https://leetcode-cn.com/problems/word-ladder/
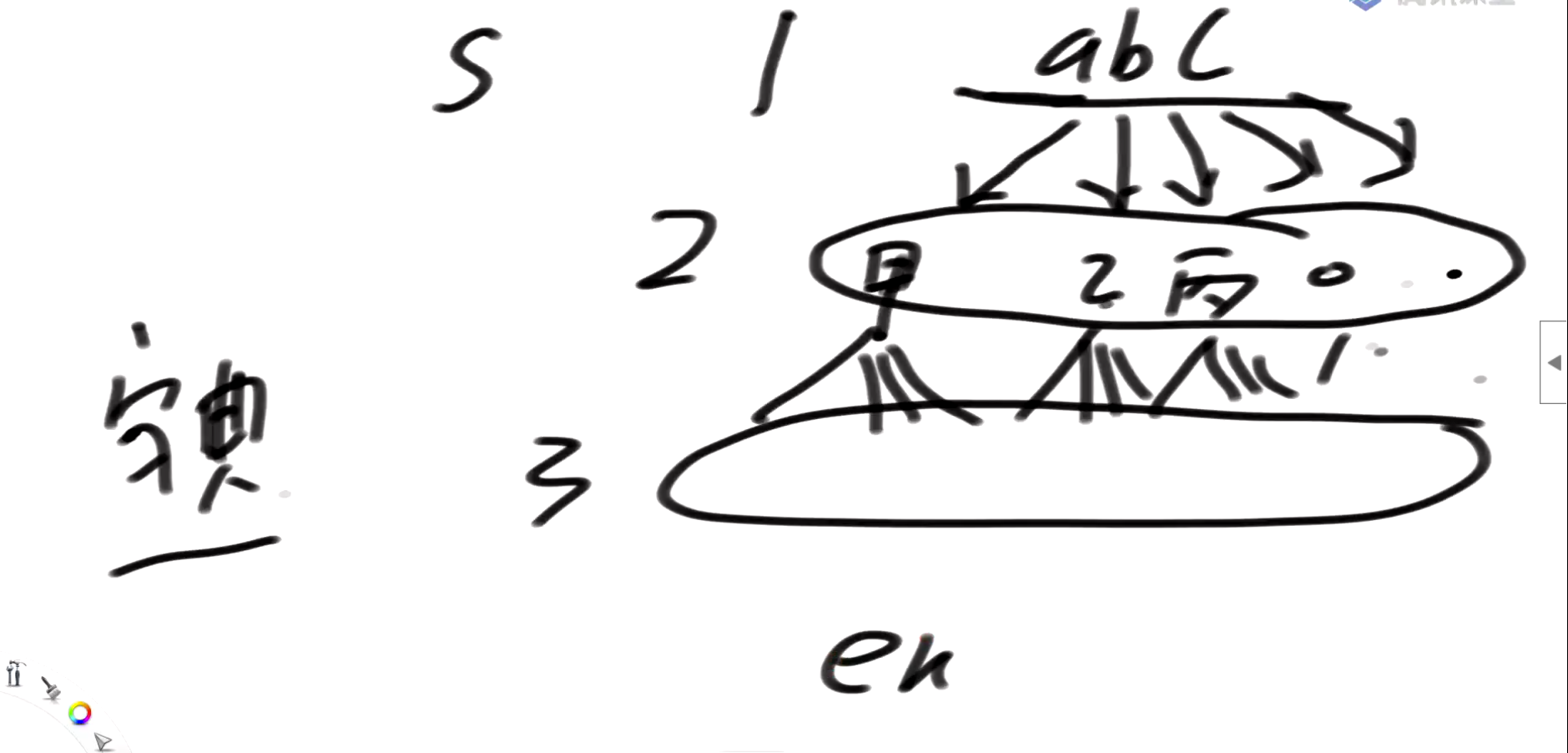
双向宽度优先搜索
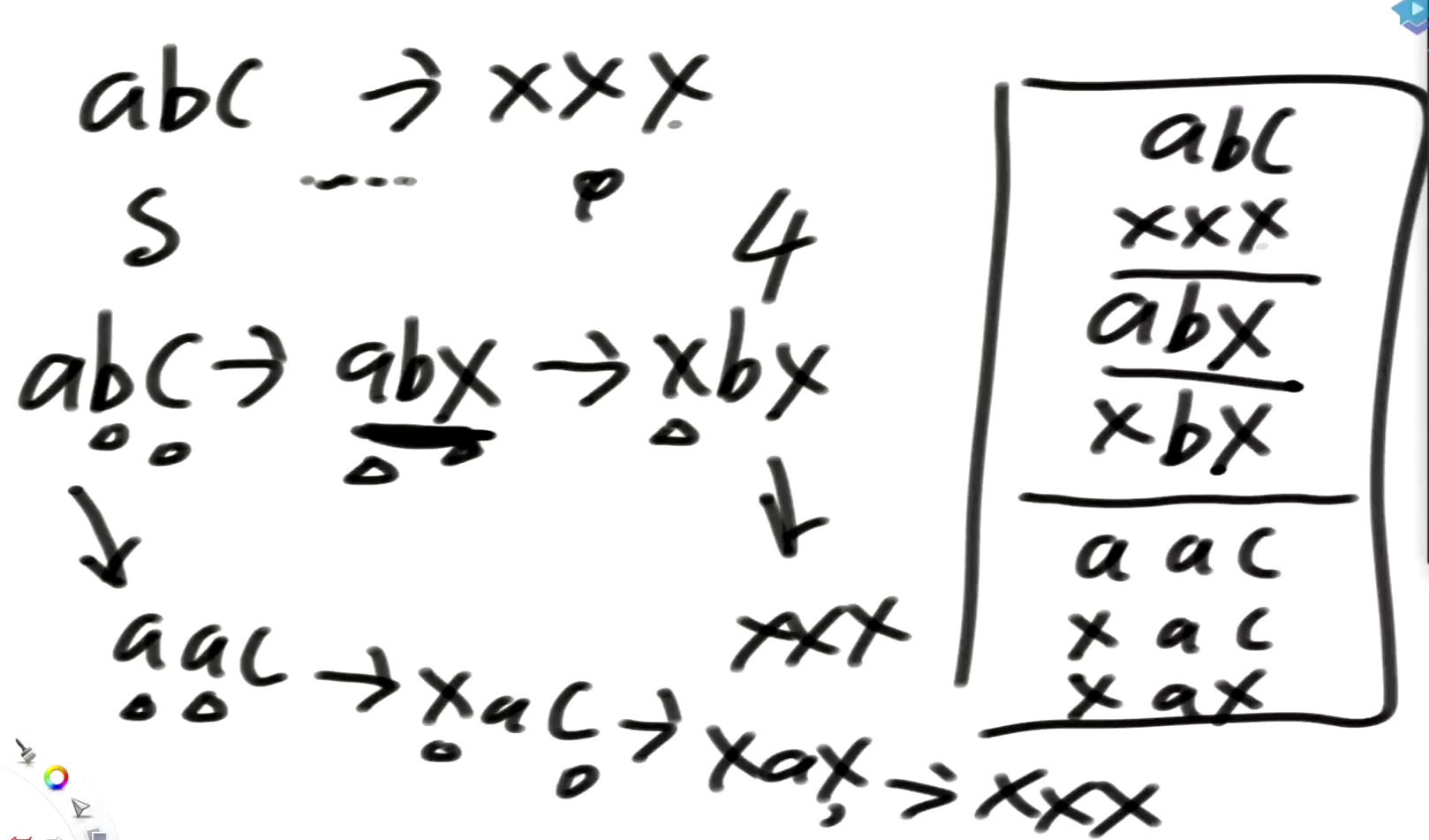
宽度优先遍历
宽度优先遍历
比如甲只跟a有一个字母不同, 那么甲就是a的下一层

穷举abc所有的邻居,然后去表中查存不存在
时间复杂度会好吗?会的
比如一个单词有4个字母,每个位置穷举就是25种,总共就是4*25种,而不是25^4
start单词k长度,
那么穷举是25*k 然后每个还要去哈希表中查一下,因为是String,要遍历这个String生成哈希code,所以这个代价是O(k)
所以总的代价就是O(k^2)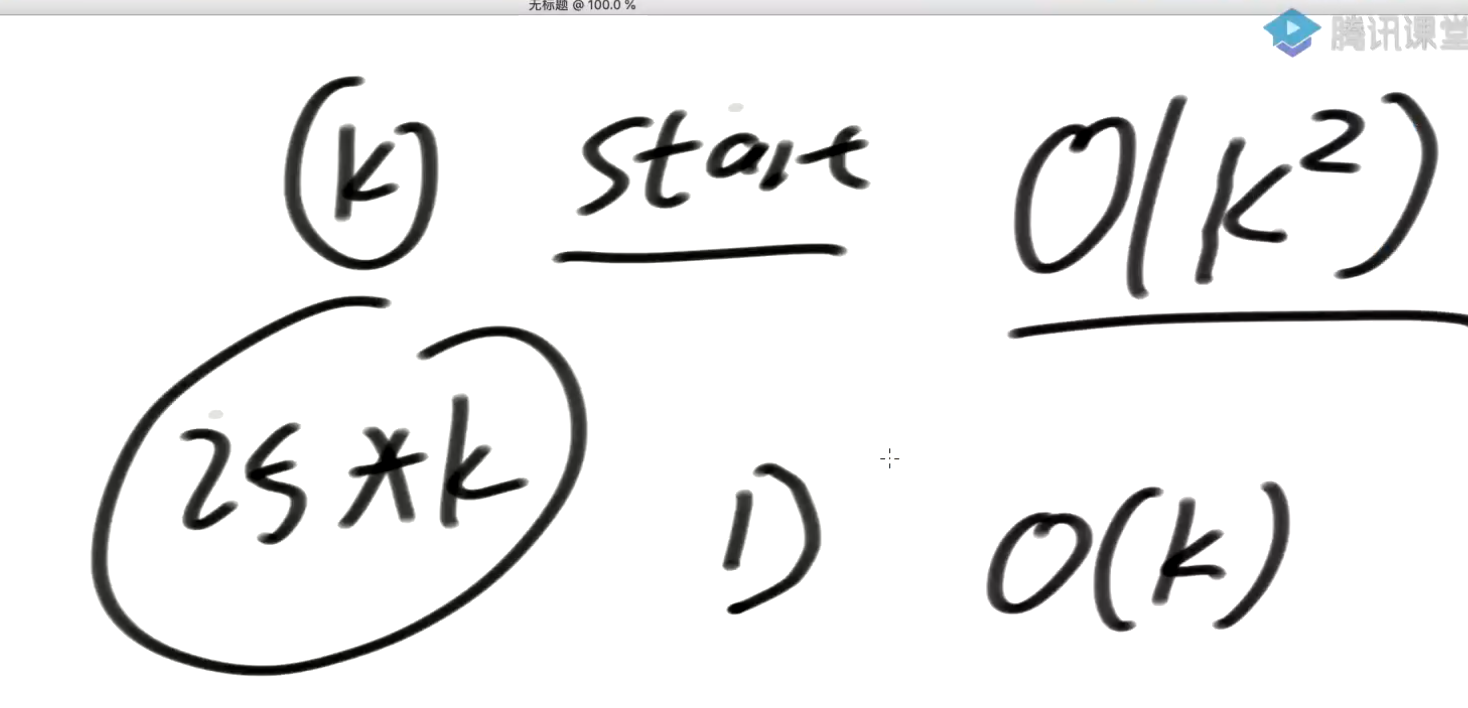
如果你不这样做的话,而是每个遇到每个单词就去字典匹配,那么代价是O(N * k)的
然后你从Start往下走遇到最先遇到end,跟你从end往上走最先遇到start是一样的
所以我每次都走节点较少的那一层,也就是走比较少发散的那个,少走冤枉路,比如下面,就是从小的走,
最终我们一定会在某个点交汇上,如果没有交汇,那就是不存在这样的路径,如果交汇上,那么你这样求就是最省的,
因为我每次都卡住发散比较少的那一侧,少走冤枉路,
这其实是一个贪心,如果你不做这种贪心的优化,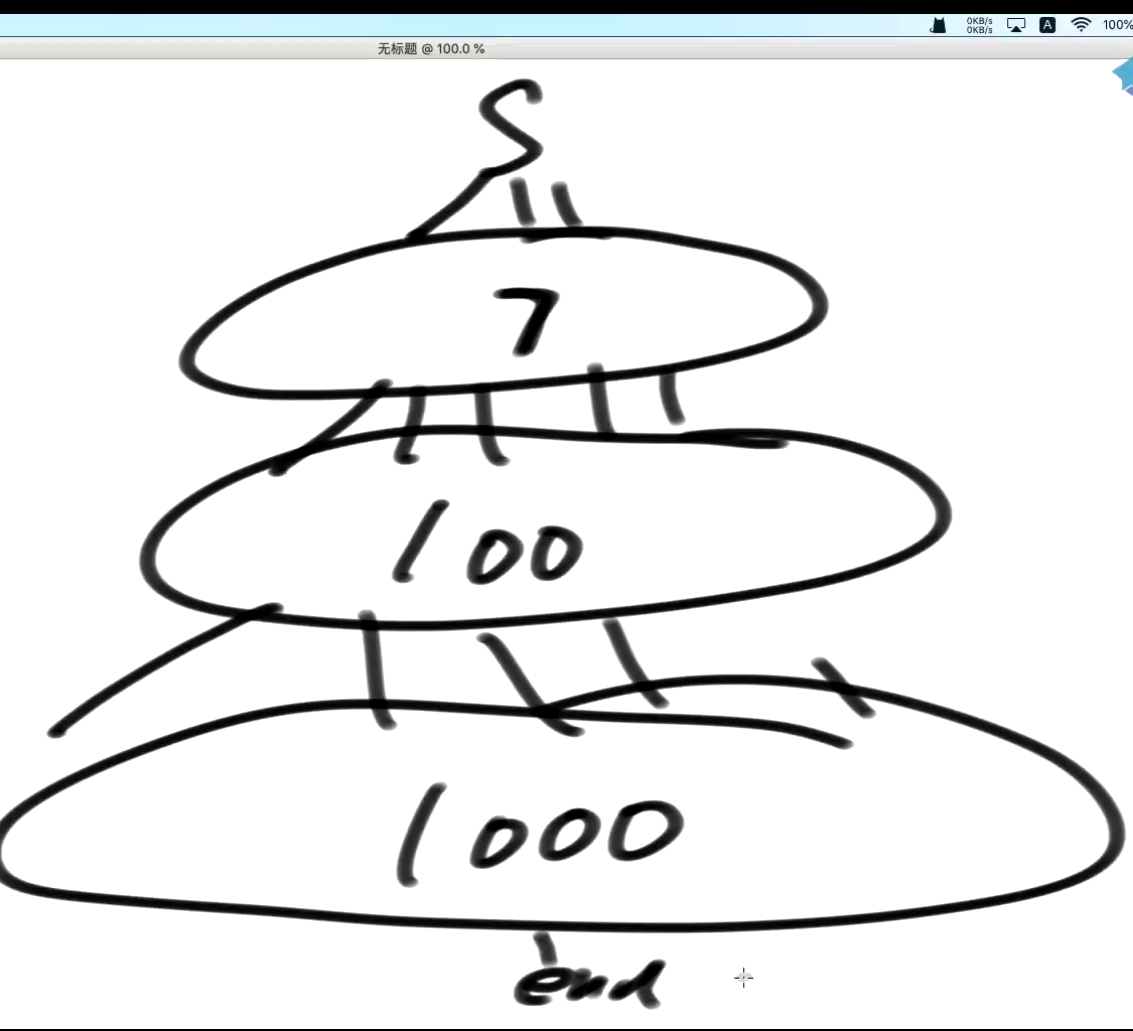
比如这里从上面走下来,要走很多路,走得会比较慢,
我们为什么不从小头找呢?小头找更快啊, 反正我们只是想相遇


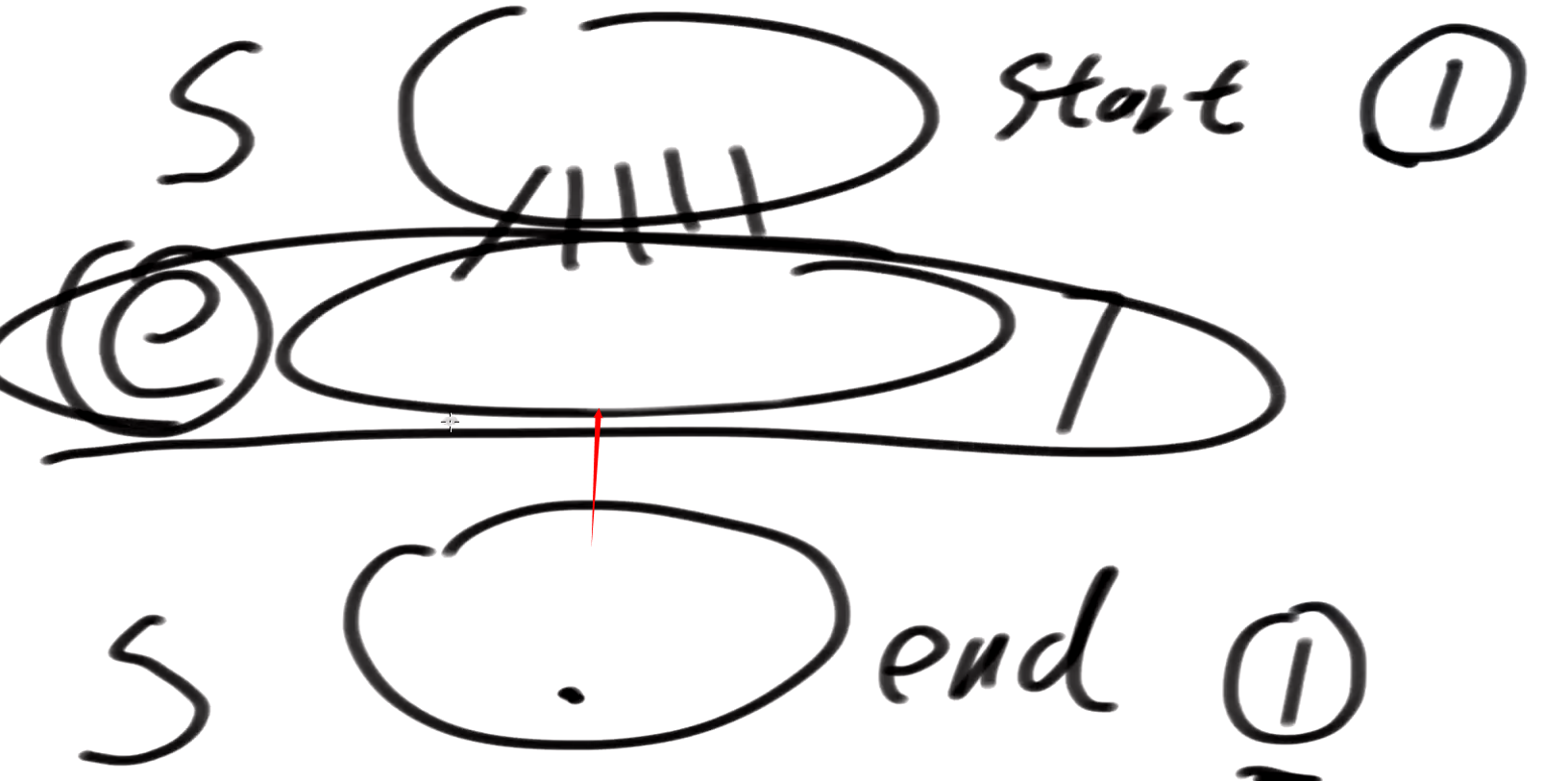
变换一下, 永远是要小在追大
从start层开始跑,如果我的next包含在了end层了,那我就是碰撞上了,就找到了就可以返回答案len了
宽度优先遍历中visit作用: 已经访问过的就放弃掉,不然你的宽度优先遍历会跑不完
public int ladderLength(String beginWord, String endWord, List<String> wordList) {HashSet<String> dict = new HashSet<>(wordList);HashSet<String> startSet = new HashSet<>();HashSet<String> endSet = new HashSet<>();HashSet<String> visit = new HashSet<>();startSet.add(beginWord);endSet.add(endWord);if (!dict.contains(endWord)) {return 0;}// beginWord --> endWord, 长度至少是2for (int len = 2; !startSet.isEmpty(); len++) {// 开始找邻居HashSet<String> nextSet = new HashSet<>();for (String s : startSet) {// 开始穷举for (int j = 0; j < s.length(); j++) {char[] chs = s.toCharArray();for (char c = 'a'; c <= 'z'; c++) {if (c != chs[j]) {chs[j] = c;}String next = String.valueOf(chs);if (endSet.contains(next)) {return len;}if (dict.contains(next) && !visit.contains(next)) {nextSet.add(next);visit.add(next);}}}}startSet = (nextSet.size() < endSet.size()) ? nextSet : endSet;endSet = (startSet == nextSet) ? endSet : nextSet;}return 0;}

若有收获,就点个赞吧
0 人点赞
