’1-2人’、’3-4人’、’5-6人’、’7-9人’、’10人及以上’分级
- 将df_leaderole_pre数据按照主演人数的等级,进行分类,将其赋值给df_leaderole_pre2
将df_leaderole_pre2中的‘烂片数量’除以‘电影数量’,计算烂片比例
df_leaderole_pre.reset_index(inplace = True) #还原索引df_leaderole_pre['主演人数分类'] = pd.cut(df_leaderole_pre['主演人数'],[0,2,4,6,9,100],labels = ['1-2人','3-4人','5-6人','7-9人','10人及以上'])df_leaderole_pre2 = df_leaderole_pre[['主演人数分类', '电影数量', '烂片数量']].groupby('主演人数分类').sum()df_leaderole_pre2['烂片比例'] = df_leaderole_pre2['烂片数量']/df_leaderole_pre2['电影数量']#计算不同主演数量的烂片比例
不同主演的烂片比例
根据需要,我们也可以分析不同主演,其烂片的比例是多少,步骤如下:
首先筛选出主演不为空、豆瓣评分小于4.3的电影,将其存储在变量‘df_role1’中
- 筛选主演不为空的数据,将其存储在变量‘df_role2’中
- 创建一个列表‘leadrolelst’,用于存储演员的数据
- 将所有主演不为空的数据,转换成字符串,将空格替换掉,通过‘/’切分
- 循环去除每一个切分得数据集,将其用‘excend()’函数存储在列表‘leadrolelst’中
- 使用‘set’函数去除‘leadrolelst’中的重复数据
- 创建一个空列表‘lst_role_lp’,用于后续存储数据
- 循环从‘leadrolelst’中取出每一个演员,从总数据中筛选出所有包含该主演的电影,将其存储在变量‘datai’中
- 判断‘datai’数据中电影数量是否超过2部,如果超过,通过筛选出该演员出演电影中,豆瓣评分小于4.3的数据,与‘datai’数据相除求得该演员的烂片率
- 将该演员的名称、出演电影数目、烂片率信息,存储在一个临时的字典‘dic_role_lp’中,并将整个字典用‘append’函数添加到列表‘leadrolelst’中
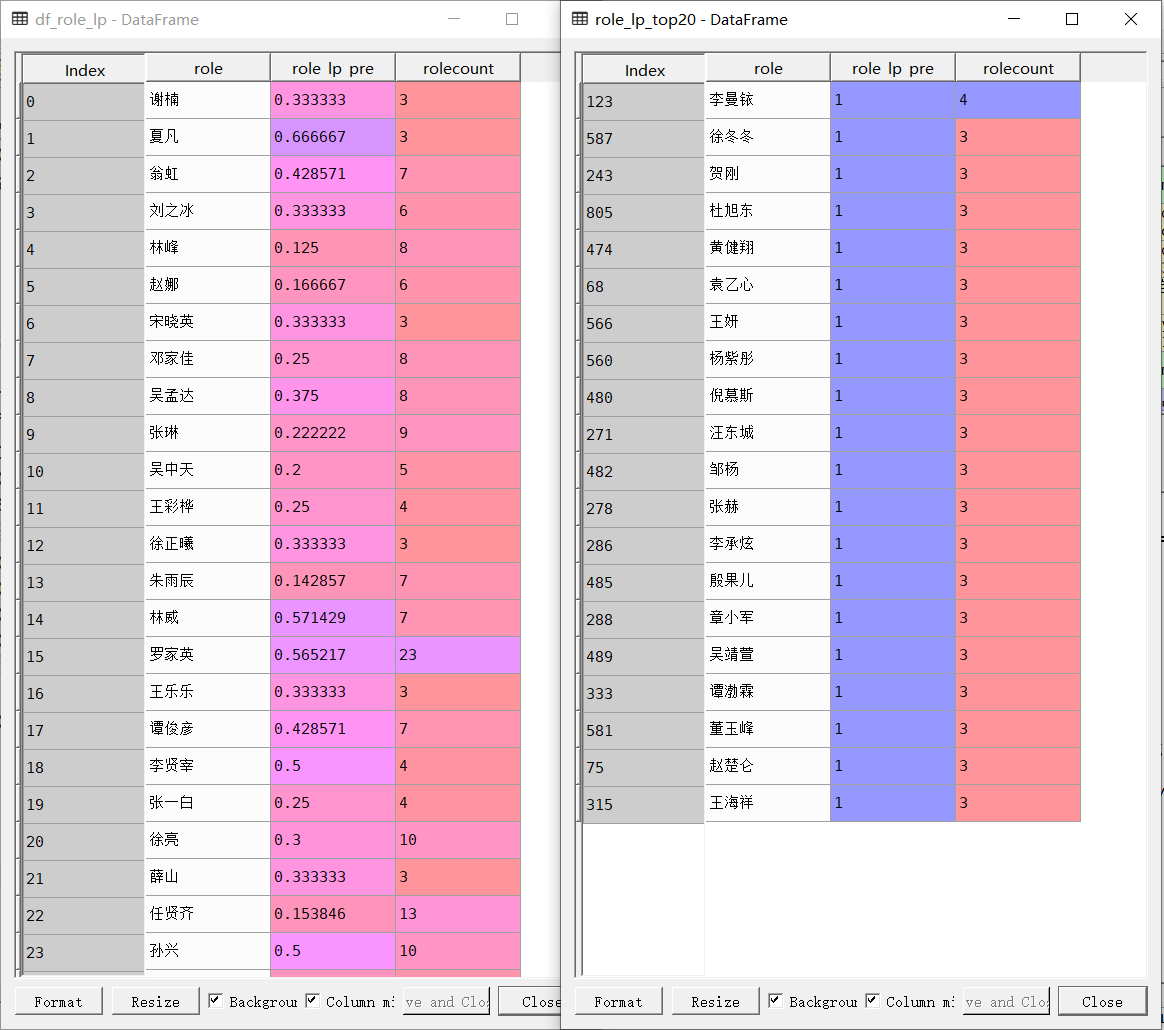
- 将‘leadrolelst’列表转化为DataFrame数据格式,并存储在变量‘df_role_lp’中
- 通过排序筛选出烂片率排名前20的主演 ```python ‘’’ (3)不同主演的烂片比例 ‘’’ df_role1 = df[(df[‘豆瓣评分’]<4.3) & (df[‘主演’].notnull())] #筛选出主演数据不为空的烂片 df_role2 = df[df[‘主演’].notnull()] #筛选出主演不为空的电影 leadrolelst = [] #存储主演数据 for i in df_role1[‘主演’][df_role1[‘主演’].notnull()].str.replace(‘ ‘,’’).str.split(‘/‘): leadrolelst.extend(i)
leadrolelst = list(set(leadrolelst))
列表去重
lst_role_lp = []
创建空字典、空列表
for i in leadrolelst:
datai = df_role2[df_role2[‘主演’].str.contains(i)] #筛选出主演有‘i’的电影
if len(datai)>2:
dic_role_lp = {}
lp_pre_i = len(datai[datai[‘豆瓣评分’]<4.3])/len(datai)
#计算该主演的烂片比例dic_role_lp['role'] = idic_role_lp['rolecount'] = len(datai)dic_role_lp['role_lp_pre'] = lp_pre_ilst_role_lp.append(dic_role_lp)
按照题材遍历数据,得到不同主演的烂片比例
df_role_lp = pd.DataFrame(lst_role_lp)
role_lp_top20 = df_role_lp.sort_values(by = ‘role_lp_pre’, ascending = False).iloc[:20]
```

若有收获,就点个赞吧
0 人点赞
