十三起惨痛宕机案例 | 第二辑
Monday, December 25, 2017
12:20 PM
十三起惨痛宕机案例 | 第二辑
2017-12-20talkwithtrend
前不久我们推送了十三起惨痛宕机案例(点击可回顾),目的是提醒大家遇到类似情况小心警惕,受到了大家的欢迎。今天推出第二辑,仍旧是十三起,满满都是血的教训……
(以下案例依旧是来自社区多位会员分享,主要由社区专家孙伟光、崔增顺编辑整理)
01
AIX下NTP设置不当导致的多个集群宕机
事情发生在一段时间之前,接到朋友电话,用户有三套oracle rac集群运行在aix小机上,本地两套,同城机房两套,做完设备搬迁后的一天晚上,其中本地和同城的两套rac突然就整个重启了,而且发生在同一时间点。
网络、小机、存储、数据库分属不同的维保厂商,这就开始了扯皮。各家就开始从自己的方向自证无过错。我去之前内心也比较倾向于oracle的网络心跳出了问题,crs抢vote disk的时候触发了重启。但由于是小机方的代表,仅从aix层面做了排查,未发现明显原因。对各主机宕机的时间做了一个梳理,去和oracle的事件日志去比对。暂时没查到什么东西。
宕机产生的dump发到了IBM原厂,IBM后来出了个报告,根据dump内容定位触发宕机的进程为cssd。oracle dba重点看了那个进程的日志,发现宕机时间前后,时间突然变更,提前了40多秒。dba确认,时间变更过多,cssd进程会导致系统重启,怀疑和时间同步有关。
经检查,3套aix的rac集群使用了同一个ntp server,但有一套没发生问题。对比检查差异,发现没问题的那套主机集群使用xntpd方式配置了时间同步。出问题的主机则直接使用了ntpdate命令做时间更新,并写入了crontab定期执行。检查/var/adm/cron/log日志,发现定时任务的执行时间和cssd故障时间一致。检查时间服务器,发现搬迁后,时间服务器的时间产生了较大偏差,xntpd方式的时间同步在时间偏差大时不会去强制同步,ntpdate命令的方式没有这个限制,会直接进行同步。最终导致了cssd进程检测到过大时间偏差后触发了宕机。
经验分享:配置时间同步时,建议使用xntpd服务的方式,不用直接在定时任务里写ntpdate,因为ntpdate比较粗暴,发生故障时较大的时间偏差会导致应用出现问题,触发无法预知的后果。
由社区会员王巧雷分享
02
采用爱数备份一体机导致宕机
去年我们刚刚入手了一台爱数备份一体机,在测试阶段遇到了一个小例子和大家分享一下:
当时测试各种数据的备份和功能,就在一台系统上安装了爱数备份的代理客户端,客户端安装选项中有一项安装CDP驱动。 当时并没有留意,后来升级客户端版本,另外做了一些其他测试,就把代理客户端卸载了,但是并没有先去卸载CDP驱动,重启后系统就直接起不来了,和爱数的技术支持沟通后了解,需要先卸载CDP驱动,再卸载客户端,否则CDP驱动存在的时候,就会导致系统启动失败。
由社区会员“pysx0503”分享
03
经典双机双存储,某晚主存储异常故障,业务立刻中断
用户经典的双机双存储高可用应用方案。IBM 2P570 PowerHA6.1 两台中端存储通过lvm mirror实现的数据镜像,上面跑着用户信贷系统,报表系统,存储压力较为繁忙。用户每年都会完成一次HA切换演练保证业务高可用。某晚一次存储电源故障,电源还没来得急更换,另外一个电源也坏了。这样主存储宕机了。恰巧这个时候业务也立刻停止了,用户电话里说刚做完的Powerha的演练,很顺利。可今天发生的这事却百思不得其解。
后来经过大量的日志和与用户交流得知,用户之前的一个操作给这次的业务中断埋下了一个大大的”地雷”。
究竟用户自己做的什么操作导致的此次事件呢?
用户业务系统有一个文件系统存储空间不够了,需要扩容,但是目前共享vg里的空间无法满了,需要重新加新的磁盘到vg里,存储管理员分配新的磁盘给两台主机,然后用户通过Powerha cspoc去加盘,扩容FS。就是这么一个操作导致的问题发生。
经验分享:lvm mirror双存储的情况下,我们扩fs需要注意先扩LV,再扩fs,这样能保证数据正确分布在2个存储上,如果在用户这种场景新加磁盘后直接扩fs,那就会造成数据拷贝是2份,但是不能准确地保证分布在两个存储上,有可能存储A分布90% 存储B分布110%。这样一台存储故障,就会直接导致数据的不完整。
由社区会员孙伟光分享
04
HACMP NODE ID 一致导致故障宕机
故障描述:
前些天在论坛闲逛,发现一兄弟的帖子“Power HA 其中一台异常宕机”(发布者:yangming27),点进去一看,发现故障描述和报错信息和我之前遇到的完全一样,基于提醒和血的教训,特将该问题编写成案例,希望大家引以为戒!
我们生产环境有PowerVM虚拟化后的AIX虚拟机2台,灾备环境有PowerVM虚拟化后AIX虚拟机1台,三台虚拟机通过PowerHA XD(基于SVC PPRC远程复制)搭建了跨中心高可用环境,操作系统版本为7.1.2.3,HA版本为7.1.2.6,搭建该环境之前,生产环境的两台AIX是通过HAMCP搭建了本地的高可用环境,为了灾备建设需求,将本地的1台主机通过altdisk_copy的方式复制了一份rootvg至外置存储,并将该外置存储通过SVC PPRC复制至灾备存储卷当中,灾备的虚拟机再挂载该卷,并通过该卷启动操作系统。这样三台AIX虚拟机再重新搭建了PowerHA XD,实现跨中心HA热备。
通过这种方式,我们搭建了三套系统,均通过了HA切换测试,但是运行了一段时间后,其中一套系统的主机故障宕机(关机),资源组切向了备机,发现问题后,第一时间查看errpt日志,如下(这里借用yangming27帖子中的日志截图)
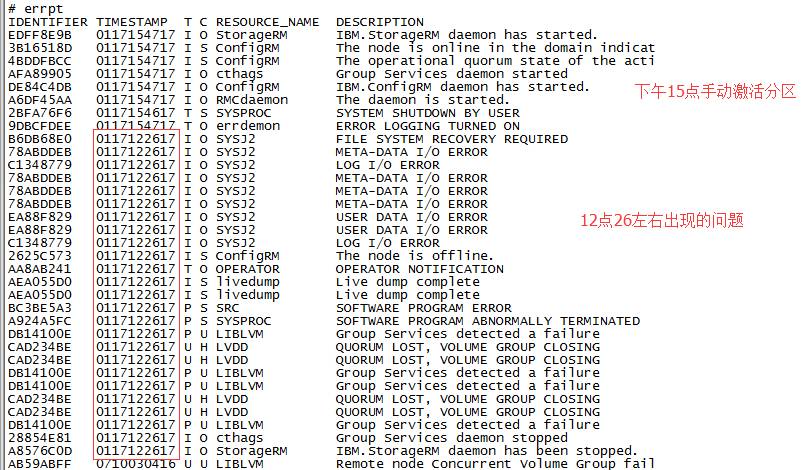
![# errpt IDENTIFIER EDFF8E98 38165180 4800F8cc AFA89905 DE84c4D8 A6DF4 5AA 28FA76F6 goacFDEE 86D868EO 78A8DDE8 C1348779 78A8DDE8 78A8DDE8 78A8DDE8 EA88F829 EA88F829 c1348779 2625C573 AA8A8241 AEA055DO AEA055DO BC38E5A3 A924A5FC 08141 oog CAD2348E CAD2348E 08141 oog 08141 OOE CAD2348E CAD2348E 08141 oog 28854E81 A8576COD AB 59A8FF T 1M E STAM p 0117154717 0117154717 0117154717 0117154717 0117154717 0117154717 0117154617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 0117122617 T T T T c RESOURCE NAME stor ageRM confi gRM confi gRM cthags confr gRM RMC daemon s sys PROC err demon o sysJ2 sysJ2 sysJ2 sysJ2 sysJ2 sysJ2 sysJ2 sysJ2 sysJ2 confi gRM o OPERATOR livedump i vedump sys PROC LIBLVM H LVDD LVDD U LIBLVM U LIBLVM H LVDD H LVDD U LIBLVV cthags stor ageRM U LIBLVM DESCRIPTION 18M. storageRM daemon has started. The node IS online in the domain indicat The operational quorum state of the acti Group servi ces daemon started 18M. configRM daemon has started. The daemon is started. SYSTEM SHUTDOWN BY USER ERROR LOGGING TURNED ON FILE SYSTEM RECOVERY REQUIRED META-DATA I/o LOG I/o ERROR META-DATA I/o META-DATA I/o META-DATA I/o USER DATA I/o USER DATA I/o LOG I/o ERROR ERROR ERROR ERROR ERROR ERROR ERROR 12k26äGtHihlä517]E The node is offline. OPERATOR NOTIFICATION Live dump complete Live dump complete SOFTWARE PROGRAM ERROR SOFTWARE PROGRAM ABNORMALLY TERMINATED Group servi ces detected a failure QUORUM LOST, VOLUME GROUP CLOSING QUORUM LOST, VOLUME GROUP CLOSING Group services detected a failure Group servi ces detected a failure QUORUM LOST, VOLUME GROUP CLOSING QUORUM LOST, VOLUME GROUP CLOSING Group servi ces detected a failure Group servi ces daemon stopped 18M. stora eRM daemon has been stopped Remote no e concurrent volume Group fail](https://cdn.nlark.com/yuque/0/2021/jpg/3018302/1639559561062-88e7188a-238e-47c8-863b-c904f115635a.jpg)
故障分析:
由于操作系统没有开always allow dump,所以并没有产生dump文件,当时分析了很久日志,很是疑惑不解,最终只能提交给IBM后台进行分析,后台也是许多天都没有答复。过了一个星期后,第二套系统也出现了一样的现象,一样的故障,造成主备HA切换,我开始怀疑是HACMP XD实施问题,立马翻阅了一下实施文档,发现在做altdisk_copy时只用了alt_disk_copy -d hdiskx,后面并没有用-O -B -C参数,这些参数主要是用来复制rootvg时,删除原操作系统的配置信息和ODM库的一些信息,这样一来可能就会造成生产主机和灾备备机的操作系统某些信息一致。基于这种怀疑,我复看了errpt报错记录,宕机的主要原因应该是以下几个点:
IBM.StorageRM daemon has been stopped
Group Services daemon stopped
Group Services detected a failure
QUORUM LOST,VOLUME GROUP GROUP CLOSING
猜想是否是QUORUM中保留的两个主备节点信息一致,导致QUORUM关闭。
接着在生产主机运行命令
odmget -q “attribute=’node_uuid’” CuAt
输出:CuAt: name = “cluster0” attribute = “node_uuid” value = “673018b0-7a70-11e5-91fa-f9fe9b9bc3c6” type = “R” generic = “DU” rep = “s” nls_index = 3
在灾备主机运行命令odmget -q “attribute=’node_uuid’” CuAt
输出:CuAt: name = “cluster0” attribute = “node_uuid” value = “67301842-7a70-11e5-91fa-f9fe9b9bc3c6” type = “R” generic = “DU” rep = “s” nls_index = 3
生产主机运行命令
/usr/sbin/rsct/bin/lsnodeid
灾备主机运行命令
/usr/sbin/rsct/bin/lsnodeid
以上发现两个节点的RSCT NODE ID 完全一致
这就是造成信息冲突的点,造成了主服务停止和QUORUM仲裁关闭的元凶。
故障解决:
1.将PowerHA XD的HA服务全部关闭,禁止HA组服务的保护,并运行命令
/usr/sbin/rsct/bin/hags_stopdms -s cthags
/usr/sbin/rsct/bin/hags_disable_client_kill -s cthags
2.停止HA的ConfigRM服务和cthags服务
stopsrc -s IBM.ConfigRM stopsrc -s cthags
3.重新配置RSCT节点
/usr/sbin/rsct/install/bin/recfgct
4.重启所有3台操作系统
shutdown -Fr
5.启动HACMP服务和资源组,并检查RSCT NODE ID
经验分享:通过以上方法,彻底解决了三套系统的HACMP主机宕机问题,建议以后做类似alt_disk_copy时,一定要带上-B -C -O参数,保持新操作系统的洁净,以防碰到类似的莫名其妙的问题。
由社区会员“jxnxsdengyu”分享
**_05
Power 570/595 宕机
事情起因:
由于机器宕机是在周六,是客户的核心应用,但周六客户没有人上班,当周一上班的时候发现所有的办公,邮件系统等一半的核心应用不能访问,经过现场机房管理人员的临时排查,发现小机Power595后面所有的I/O柜掉电,Power570黄灯亮起,绿灯慢闪。
工程师到达现场,按照与客户沟通好结果,我们开始干活,大概折腾了6个小时,Power595 还是没有启动起来,但power570可以正常访问了。为了赶紧让客户生产数据,我们临时决定,用power570临时做个lpar让存储链接过来,先拉起应用,再又折腾了3个多小时之后,所有应用都可以正常访问。我们继续排查Power595,我们更换了CEC DCA 内存板,CPU 都没有解决问题,最后更换了pubook问题解决了,花费时间3天。
问题原因:
电工改造线路,造成了机房断电,UPS临时接管,由于电池放了太久,机器功率太大,造成低电压运行,造成设备不能正常工作,更为关键的是电工出现问题之后没有及时检查电路,根据师傅的陈述大概过了1分钟又把交流电送出去,这个电压冲击是很厉害的,经排查此电工无证施工,客户已经提起诉讼。
由社区会员“shizhe1030”分享
06
ERP备份导致的一起宕机案例
现象回顾:
某日凌晨,其中一台ERP数据库主机宕机。AIX.5.3 HACMP RAC数据库环境。
故障分析:
宕机时间点是在备份期间。通过分析数据库日志、系统日志、发现导致数据库停库的主要原因是由于HACMP的一个守护进程haemd发生自动重启,由于oracle数据库和haemd进程之间有关联,因此数据库在发现haemd重新启动后也自动停止。
经IBM工程师及实验室分析,Haemd自动重新启动的原因是由于在一定期间内(参数为2分钟)没有给HACMP系统响应,其原因之一是由于系统过于繁忙,没有响应Haemd。
随后分析结果发现在备份期间,从存储看系统不是很繁忙;但ERP数据库服务器主机性能异常:有时会出现阶段性的不响应现象,同时系统I/O高。停止备份后,这种现象消失。
经IBM实验室协助,初步经过分析:
1)AIX系统内存分为计算类和非计算类内存。非计算类内存主要用于文件操作CACHE,以便提高文件再次读写的性能。目前ERP生产数据库占用了近20G内存作为文件系统CACHE。
2)当文件系统CACHE有空间时,写文件操作将不会产生阻塞,当文件系统 CACHE无空间时,系统将会根据内部策略,挤出部分CACHE。当无法找到空闲的CACHE时,会等待系统调整出空闲的CACHE。当出现大量等待时,系统可能出现无响应的状态。
解决方案:
考虑到将来数据量的增加,如果无法解决较大I/O对系统的影响过大的问题,这个隐患将一直存在。
调整该备份文件系统的属性,在该文件系统的I/O请求到达一定值的情况下,阻塞对该文件系统的读写I/O,从而保证预留足够的资源给系统。具体参数为Maxpout、Minpout。
经验分享:Maxpout、Minpout参数的选择,是和具体环境相关的,没有一个统一的建议值。若该参数设置不合理,可能会影响到文件系统的读写操作。而合适的参数需要经过设置、观察来确定。
由社区会员孙伟光分享
07
weblogic宕机问题排查
问题现象:
系统持续运行2-3天,中间件出现宕机
系统运行期间只要访问weblogic控制台,操作几次后中间件宕机
报错日志:![<2017-7-29 6 SO CST> -HTTF weblogic servlet. jsp CompilationException Failed to Exception occurred while processing ' /hom java. lang ClassLoader. definetlassl (Native compile YEF /infopatll/jsp Method) tbank path /xtbank spec vers10n:2.5\]\] Root c/deploy/app/xtbank/infopath/jsp/wf_form cause of Serv1etException hangneidongtai jsp' java. lang .0ut0fMemoryError: PermGen space at at at at at at at at at at at at java lang Classl_oader. defineC1ass (Classl_oader. java 800) java security SecureC1assLoader. defineC1ass (SecureC1assLoader. java :142) java net LIRLC1assLoader. defineC1ass (LIRLC1assLoader. java 449) java net LIRLC1assLoader. java 71) java net LIRLC1assLoader$1 run (LIRLC1assLoader. java 361) java net LIRLC1assLoader$1 run (LIRI_C1assLoader. java BSS) java security AccessContr011er. doprivileged (Native Method) java net LIRLC1assLoader findC1ass (LIP,LC1assLoader. java 354) java lang Classl_oader. loadC1ass (Classl_oader. java 425) Launcher$AppC1assLoader. loadC1ass (Launcher. java 308) sun . ml sc java lang ClassLoader. loadC1ass (ClassLoader. java 358) com bea core repackaged jclt internal compiler Compiler. initializeParser(Compi1er. java 665) java 28 ) com bea core repackaged jclt internal compiler. Compiler. java weblogic. weblogic weblogic weblogic webloqic weblogic. weblogic asp weblogic . internal. . internal. internal java -10TJavaCompi1er generateByteCode (0üTJavaCompi1er. java 103) . internal. java. JavaSourceFi1e. codeGen (-1avaSourceFi1e. java: 211 internal java JavaSourceFi1e codeGen (OavaSourceFi1e java 201 internal ProxySourceFi1e compileGeneratedFi les (ProxySourceFi1e java 310) internal ProxySourceFi1e codeGen (ProxySourceFi1e java 248) internal SourceFi1e codeGen (SourceFi1e java 324) client Clientl_lti1sImp1$CodeGenJob run (Clientl_ltilslmpl client -lob performoob (Job Java 83) : 157) 660)](/uploads/projects/wsbo@lm28so/a402c25414f50bc169d73e6716fd7580.jpeg)
分析:
通过报错日志分析,为内存溢出,且为非堆内存溢出,这种情况一般需要调整:PermSize的大小。
解决过程:
调整weblogic配置参数:setDomainEnv.sh 设置setDomainEnv.sh 为512。
调整后重启系统,发现问题依旧,并没有解决宕机问题。
确认修改参数是否生效:生成javacore来分析(kill -3 进程ID)截图如下:<br />我们发现参数并没有生效。继续分析参数为什么没有生效。<br />
Weblogic中的 commEnv.sh ,发现JAVA_VENDOR为 N/A<br /><br />而setDomainEnv.sh 中PermSize 的设置为:<br />!["${JAVA VENDOR} " - " if [ $ { MEM MEM ARGS} export MEM ARGS "{JAVA VENDOR} " - if [ MEM ARGS} export MEM ARGS "{USER MEM ARGS} " if [ MEM MEM export MEM ARGS DEV then ARGS} then PERM $ { MEM SIZE} " MAX PERM SIZE} " ${MEM MAX — "Apple" ] then $ { MEM $ { MEM MAX MAX PERM then PERM SIZE} " SIZE} " environment variable set, use -{1dL JAVA PROPERTIES- — "—Dp lat form. home— export JAVA PROPERTIES HOME} —DWI s . home— HOME} -${1dLS —Dweb logic . home— HOME}](/uploads/projects/wsbo@lm28so/ff4b93b32b68a6724bb35bf499ba0c56.png)
此处的参数并没有 设置我们需要的Open JDK的 JAVA_VENDOR的N/A 的赋值,所以非堆内存的设置并未生效。
注意:正常 open jdk 的JAVA_VENDOR 为Oracle的,但是配置文件却为:N/A,可能是weblogic的兼容性问题,或者人为改动导致,找到原因了,这个问题就没有细究。
解决方案:
修改commEnv.sh , JAVA_VENDOR为 Oracle、HP、IBM、Apple中的任何一个
在startWeblogic中,单独定义:MEM_ARGS=”-Xms2048m -Xmx2048m -XX:PermSize=1024m”
验证方案:
采取第二种方案:
1)在原始默认环境,进行12个小时的循环操作,并持续访问weblogic控制台。
2)在修改后的环境,持续访问weblogic控制台,生成javacore文件看参数是否生效。并进行50人高强度的并发测试20个小时,看是否会重现宕机问题。
在方案的第一步,系统运行2小时,访问控制台,中间件宕机,系统无法访问。
在方案的第二步,系统在50人高强度的并发测试20小时的情况下,响应正常。频繁访问控制台并未发现任何异常。通过生成javacore 发现非堆内存正常生效。
由社区会员“gu y 011”分享
08
P550/P570宕机案例
某周末,客户致电,说核心业务无法访问。工程师到达现场,发现客户环境(P550/P570—HACMP)P550两台小机均关机。发现客户现场有部分服务器也已处于关机掉电状态。此时客户才发现,市电周五晚上断电过,但是客户机房配备有2台UPS,机房设备一半一半分别接到2台UPS上。排查发现其中一台UPS无法供电。而两台小机均有一路电源接到该UPS,导致市电断电后,直接宕机。
后将小机通电开机,发现P550无法开机,CPU VRM稳压模块报错,由于客户业务较为重要,将P570已经拉起来,准备将HA集群在IBM P570单节点运行。却发现HA无法将Oracle数据库拉起。由于时间紧迫,手动在P570网卡上添加IP别名后,手动挂载VG,恢复业务。
后续,将P550稳压模块进行更换后,发现仍然无法开机,又出现新的报错:11002630,再次更换CPU板后,P550小机正常开机。安排停机窗口进行排查恢复。在处理过程中,集群出现意外,在HA拉起来后,经业务测试,发现/orafile丢失一部分数据,此时备份数据最新的为前一天晚上23点,单天的数据未做备份,只能采取数据恢复,最后成功将数据恢复回来。重新配置HA,模拟故障切换,测试业务,验证数据完整性,业务恢复正常!
由社区会员“ACDante”分享
09
AIX6100-06-06系统bug引起down机
某机器操作系统版本6100-06-06,系统down机,生成dump文件。
Problem:
System crash with following stack
CRASH INFORMATION:
CPU 3 CSA F00000002FF47600 at time of crash, error code
for
LEDs: 30000000
pvthread+02BD00 STACK:
[00009500].simple_lock+000000 ()
[00450E24]netinfo_unixdomnlist+000824 (??, ??, ??, ??,
??, ??)
[0451214C]netinfo+00006C (??, ??, ??, ??, ??, ??)
[004504DC]netinfo+0000FC (??, ??, ??, ??)
[00003850]ovlya_addr_sc_flih_main+000130 ()
[kdb_get_virtual_memory] no real storage @
FFFFFFFFFFFEF20
[100002640]0000000100002640 ()
[kdb_read_mem] no real storage @ FFFFFFFFFFF5E30
bug原因:
File lock is taken before checking whether the file type is socket.
该故障因netstat -f unix 命令引起系统 crash, 是IBM bug 引起
建议单独提升bos.mp64包补丁包或者整体升级到6100-06-12-1339(SP12)
官网解释:
IV09793: SYSTEM CRASH IN NETINFOUNIXDOMNLIST APPLIES TO AIX 6100-06
http://www-01.ibm.com/support/docview.wss?uid=isg1IV09793
File lock is taken before checking whether the file type is socket.
由社区会员“qb306”分享_
10
P570宕机案例
IBM 570意外宕机,处理过程如下:
1、首先查看asmi日志,电源和风扇故障,更换了2个电源和1个风扇后,可以启动到standby模式。但是非常多的firmware报错。
2、升级微码到sf240-417后,微码报错消失。
3、激活分区失败,hmc终端会出现几秒的”ide inited failed“提示,然后消失。接着卡死,报找不到硬盘。
4、观察外观,发现后端的光纤卡灯特别弱,有时会不亮。
5、查了下570的红皮书结构图,发现ide controller(红线圈住部分)同时处理pci设备和硬盘背板设备过来的io,根据现有故障现象,判定ide controller有故障。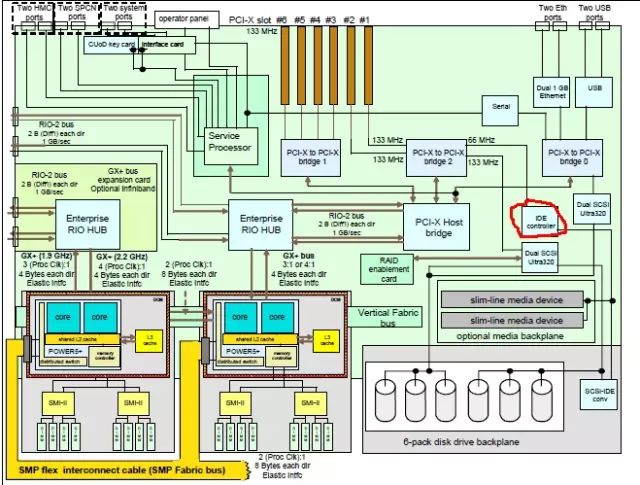
6、通过ibm system information center,定位到ide controller的location code 为p1-15,不是一个可替换的FRU,必须随同IO backbone(就是主板)一起更换。
7、更换io backbone后,系统正常启动,进入系统微调后,一切正常。
由社区会员王巧雷分享
11
某企业HACMP软件,在网络交换机变更时引起down机
某企业HA cluster log, IP switch down时引起双节点halt,系统版本7100-03-03,HA版本6.1sp13
Error description
In HACMP 6 with rsct.core.utils 3.1.4.9 or higher, if all
IP networks are lost and at least one non-IP network is
functioning, the Group Services subsystem will core dump when
trying to send packets to be routed through Topology Services
(across the non-IP connection). This will cause a node halt.
Customers with PowerHA 7, or HACMP 6 customers with no non-IP
networks (such as rs232 or disk) are not in danger. Also this
will not happen if only one node is still running, since there
will be no other cluster members to send messages to.
日志如下: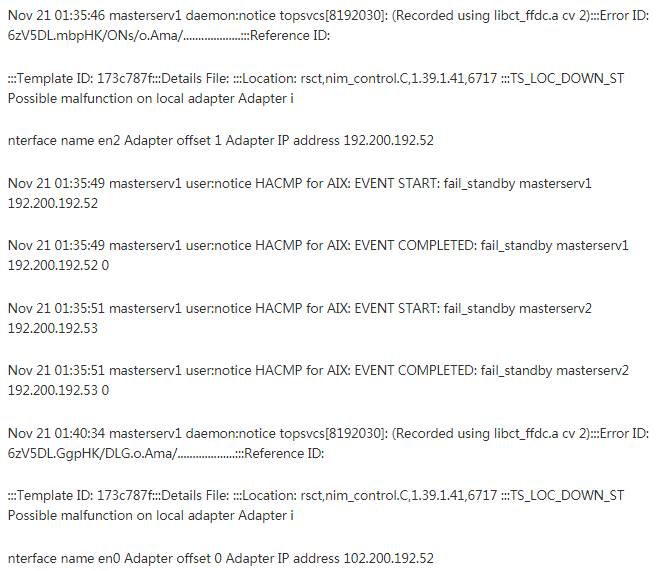<br />![Nov 21 01:40:36 masterservl localO:crit clstrmgrES[15925314]: Sat Nov 21 01:40:36 announcementCb: Callec state=ST_UNSTABLE, provider token 1 Nov 21 01:40:36 masterservl localO:crit clstrmgrES[15925314]: Sat Nov 21 01:40:36 announcementCb: GsToken 2, AdapterToken 3, rm_GsToken 1 Nov 21 01:40:36 localO:crit clstrmgrES[15925314]: Sat Nov 21 01:40:36 announcementCb: GRPSVCS announcment code=512; exiting Nov 21 masterse,vl localO:crit cistrmgrES[15925314: Sat Nov 21 CHECK FOR FAILURE OF RSCT SUBSYSTEMS (topsvcs or grpsvcs) Nov 21 01:40:36 masterservl daemon:errlerror haemd[15204586]: haemd: 2521-032 Cannot d ispatch group services (1). Nov 21 01:40:36 masterservl user:notice HACMP for AIX: clexit.rc : Unexpected termination of clstrmgrES. Nov 21 01:40:36 masterservl user:notice HACMP for AIX: clexit.rc : Halting system immediately!!!](/uploads/projects/wsbo@lm28so/d9f9e94d9a3841d56d24a15cfdeab75f.jpeg)
原因是补丁IV55293: HAGSD CORE DUMP WHEN IP NETWORKS LOST, 需要升级rsct文件集。
官网解释:
http://www-01.ibm.com/support/docview.wss?uid=isg1IV55293
由社区会员“qb306”分享
12
巡检不仔细 Power595宕机
事件起因,本来巡检已经发现其中的一个I/O柜电源故障,在线更换走脚步的时候,脚步执行到一半引起该I/O柜突然掉电,重启了该I/O柜。
原因:一线工程师巡检时候不够仔细,因为该同一个I/O其实坏了2个电源,只不过另外一个没有报出来具体的位置,但已经报出来该I/O的部件号,但也说明了IBM小机没有完全报错具体槽位,只报错了大概的位置。
解决方法:设备下电,更换两个I/O DCA,然后设备开机,问题解决。
由社区会员“shizhe1030”分享
13
X86史上最离谱的宕机事件
硬件: IBM的X3650 操作系统: suse 9
linux系统无法远程登陆,用KVM登录上去看发现定在操作系统页面不能动。
重启操作系统后,在操作系统message日志里面查看到如下错误:![NOV 20 1500107 HBLT-ADC-SMS kernel: noc: irq timeout: status=oxco { ausy \] Nov 20 15:00:07 HBLT-ADC-SMS kernel: hdc: irq timeout: error=OxdOLastFailedSense OxOd NOV 20 15.00137 FELT-ADC-SMS kernel: ATARI reset timed-out: status=ox80 Nov 20 15:01:12 HBLT-ADC-SMS kernel: idel: reset timed-out, status=Ox80 Nov 20 15:01:12 HBLT-ADC-SMS kernel: hdc: status timeout: status=Ox80 { Busy } Nov 20 15:01:12 HBLT-ADC-SMS kernel: hdc: status timeout: error=Ox80LastFailedSense Ox08 Nov 20 15:01:12 HBLT-ADC-SMS kernel: hdc: drive not ready tor command NOV 20 1501142 HBLT-ADC-SMS kerne•: noc: ATAPI reset timed-out, #dt -all Filesystem Idev/sda2 proc systs tmpts devpts Idev/hdc 1 K-ölocks 132733384 Used Available Use% Mounted on 4690660 121300244 40/0/ O o 2070692 o O o o o o o O - Iproc /sys 8 2070684 /dewsnm o O - /dev/pts - /media/cdrecorder](/uploads/projects/wsbo@lm28so/992b6b8cb346b3f1fcc65021b873b3df.jpeg)
经过咨询novell和IBM工程师,结论是IBM这类服务器在装linux系统的时候,如果光驱有问题确实是会导致宕机。
经硬件工程师检查,是光驱坏了……坏了……
编者按:*宕机原因千万种,这个宕机有点冤
由社区会员“hp_hp”分享
更多相关文章请点击阅读原文
长按二维码关注公众号
阅读原文
已使用 OneNote 创建。

若有收获,就点个赞吧
0 人点赞

{kind=link}