构建算法函数
内容:
生成99个男性、99个女性样本数据,分别针对三种策略构建算法函数
生成样本数据
- 给男性样本数据,随机分配策略选择 → 这里以男性为出发作为策略选择方
- 尝试做第一轮匹配,记录成功的匹配对象,并筛选出失败的男女性进入下一轮匹配
- 构建模型,并模拟1万男性+1万女性的配对实验
通过数据分析,回答几个问题:
择偶策略评判标准:
- 若匹配成功,则该男性与被匹配女性在这一轮都算成功,并退出游戏
- 若匹配失败,则该男性与被匹配女性再则一轮都算失败,并进入下一轮
- 若同时多个男性选择了同一个女性,且满足成功配对要求,则综合评分高的男性算为匹配成功
- 构建空的数据集,用于存储匹配成功的数据
- 每一轮匹配之后,删除成功匹配的数据之后,进入下一轮,这里删除数据用df.drop()
- 这里建议用while去做迭代 → 当该轮没有任何配对成功,则停止实验
导入库
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport timeimport osimport warningswarnings.filterwarnings('ignore')#不发出警告from bokeh.plotting import figure, show, output_filefrom bokeh.models import ColumnDataSource, HoverTool#导图绘图模块
创建样本数据
根据题目需要,我们需要创建两组数据,分别代表男性和女性,每一组数据99个,过程如下:
- 创建一个函数
- 设置财富值符合指数分布,且标准差控制在15
- 设置外貌值和内涵值符合正态分布,且标准差和平均值分别控制在15和60
- 计算上述三项值的均值
- 生成样本数据
- 分别生成99个代表男性的数据和代表女性的数据
- 并随即为99个男性数据生成三组样本数据数,将数据分成三类
```python def create_sample(n, gender): sample_data = pd.DataFrame({‘fortune’:np.random.exponential(scale = 15, size = n) + 45,
sample_data.index.name = ‘id’ sample_data[‘score’] = sample_data.sum(axis = 1)/3 return sample_data'apperance': np.random.normal(loc = 60, scale = 15, size = n),'character': np.random.normal(loc = 60, scale = 15, size = n)},index = [gender + str(i) for i in range(1, n+1)])
sample_m_test = create_sample(99, ‘m’) sample_f_test = create_sample(99, ‘f’) sample_m_test[‘strategy’] = np.random.choice([1, 2, 3], 99)
创建样本数据
<a name="4Dwws"></a>
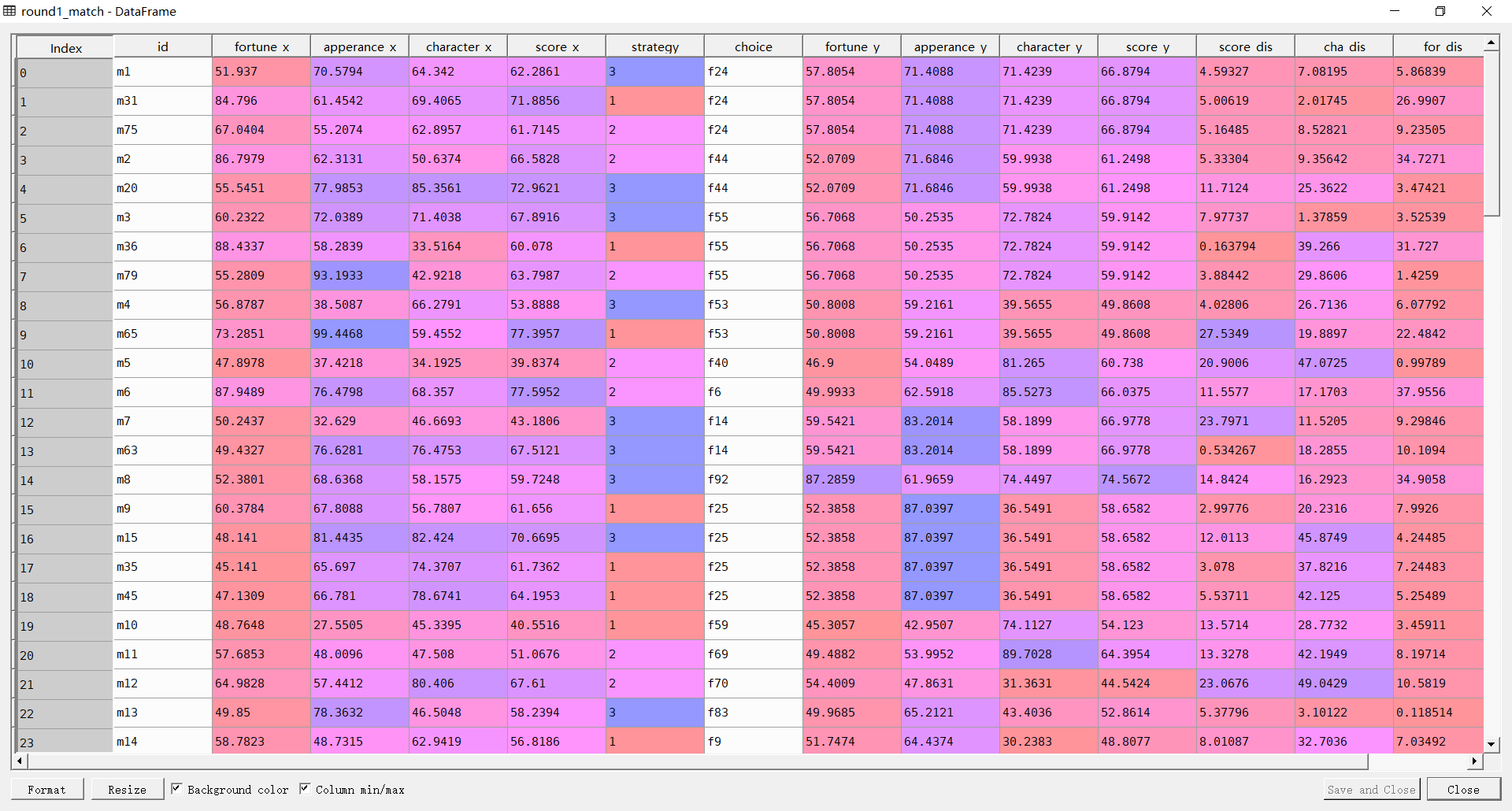
# 合并样本数据
根据上述生成的样本数据,我们需要将数据进行合并,具体操作如下:
1. 创建一个空数据集,为后续匹配成功的数据存储做准备
1. 分别创建男性数据和女性数据的副本,接下来用副本数据来做匹配
1. 通过样本随机函数,根据男性选择女性样本数据
1. 将男性样本数据和女性样本数据,通过参数合并
1. 分别计算每一组数据的综合平均分的差值、内涵值的差值、财富水平的差值与外貌水平的差值
```python
match_success = pd.DataFrame(columns = ['m', 'f', 'round_n', 'strategy_type'])
#创建空数据集,分别是男性编号、女性编号、第几轮、哪个策略
round1_f = sample_f_test.copy()
round1_m = sample_m_test.copy()
#复制实验数据,创建实验副本
round1_m['choice'] = np.random.choice(round1_f.index, len(round1_m))
#该轮的匹配选择,根据男性数量选择女性数量
round1_match = pd.merge(round1_m, round1_f, left_on = 'choice', right_index = True).reset_index()
round1_match['score_dis'] = np.abs(round1_match['score_x'] - round1_match['score_y']) #就散综合评分差值
round1_match['cha_dis'] = np.abs(round1_match['character_x'] - round1_match['character_y']) #计算内涵评分差值
round1_match['for_dis'] = np.abs(round1_match['fortune_x'] - round1_match['fortune_y']) #计算财富评分差值
round1_match['app_dis'] = np.abs(round1_match['apperance_x'] - round1_match['apperance_y']) #计算外貌评分差值
#合并数据
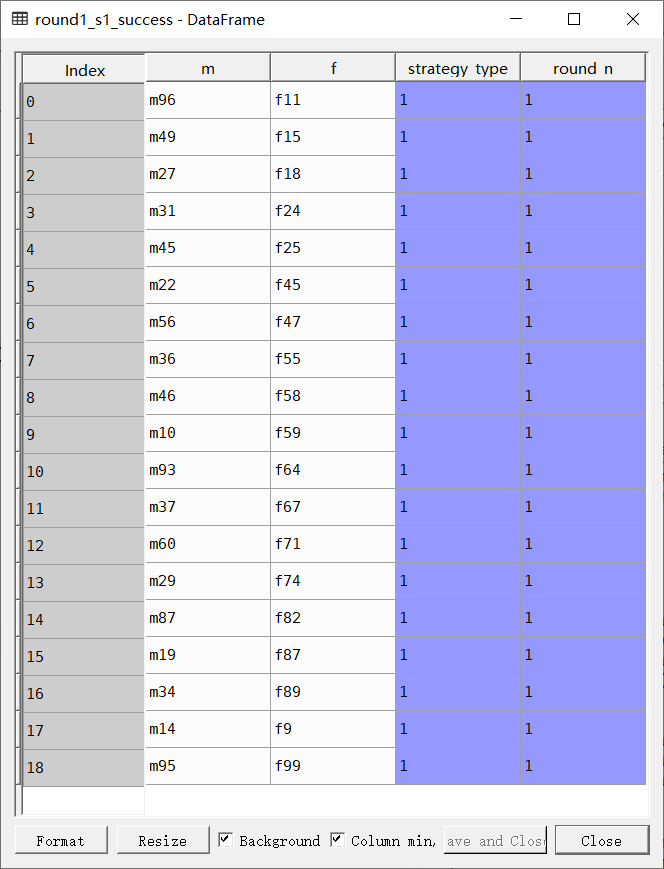
策略1:门当户对
开始进行匹配,从实现分成三类的男性数据中,挑选出第一类数据,作为策略1的匹配数据,然后筛选出综合平均分差值小于20分的数据,由于可能一个女性匹配成功多个女性,因此需要在其中筛选出一组数据中的最大值,但是由于‘choice’数据匹配数据与其他数据存在不一致的情况,因此需要将筛选出的数据,与原始数据进行合并然后更改匹配成功数据的columns,标记此次匹配的策略和次数,最终将匹配成功的数据从源数据中删掉
接下来的几轮匹配参照同样的方法
round1_s1_m = round1_match[round1_match['strategy'] == 1]
round1_s1_success = round1_s1_m[round1_s1_m['score_dis'] <= 20].groupby('choice').max()
round1_s1_success = pd.merge(round1_s1_success, round1_m.reset_index(), left_on = 'score_x', right_on = 'score')[['id_y', 'choice']]
round1_s1_success.columns = ['m','f']
round1_s1_success['strategy_type'] = 1
round1_s1_success['round_n'] = 1 #成功得到策略1的匹配结果
round1_match.index = round1_match['choice']
round1_match = round1_match.drop(round1_s1_success['f'].tolist())
#由于在之前,一个女性可能匹配多个男性,所有当删除匹配成功的数据后,除了删掉了相应匹配成功的男性,同样也删除了竞争失败的男性
策略2:郎才女貌
round1_s2_m = round1_match[round1_match['strategy'] == 2]
round1_s2_success = round1_s2_m[(round1_s2_m['fortune_x'] - round1_s2_m['fortune_y']>=10)
&(round1_s2_m['apperance_y'] - round1_s2_m['apperance_x'] >= 10)]
round1_s2_success = round1_s2_success.groupby('choice').max()
round1_s2_success = pd.merge(round1_s2_success, round1_m.reset_index(), left_on = 'score_x', right_on = 'score')[['id_y','choice']]
round1_s2_success = round1_s2_success[['id_y','choice']]
round1_s2_success.columns = ['m', 'f']
round1_s2_success['strategy_type'] = 2
round1_s2_success['round_n'] = 1
round1_match.index = round1_match['choice']
round1_match = round1_match.drop(round1_s2_success['f'].tolist())
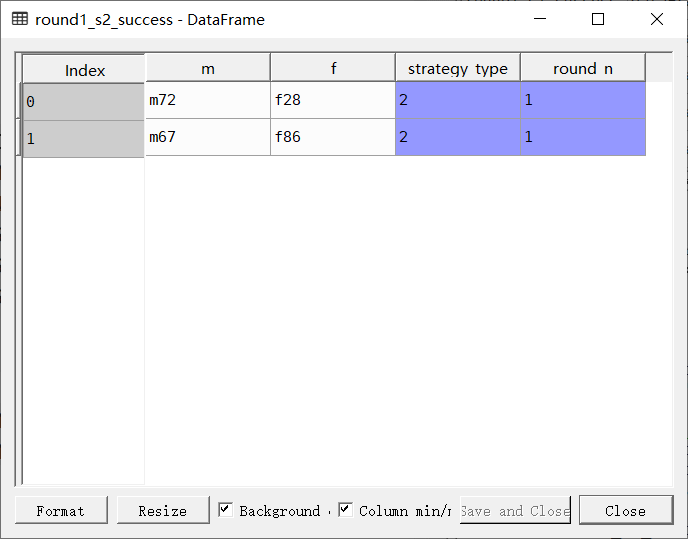
策略3:志趣相投、适度引领
round1_s3_m = round1_match[round1_match['strategy'] == 3]
round1_s3_success = round1_s3_m[(round1_s3_m['cha_dis'] <10) & # 内涵得分差在10分以内\n",
(round1_s3_m['for_dis'] < 5 )& # 财富得分差在5分以内\n",
(round1_s3_m['app_dis'] < 5 )] # 外貌得分差在5分以内\n",
round1_s3_success = round1_s3_success.groupby('choice').max() # 筛选符合要求的数据\n",
round1_s3_success = pd.merge(round1_s3_success,round1_m.reset_index(),left_on = 'score_x',right_on = 'score')[['id_y','choice']]
round1_s3_success.columns = ['m','f']
round1_s3_success['strategy_type'] = 3
round1_s3_success['round_n'] = 1
筛选出匹配成功的数据
# 筛选出成功匹配数据
match_success = pd.concat([match_success,round1_s1_success,round1_s2_success,round1_s3_success])
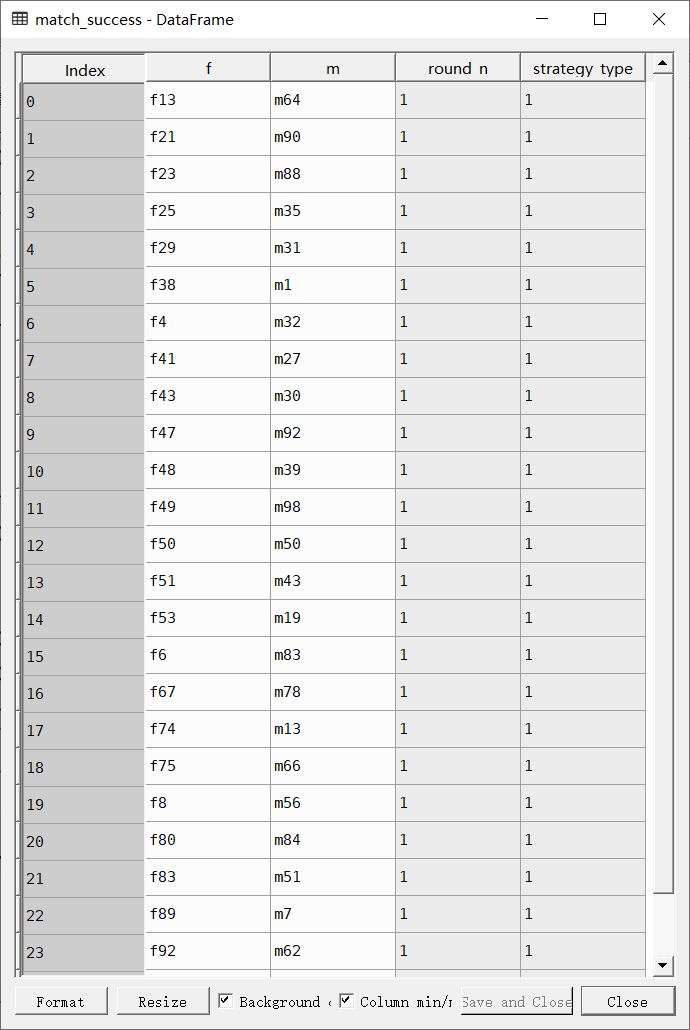
筛选出下一轮实验数据
round2_m = round1_m.drop(match_success['m'].tolist())
round2_f = round1_f.drop(match_success['f'].tolist())
构建模型
按照之前实验的99个男性与女性的结果,在此将之前的代码封装为一个函数,其功能包括数据的选择、合并数据、计算各个指标之前的差值、完成策略1、策略2、策略3的匹配,然后返回成功匹配的结果,代码如下:
'''
构建模型
'''
def different_strategy(data_m, data_f, roundnum):
data_m['choice'] = np.random.choice(data_f.index, len(data_m))
#该轮匹配的选择
round_match = pd.merge(data_m, data_f, left_on = 'choice', right_index = True).reset_index()
#合并数据
round_match['score_dis'] = np.abs(round_match['score_x'] - round_match['score_y']) #计算综合评分差值
round_match['cha_dis'] = np.abs(round_match['character_x'] - round_match['character_y']) #计算内涵评分差值
round_match['for_dis'] = np.abs(round_match['fortune_x'] - round_match['fortune_y']) #计算财富评分差值
round_match['app_dis'] = np.abs(round_match['apperance_x'] - round_match['apperance_y']) #计算外貌评分差值
#计算各个指标差值
#策略1:门当户对
s1_m = round_match[round_match['strategy'] == 1]
s1_success = s1_m[s1_m['score_dis'] <= 20].groupby('choice').max()
s1_success = pd.merge(s1_success, data_m.reset_index(), left_on = 'score_x', right_on = 'score')[['id_y', 'choice']]
s1_success.columns = ['m','f']
s1_success['strategy_type'] = 1
s1_success['round_n'] = roundnum #成功得到策略1的匹配结果
round_match.index = round_match['choice']
round_match = round_match.drop(s1_success['f'].tolist())
#由于在之前,一个女性可能匹配多个男性,所有当删除匹配成功的数据后,除了删掉了相应匹配成功的男性,同样也删除了竞争失败的男性
'''
策略2:郎才女貌
'''
s2_m = round_match[round_match['strategy'] == 2]
s2_success = s2_m[(s2_m['fortune_x'] - s2_m['fortune_y']>=10)
&(s2_m['apperance_y'] - s2_m['apperance_x'] >= 10)]
s2_success = s2_success.groupby('choice').max()
s2_success = pd.merge(s2_success, data_m.reset_index(), left_on = 'score_x', right_on = 'score')[['id_y','choice']]
s2_success = s2_success[['id_y','choice']]
s2_success.columns = ['m', 'f']
s2_success['strategy_type'] = 2
s2_success['round_n'] = roundnum
round_match.index = round_match['choice']
round_match = round_match.drop(s2_success['f'].tolist())
'''
策略3:志趣相投、适度引领
'''
s3_m = round_match[round_match['strategy'] == 3]
s3_success = s3_m[(s3_m['cha_dis'] <10) & # 内涵得分差在10分以内\n",
(s3_m['for_dis'] < 5 )& # 财富得分差在5分以内\n",
(s3_m['app_dis'] < 5 )] # 外貌得分差在5分以内\n",
s3_success = s3_success.groupby('choice').max() # 筛选符合要求的数据\n",
s3_success = pd.merge(s3_success,data_m.reset_index(),left_on = 'score_x',right_on = 'score')[['id_y','choice']]
s3_success.columns = ['m','f']
s3_success['strategy_type'] = 3
s3_success['round_n'] = roundnum
#该轮成功匹配数据
data_success = pd.concat([s1_success, s2_success, s3_success])
return data_success
运行模型
在上诉99个男性与99个女性匹配成功后,成功构建模型,模拟1万男性+1万女性的配对实验
- 按照之前生成99个男性与女性匹配的模式,在此次生成10000个男性与女性匹配的模型
- 将创建好的10000个样本生成副本,使用副本进行模型试验
- 这只一个试验次数变量n,初始值为1
- 设置一个起始时间
- 调用函数different_strategy(),向其传入参数男性数据、女性数据和实验次数n
- 将成功匹配的数据,赋值给变量match_success1
- 删除男性数据和女性数据中,成功匹配的数据
- 使用while循环不断匹配数据,当该次匹配没有男性与女性成功配对时,退出循序
- 记录结束时间
```python
‘’’
运行模型
‘’’
sample1_m1 = create_sample(10000, ‘m’)
sample1_f1 = create_sample(10000, ‘f’)
sample1_m1[‘strategy’] = np.random.choice([1, 2, 3], 10000)
创建样本数据
test_m1 = sample1_m1.copy() test_f1 = sample1_f1.copy()
复制实验数据,创建实验副本
n = 1
设置一个实验次数变量
starttime = time.time()
设置起始时间
success_roundn = different_strategy(test_m1, test_f1, n) match_success1 = success_roundn test_m1 = test_m1.drop(success_roundn[‘m’].tolist()) test_f1 = test_f1.drop(success_roundn[‘f’].tolist())
print(‘成功进行第%i轮试验,本轮实验成功匹配%i对,总共成功匹配%i对,还剩下%i位男性和%i为女性’% (n, len(success_roundn), len(match_success1), len(test_m1),len(test_f1)))
第一轮测试
while len(success_roundn) != 0: n += 1 success_roundn = different_strategy(test_m1,test_f1,n)
#得到该轮成功匹配数据
match_success1 = pd.concat([match_success1,success_roundn])
# 将成功匹配数据汇总
test_m1 = test_m1.drop(success_roundn['m'].tolist())
test_f1 = test_f1.drop(success_roundn['f'].tolist())
# 输出下一轮实验数据
print('成功进行第%i轮实验,本轮实验成功匹配%i对,总共成功匹配%i对,还剩下%i位男性和%i位女性' %
(n,len(success_roundn),len(match_success1),len(test_m1),len(test_f1)))
endtime = time.time()
记录结束时间
print(‘——————————‘) print(‘本次实验总共进行了%i轮,配对成功%i对\n———————-‘%(n, len(match_success1))) print(‘实验总共耗时%.2f秒’%(endtime - starttime))
<a name="PX4V3"></a>
## 运行结果
```python
成功进行第1轮试验,本轮实验成功匹配2810对,总共成功匹配2810对,还剩下7190位男性和7190为女性
成功进行第2轮实验,本轮实验成功匹配819对,总共成功匹配3629对,还剩下6371位男性和6371位女性
成功进行第3轮实验,本轮实验成功匹配300对,总共成功匹配3929对,还剩下6071位男性和6071位女性
成功进行第4轮实验,本轮实验成功匹配173对,总共成功匹配4102对,还剩下5898位男性和5898位女性
成功进行第5轮实验,本轮实验成功匹配135对,总共成功匹配4237对,还剩下5763位男性和5763位女性
成功进行第6轮实验,本轮实验成功匹配106对,总共成功匹配4343对,还剩下5657位男性和5657位女性
成功进行第7轮实验,本轮实验成功匹配107对,总共成功匹配4450对,还剩下5550位男性和5550位女性
成功进行第8轮实验,本轮实验成功匹配86对,总共成功匹配4536对,还剩下5464位男性和5464位女性
成功进行第9轮实验,本轮实验成功匹配74对,总共成功匹配4610对,还剩下5390位男性和5390位女性
成功进行第10轮实验,本轮实验成功匹配53对,总共成功匹配4663对,还剩下5337位男性和5337位女性
成功进行第11轮实验,本轮实验成功匹配70对,总共成功匹配4733对,还剩下5267位男性和5267位女性
成功进行第12轮实验,本轮实验成功匹配76对,总共成功匹配4809对,还剩下5191位男性和5191位女性
成功进行第13轮实验,本轮实验成功匹配69对,总共成功匹配4878对,还剩下5122位男性和5122位女性
成功进行第14轮实验,本轮实验成功匹配66对,总共成功匹配4944对,还剩下5056位男性和5056位女性
成功进行第15轮实验,本轮实验成功匹配45对,总共成功匹配4989对,还剩下5011位男性和5011位女性
成功进行第16轮实验,本轮实验成功匹配51对,总共成功匹配5040对,还剩下4960位男性和4960位女性
成功进行第17轮实验,本轮实验成功匹配43对,总共成功匹配5083对,还剩下4917位男性和4917位女性
成功进行第18轮实验,本轮实验成功匹配58对,总共成功匹配5141对,还剩下4859位男性和4859位女性
成功进行第19轮实验,本轮实验成功匹配39对,总共成功匹配5180对,还剩下4820位男性和4820位女性
成功进行第20轮实验,本轮实验成功匹配48对,总共成功匹配5228对,还剩下4772位男性和4772位女性
成功进行第21轮实验,本轮实验成功匹配48对,总共成功匹配5276对,还剩下4724位男性和4724位女性
成功进行第22轮实验,本轮实验成功匹配39对,总共成功匹配5315对,还剩下4685位男性和4685位女性
成功进行第23轮实验,本轮实验成功匹配42对,总共成功匹配5357对,还剩下4643位男性和4643位女性
成功进行第24轮实验,本轮实验成功匹配31对,总共成功匹配5388对,还剩下4612位男性和4612位女性
成功进行第25轮实验,本轮实验成功匹配26对,总共成功匹配5414对,还剩下4586位男性和4586位女性
成功进行第26轮实验,本轮实验成功匹配35对,总共成功匹配5449对,还剩下4551位男性和4551位女性
成功进行第27轮实验,本轮实验成功匹配32对,总共成功匹配5481对,还剩下4519位男性和4519位女性
成功进行第28轮实验,本轮实验成功匹配30对,总共成功匹配5511对,还剩下4489位男性和4489位女性
成功进行第29轮实验,本轮实验成功匹配38对,总共成功匹配5549对,还剩下4451位男性和4451位女性
成功进行第30轮实验,本轮实验成功匹配23对,总共成功匹配5572对,还剩下4428位男性和4428位女性
成功进行第31轮实验,本轮实验成功匹配25对,总共成功匹配5597对,还剩下4403位男性和4403位女性
成功进行第32轮实验,本轮实验成功匹配36对,总共成功匹配5633对,还剩下4367位男性和4367位女性
成功进行第33轮实验,本轮实验成功匹配32对,总共成功匹配5665对,还剩下4335位男性和4335位女性
成功进行第34轮实验,本轮实验成功匹配31对,总共成功匹配5696对,还剩下4304位男性和4304位女性
成功进行第35轮实验,本轮实验成功匹配20对,总共成功匹配5716对,还剩下4284位男性和4284位女性
成功进行第36轮实验,本轮实验成功匹配23对,总共成功匹配5739对,还剩下4261位男性和4261位女性
成功进行第37轮实验,本轮实验成功匹配24对,总共成功匹配5763对,还剩下4237位男性和4237位女性
成功进行第38轮实验,本轮实验成功匹配19对,总共成功匹配5782对,还剩下4218位男性和4218位女性
成功进行第39轮实验,本轮实验成功匹配30对,总共成功匹配5812对,还剩下4188位男性和4188位女性
成功进行第40轮实验,本轮实验成功匹配24对,总共成功匹配5836对,还剩下4164位男性和4164位女性
成功进行第41轮实验,本轮实验成功匹配17对,总共成功匹配5853对,还剩下4147位男性和4147位女性
成功进行第42轮实验,本轮实验成功匹配21对,总共成功匹配5874对,还剩下4126位男性和4126位女性
成功进行第43轮实验,本轮实验成功匹配33对,总共成功匹配5907对,还剩下4093位男性和4093位女性
成功进行第44轮实验,本轮实验成功匹配27对,总共成功匹配5934对,还剩下4066位男性和4066位女性
成功进行第45轮实验,本轮实验成功匹配29对,总共成功匹配5963对,还剩下4037位男性和4037位女性
成功进行第46轮实验,本轮实验成功匹配32对,总共成功匹配5995对,还剩下4005位男性和4005位女性
成功进行第47轮实验,本轮实验成功匹配17对,总共成功匹配6012对,还剩下3988位男性和3988位女性
成功进行第48轮实验,本轮实验成功匹配16对,总共成功匹配6028对,还剩下3972位男性和3972位女性
成功进行第49轮实验,本轮实验成功匹配19对,总共成功匹配6047对,还剩下3953位男性和3953位女性
成功进行第50轮实验,本轮实验成功匹配25对,总共成功匹配6072对,还剩下3928位男性和3928位女性
成功进行第51轮实验,本轮实验成功匹配16对,总共成功匹配6088对,还剩下3912位男性和3912位女性
成功进行第52轮实验,本轮实验成功匹配20对,总共成功匹配6108对,还剩下3892位男性和3892位女性
成功进行第53轮实验,本轮实验成功匹配21对,总共成功匹配6129对,还剩下3871位男性和3871位女性
成功进行第54轮实验,本轮实验成功匹配22对,总共成功匹配6151对,还剩下3849位男性和3849位女性
成功进行第55轮实验,本轮实验成功匹配15对,总共成功匹配6166对,还剩下3834位男性和3834位女性
成功进行第56轮实验,本轮实验成功匹配21对,总共成功匹配6187对,还剩下3813位男性和3813位女性
成功进行第57轮实验,本轮实验成功匹配15对,总共成功匹配6202对,还剩下3798位男性和3798位女性
成功进行第58轮实验,本轮实验成功匹配12对,总共成功匹配6214对,还剩下3786位男性和3786位女性
成功进行第59轮实验,本轮实验成功匹配14对,总共成功匹配6228对,还剩下3772位男性和3772位女性
成功进行第60轮实验,本轮实验成功匹配15对,总共成功匹配6243对,还剩下3757位男性和3757位女性
成功进行第61轮实验,本轮实验成功匹配13对,总共成功匹配6256对,还剩下3744位男性和3744位女性
成功进行第62轮实验,本轮实验成功匹配14对,总共成功匹配6270对,还剩下3730位男性和3730位女性
成功进行第63轮实验,本轮实验成功匹配15对,总共成功匹配6285对,还剩下3715位男性和3715位女性
成功进行第64轮实验,本轮实验成功匹配14对,总共成功匹配6299对,还剩下3701位男性和3701位女性
成功进行第65轮实验,本轮实验成功匹配8对,总共成功匹配6307对,还剩下3693位男性和3693位女性
成功进行第66轮实验,本轮实验成功匹配11对,总共成功匹配6318对,还剩下3682位男性和3682位女性
成功进行第67轮实验,本轮实验成功匹配20对,总共成功匹配6338对,还剩下3662位男性和3662位女性
成功进行第68轮实验,本轮实验成功匹配8对,总共成功匹配6346对,还剩下3654位男性和3654位女性
成功进行第69轮实验,本轮实验成功匹配12对,总共成功匹配6358对,还剩下3642位男性和3642位女性
成功进行第70轮实验,本轮实验成功匹配14对,总共成功匹配6372对,还剩下3628位男性和3628位女性
成功进行第71轮实验,本轮实验成功匹配12对,总共成功匹配6384对,还剩下3616位男性和3616位女性
成功进行第72轮实验,本轮实验成功匹配12对,总共成功匹配6396对,还剩下3604位男性和3604位女性
成功进行第73轮实验,本轮实验成功匹配11对,总共成功匹配6407对,还剩下3593位男性和3593位女性
成功进行第74轮实验,本轮实验成功匹配11对,总共成功匹配6418对,还剩下3582位男性和3582位女性
成功进行第75轮实验,本轮实验成功匹配11对,总共成功匹配6429对,还剩下3571位男性和3571位女性
成功进行第76轮实验,本轮实验成功匹配10对,总共成功匹配6439对,还剩下3561位男性和3561位女性
成功进行第77轮实验,本轮实验成功匹配14对,总共成功匹配6453对,还剩下3547位男性和3547位女性
成功进行第78轮实验,本轮实验成功匹配13对,总共成功匹配6466对,还剩下3534位男性和3534位女性
成功进行第79轮实验,本轮实验成功匹配13对,总共成功匹配6479对,还剩下3521位男性和3521位女性
成功进行第80轮实验,本轮实验成功匹配9对,总共成功匹配6488对,还剩下3512位男性和3512位女性
成功进行第81轮实验,本轮实验成功匹配16对,总共成功匹配6504对,还剩下3496位男性和3496位女性
成功进行第82轮实验,本轮实验成功匹配14对,总共成功匹配6518对,还剩下3482位男性和3482位女性
成功进行第83轮实验,本轮实验成功匹配10对,总共成功匹配6528对,还剩下3472位男性和3472位女性
成功进行第84轮实验,本轮实验成功匹配14对,总共成功匹配6542对,还剩下3458位男性和3458位女性
成功进行第85轮实验,本轮实验成功匹配5对,总共成功匹配6547对,还剩下3453位男性和3453位女性
成功进行第86轮实验,本轮实验成功匹配12对,总共成功匹配6559对,还剩下3441位男性和3441位女性
成功进行第87轮实验,本轮实验成功匹配14对,总共成功匹配6573对,还剩下3427位男性和3427位女性
成功进行第88轮实验,本轮实验成功匹配12对,总共成功匹配6585对,还剩下3415位男性和3415位女性
成功进行第89轮实验,本轮实验成功匹配10对,总共成功匹配6595对,还剩下3405位男性和3405位女性
成功进行第90轮实验,本轮实验成功匹配11对,总共成功匹配6606对,还剩下3394位男性和3394位女性
成功进行第91轮实验,本轮实验成功匹配5对,总共成功匹配6611对,还剩下3389位男性和3389位女性
成功进行第92轮实验,本轮实验成功匹配3对,总共成功匹配6614对,还剩下3386位男性和3386位女性
成功进行第93轮实验,本轮实验成功匹配11对,总共成功匹配6625对,还剩下3375位男性和3375位女性
成功进行第94轮实验,本轮实验成功匹配7对,总共成功匹配6632对,还剩下3368位男性和3368位女性
成功进行第95轮实验,本轮实验成功匹配9对,总共成功匹配6641对,还剩下3359位男性和3359位女性
成功进行第96轮实验,本轮实验成功匹配9对,总共成功匹配6650对,还剩下3350位男性和3350位女性
成功进行第97轮实验,本轮实验成功匹配10对,总共成功匹配6660对,还剩下3340位男性和3340位女性
成功进行第98轮实验,本轮实验成功匹配14对,总共成功匹配6674对,还剩下3326位男性和3326位女性
成功进行第99轮实验,本轮实验成功匹配9对,总共成功匹配6683对,还剩下3317位男性和3317位女性
成功进行第100轮实验,本轮实验成功匹配6对,总共成功匹配6689对,还剩下3311位男性和3311位女性
成功进行第101轮实验,本轮实验成功匹配19对,总共成功匹配6708对,还剩下3292位男性和3292位女性
成功进行第102轮实验,本轮实验成功匹配8对,总共成功匹配6716对,还剩下3284位男性和3284位女性
成功进行第103轮实验,本轮实验成功匹配5对,总共成功匹配6721对,还剩下3279位男性和3279位女性
成功进行第104轮实验,本轮实验成功匹配11对,总共成功匹配6732对,还剩下3268位男性和3268位女性
成功进行第105轮实验,本轮实验成功匹配12对,总共成功匹配6744对,还剩下3256位男性和3256位女性
成功进行第106轮实验,本轮实验成功匹配5对,总共成功匹配6749对,还剩下3251位男性和3251位女性
成功进行第107轮实验,本轮实验成功匹配14对,总共成功匹配6763对,还剩下3237位男性和3237位女性
成功进行第108轮实验,本轮实验成功匹配12对,总共成功匹配6775对,还剩下3225位男性和3225位女性
成功进行第109轮实验,本轮实验成功匹配10对,总共成功匹配6785对,还剩下3215位男性和3215位女性
成功进行第110轮实验,本轮实验成功匹配11对,总共成功匹配6796对,还剩下3204位男性和3204位女性
成功进行第111轮实验,本轮实验成功匹配8对,总共成功匹配6804对,还剩下3196位男性和3196位女性
成功进行第112轮实验,本轮实验成功匹配5对,总共成功匹配6809对,还剩下3191位男性和3191位女性
成功进行第113轮实验,本轮实验成功匹配7对,总共成功匹配6816对,还剩下3184位男性和3184位女性
成功进行第114轮实验,本轮实验成功匹配9对,总共成功匹配6825对,还剩下3175位男性和3175位女性
成功进行第115轮实验,本轮实验成功匹配12对,总共成功匹配6837对,还剩下3163位男性和3163位女性
成功进行第116轮实验,本轮实验成功匹配11对,总共成功匹配6848对,还剩下3152位男性和3152位女性
成功进行第117轮实验,本轮实验成功匹配6对,总共成功匹配6854对,还剩下3146位男性和3146位女性
成功进行第118轮实验,本轮实验成功匹配5对,总共成功匹配6859对,还剩下3141位男性和3141位女性
成功进行第119轮实验,本轮实验成功匹配4对,总共成功匹配6863对,还剩下3137位男性和3137位女性
成功进行第120轮实验,本轮实验成功匹配5对,总共成功匹配6868对,还剩下3132位男性和3132位女性
成功进行第121轮实验,本轮实验成功匹配8对,总共成功匹配6876对,还剩下3124位男性和3124位女性
成功进行第122轮实验,本轮实验成功匹配7对,总共成功匹配6883对,还剩下3117位男性和3117位女性
成功进行第123轮实验,本轮实验成功匹配5对,总共成功匹配6888对,还剩下3112位男性和3112位女性
成功进行第124轮实验,本轮实验成功匹配8对,总共成功匹配6896对,还剩下3104位男性和3104位女性
成功进行第125轮实验,本轮实验成功匹配9对,总共成功匹配6905对,还剩下3095位男性和3095位女性
成功进行第126轮实验,本轮实验成功匹配3对,总共成功匹配6908对,还剩下3092位男性和3092位女性
成功进行第127轮实验,本轮实验成功匹配8对,总共成功匹配6916对,还剩下3084位男性和3084位女性
成功进行第128轮实验,本轮实验成功匹配6对,总共成功匹配6922对,还剩下3078位男性和3078位女性
成功进行第129轮实验,本轮实验成功匹配7对,总共成功匹配6929对,还剩下3071位男性和3071位女性
成功进行第130轮实验,本轮实验成功匹配2对,总共成功匹配6931对,还剩下3069位男性和3069位女性
成功进行第131轮实验,本轮实验成功匹配8对,总共成功匹配6939对,还剩下3061位男性和3061位女性
成功进行第132轮实验,本轮实验成功匹配5对,总共成功匹配6944对,还剩下3056位男性和3056位女性
成功进行第133轮实验,本轮实验成功匹配2对,总共成功匹配6946对,还剩下3054位男性和3054位女性
成功进行第134轮实验,本轮实验成功匹配6对,总共成功匹配6952对,还剩下3048位男性和3048位女性
成功进行第135轮实验,本轮实验成功匹配3对,总共成功匹配6955对,还剩下3045位男性和3045位女性
成功进行第136轮实验,本轮实验成功匹配5对,总共成功匹配6960对,还剩下3040位男性和3040位女性
成功进行第137轮实验,本轮实验成功匹配4对,总共成功匹配6964对,还剩下3036位男性和3036位女性
成功进行第138轮实验,本轮实验成功匹配3对,总共成功匹配6967对,还剩下3033位男性和3033位女性
成功进行第139轮实验,本轮实验成功匹配7对,总共成功匹配6974对,还剩下3026位男性和3026位女性
成功进行第140轮实验,本轮实验成功匹配0对,总共成功匹配6974对,还剩下3026位男性和3026位女性
--------------------
本次实验总共进行了140轮,配对成功6974对
---------------
实验总共耗时36.35秒
问题:
- 百分之多少的样本数据成功匹配到了对象?
- 采取不同择偶策略的匹配成功率分别是多少?
答案:
代码:
'''
(4)几个问题:
百分之多少的样本数据成功匹配到了对象?
采取不同择偶策略的匹配成功率分别是多少?
采取不同择偶策略的男性各项平均分是多少?
'''
#百分之多少的样本数据成功匹配到了对象?
print('%.2f%%的样本数据成功许配到了对象\n-------------'%(len(match_success1)/len(sample1_m1)*100))
#采取不同择偶策略的匹配成功率分别是多少?
print('择偶策略1的匹配成功率为%.2f%%' % (len(match_success1[match_success1['strategy_type']==1])/len(sample1_m1[sample1_m1['strategy'] == 1])*100))
print('择偶策略2的匹配成功率为%.2f%%' % (len(match_success1[match_success1['strategy_type']==2])/len(sample1_m1[sample1_m1['strategy'] == 2])*100))
print('择偶策略3的匹配成功率为%.2f%%' % (len(match_success1[match_success1['strategy_type']==3])/len(sample1_m1[sample1_m1['strategy'] == 3])*100))
print('\n---------')
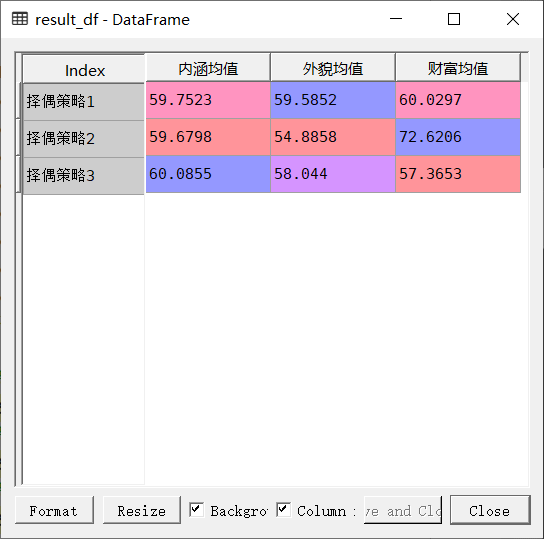
#采取不同择偶策略的男性各项平均分是多少?
match_m1 = pd.merge(match_success1,sample1_m1,left_on = 'm',right_index = True)
result_df = pd.DataFrame([{'财富均值':match_m1[match_m1['strategy_type'] == 1]['fortune'].mean(),
'内涵均值':match_m1[match_m1['strategy_type'] == 1]['character'].mean(),
'外貌均值':match_m1[match_m1['strategy_type'] == 1]['apperance'].mean()},
{'财富均值':match_m1[match_m1['strategy_type'] == 2]['fortune'].mean(),
'内涵均值':match_m1[match_m1['strategy_type'] == 2]['character'].mean(),
'外貌均值':match_m1[match_m1['strategy_type'] == 2]['apperance'].mean()},
{'财富均值':match_m1[match_m1['strategy_type'] == 3]['fortune'].mean(),
'内涵均值':match_m1[match_m1['strategy_type'] == 3]['character'].mean(),
'外貌均值':match_m1[match_m1['strategy_type'] == 3]['apperance'].mean()}],
index = ['择偶策略1','择偶策略2','择偶策略3'])
# 构建数据dataframe
print('择偶策略1的男性 → 财富均值为%.2f,内涵均值为%.2f,外貌均值为%.2f' %
(result_df.loc['择偶策略1']['财富均值'],result_df.loc['择偶策略1']['内涵均值'],result_df.loc['择偶策略1']['外貌均值']))
print('择偶策略2的男性 → 财富均值为%.2f,内涵均值为%.2f,外貌均值为%.2f' %
(result_df.loc['择偶策略2']['财富均值'],result_df.loc['择偶策略2']['内涵均值'],result_df.loc['择偶策略2']['外貌均值']))
print('择偶策略3的男性 → 财富均值为%.2f,内涵均值为%.2f,外貌均值为%.2f' %
(result_df.loc['择偶策略3']['财富均值'],result_df.loc['择偶策略3']['内涵均值'],result_df.loc['择偶策略3']['外貌均值']))
运行结果:
69.74%的样本数据成功许配到了对象
-------------
择偶策略1的匹配成功率为99.97%
择偶策略2的匹配成功率为37.36%
择偶策略3的匹配成功率为72.85%
---------
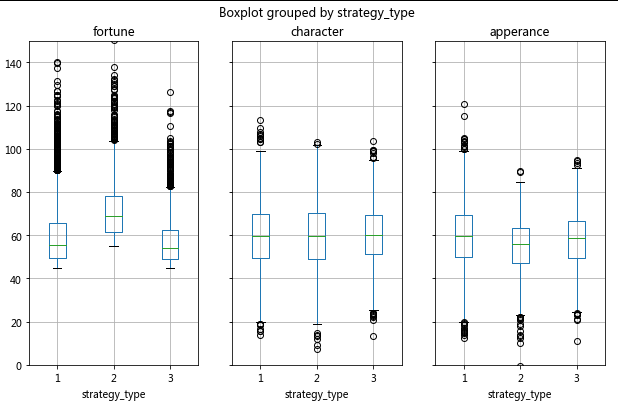
择偶策略1的男性 → 财富均值为60.03,内涵均值为59.75,外貌均值为59.59
择偶策略2的男性 → 财富均值为72.62,内涵均值为59.68,外貌均值为54.89
择偶策略3的男性 → 财富均值为57.37,内涵均值为60.09,外貌均值为58.04
绘制箱型图
match_m1.boxplot(column = ['fortune','character','apperance'],by='strategy_type',figsize = (10,6),layout = (1,3))
plt.ylim(0,150)
plt.show()
# 绘制箱型图

若有收获,就点个赞吧
0 人点赞
