- 巨杉Tech | 读写分离机制与实践
- 2.1 复制组
- 在 SequoiaDB 巨杉数据库中,复制组是指一份数据的多个拷贝,其中每一份数据拷贝被称为副本,也称为节点或实例。
- 2.2 会话
- 2.3 写请求处理
- 所有的写请求都只会发往主节点。数据写入主节点后记录在事务日志 replicalog。备节点从主节点异步复制 replicalog,并通过重放 replicalog 来复制数据。
- 2.4 读请求处理
- 读请求可以通过设置会话或协调节点的 PreferedInstance 参数,来控制会话读操作优先选择的实例。
- 2.5 注意事项
- 3. 1 访问SequoiaDB的两种方式
- SequoiaDB 巨杉数据库有两种访问模式。
- 3.2 配置读写分离
- 读写分离可以在会话级别配置,也可以在节点级别配置。假设场景为想要在主节点写,备节点读,则配置方式如下。
- 3.3 其他相关配置
- 4.1 SequoiaDB Shell方式
- 该方式支持在会话级别配置读写分离策略。
- 4.2 SQL 方式
巨杉Tech | 读写分离机制与实践
Tuesday, February 18, 2020
9:54 PM
|
| | —- |
| Tags: #微信 |
速读摘要
SequoiaDB巨杉数据库是一款开源的金融级分布式关系型数据库,主要面对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。更改会话的PreferedInstance参数为S,即从备节点读,再次使用explain测试相同查询语句。由以上结果可知查询走了备节点,读写分离测试成功。SequoiaDB Shell中设置协调节点的默认preferedinstance参数为”s”,即从备实例读。
原文约 3985 字 | 图片 7 张 | 建议阅读 8 分钟 | 评价反馈
巨杉Tech | 读写分离机制与实践
原创 巨杉技术社区 巨杉数据库
1. 背景
SequoiaDB 巨杉数据库是一款开源的金融级分布式关系型数据库,主要面对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。用户可以在 SequoiaDB 巨杉数据库中创建多种类型的数据库实例,如MySQL, PostgreSQL 与 SparkSQL,以满足上层不同应用程序各自的需求。
在许多业务下,应用对数据库的请求往往读多写少,这时对数据库的读操作首先成为性能瓶颈。同时,由于读写同一库会有锁冲突,导致写的性能也会降低。为了解决以上问题,可以使用读写分离架构,即将库分为主库和从库,主库用于写数据,而多个从库用于读数据。这样不仅减少了单一节点的负载压力,而且会避免锁等待,可以解决数据库很大一部分的读性能瓶颈。
读写分离典型的使用场景为HTAP混合负载场景。HTAP 混合负载意味着数据库既可以运行 OLTP (Online Transactional Processing) 联机交易,也可以同时运行 OLAP (Online Analytical Processing) 统计分析业务。但是,用户想要在同一个数据库中针对同样的数据在同一时刻运行两种不同类型的业务,往往数据库服务器中的 CPU、内存、I/O 和网络等硬件资源会形成较多的资源争用,导致对外的联机交易服务性能与稳定性受到影响。在SequoiaDB巨杉数据库中,为了解决资源争用,可以给OLTP和OLAP业务配置不同的读写分离策略,同时可以通过创建数据共享但不同类型的数据库实例(例如MySQL实例与SparkSQL实例),分别服务于联机交易业务与统计分析业务,做到针对同样数据的联机交易与统计分析业务同时运行且互不干扰。
2. 读写分离机制
2.1 复制组
在 SequoiaDB 巨杉数据库中,复制组是指一份数据的多个拷贝,其中每一份数据拷贝被称为副本,也称为节点或实例。
节点有三种类型:
- 编目节点:保存数据库的元数据信息。
- 协调节点:接受请求,将请求分发到所需要处理的数据节点。
- 数据节点:保存用户数据信息。
一个复制组内的节点有两种不同的角色:主节点和备节点,每个节点在复制组内都有一个唯一id,名称为instanceid,取值范围为1-255。正常情况下,一个复制组内有且只有一个主节点,其余为备节点。
通常情况下,一个复制组的多个节点放在不同的服务器上,这样可以满足数据库的高可用与灾备需求。同时,因为多个节点存放在不同的服务器上,因此可以通过配置策略让读写会话访问不同的节点,从而实现读写分离。
SequoiaDB 巨杉数据库的读写分离机制如下图所示: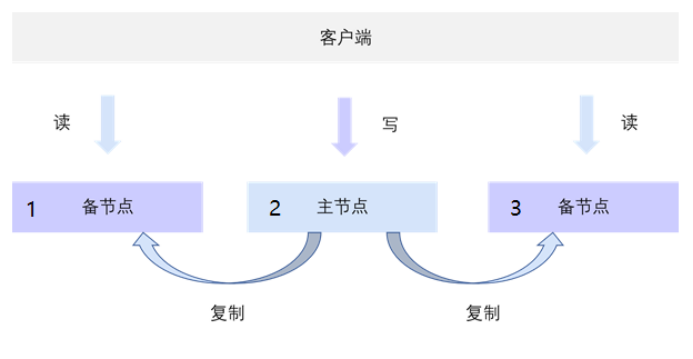
当发生写操作时,主节点写入数据并复制数据到备节点。
当发生读操作时,SequoiaDB可以将读请求发送至读写分离策略指定的节点,以降低读写 I/O 冲突和锁冲突,提升集群整体的吞吐量。读写分离策略可以设置为从主节点读,从备节点读,以及指定id从具体节点读。如上图,三个节点的id分别是1,2,3,可以指定只在3节点上读数据。
2.2 会话
当数据库客户端建立一个与服务端的连接,并发送一个操作请求后,服务端通常需要保存这个操作的上下文信息,如客户端的地址信息、请求的操作类型和操作执行的进度信息等,这个上下文就是会话。
在SequoiaDB 巨杉数据库中,不仅可以给协调节点配置默认的读写分离策略,还可以在会话级别指定读操作选择的节点,从而使读写分离更加灵活。
2.3 写请求处理
所有的写请求都只会发往主节点。数据写入主节点后记录在事务日志 replicalog。备节点从主节点异步复制 replicalog,并通过重放 replicalog 来复制数据。
2.4 读请求处理
读请求可以通过设置会话或协调节点的 PreferedInstance 参数,来控制会话读操作优先选择的实例。
PreferedInstance 的取值列表为:”M”, “m”, “S”, “s”, “A”, “a”, 1-255。用户可以使用数组指定多个取值,取值具体含义如下表:
如果指定会话多个实例符合 PreferedInstance 的条件时,选择哪个实例取决于会话的PreferedInstanceMode参数,PreferedInstanceMode参数取值如下:
2.5 注意事项
1) 当会话没有指定—preferedinstance和—preferedinstacemode时:
—preferedinstance 的默认值是 “M”,即从主节点读数据,—preferedinstacemode 的默认值是 “random”,即从复制组中候选实例中随机选取一个实例进行读操作。修改默认值可以通过SequoiaDB Shell中的方法db.updateConf({preferedinstance:”xx”},{GroupName:”SYSCoord”})实现。
2) 如果多个 1-255 的实例和 “M” 或 “m” 一起指定,满足指定实例中的主实例会被优先选择,当没有满足指定的实例时选择主实例。如 [ 1, 2, “M” ] 表示优先从实例 1 和实例 2 中的主实例读取,如果不存在实例 1 和实例 2,则从主实例读取。
3) 如果多个 1-255 的实例和 “S” 或 “s” 一起指定,满足指定实例中的备实例会被优先选择,当没有满足指定的实例时选择备实例。如 [ 1, 2, “S” ] 表示优先从实例 1 和实例 2 中的备实例读取,如果不存在实例 1 和实例 2,则从任意一个备实例读取。
4) 如果指定多个 “M”、”m”、”S”、”s”、”A”、”a” 实例,则只有第一个生效。
5) 如果没有符合 PreferedInstance 的实例,这时会话将随机选择使用上一次写操作的实例,即可读写(主)实例进行查询(如无写操作,则随机选取实例)。
6) 在节点配置了instanceid的情况下,按照instanceid进行判断读操作选取的实例。在节点没有配置instanceid的情况下,按照节点的nodeid在组内的排序序列(从1开始)作为instanceid来进行选取,例如 组 db1 中有3个节点 [ { NodeID:1001}, {NodeID:1004}, {NodeID:1002} ],那么其节点的 instanceid 分别为 1, 3, 2。如果指定的1-255的实例ID大于数据组内的节点总数,则实例ID对节点总数取模后在组内按照nodeid的排序顺序选取。
3. 配置读写分离
3. 1 访问SequoiaDB的两种方式
SequoiaDB 巨杉数据库有两种访问模式。
一种访问方式是直接访问 SequoiaDB 的集群。具体操作方式是通过自带的接口工具sdb使用 SequoiaDB Shell 进行访问。SequoiaDB Shell的语法类似于JavaScript,传入参数一般为 JSON 格式,具体方法请参考官方文档。
另外一种访问方式是通过 SQL 访问 SequoiaDB。SequoiaDB 巨杉数据库支持 MySQL、PostgreSQL 与 SparkSQL 三种关系型数据库实例。比如创建SequoiaSQL-MySQL实例, 该实例完全兼容MySQL语法和协议,用户可以使用SQL语句访问 SequoiaDB 数据库,完成对数据的增、删、查、改操作以及其他MySQL语法操作。
当涉及到更改SequoiaDB底层的一些参数时,如修改配置读写分离策略的PreferedInstance参数,往往需要使用SequoiaDB Shell方式进行配置。
3.2 配置读写分离
读写分离可以在会话级别配置,也可以在节点级别配置。假设场景为想要在主节点写,备节点读,则配置方式如下。
1)会话级别
SequoiaDB Shell中执行如下语句:
db=new Sdb();db.setSessionAttr({PreferedInstance:”S”});
2) 节点级别
SequoiaDB Shell中执行如下语句:
db=Sdb();db.updateConf({preferedinstance:”S”},{GroupName:”SYSCoord”});
3.3 其他相关配置
配置读写分离时有可能需要控制主备节点的分布情况,也有可能用到节点的instanceid,本节详细介绍怎么配置这些内容。
1)主实例选举
SequoiaDB 巨杉数据库中可以通过设置实例的weight属性来决定复制组选举哪个实例为主实例。命令如下:
db.updateConf({weight:100},{HostName:”sdb01”,ServiceName:”11850”})> db.getRG(“group1”).reelect()
2)给实例设置instanceid
在使用复制组对象创建某个实例对象时可以指定instanceid的值,该值的范围在1-255。
- 修改instanceid为1-255之间的任意值
db=newSdb(“localhost”,11850)> db.updateConf({instanceid:2});
- 该配置需要重启生效,重启11850节点
sdbstop-p 11850sdbstart-p 11850
Note:
- instanceid 是针对于一个复制组而言的
- 更改instanceid之后需要使用db.invalidateCache()手工清一下协调节点的缓存
4. 读写分离测试
在上文中,配置读写分离策略均需要使用SequoiaDB Shell,配置完成之后,既可以使用SequoiaDB Shell的方法查询,又可以使用SequoiaSQL-MySQL通过标准的SQL查询。以下分别测试两种场景。
4.1 SequoiaDB Shell方式
该方式支持在会话级别配置读写分离策略。
SequoiaDB巨杉数据库默认从主节点读, 模拟一个查询语句并查看执行计划,结果如下:
sdb ‘db.company.employee.find().explain({run:true})’{“NodeName”: “sdb01:11850”,……}
由上面测试可知当前读操作在主节点上进行。
更改会话的PreferedInstance参数为S,即从备节点读,再次使用explain测试相同查询语句。结果如下:
sdb ‘db.setSessionAttr({PreferedInstance:”S”})’sdb ‘db.company.employee.find().explain({run:true})’{“NodeName”: “sdb03:11850”, ……}
由以上结果可知查询走了备节点,读写分离测试成功。
4.2 SQL 方式
该方式仅支持在节点级别配置读写分离策略。
- SequoiaDB Shell中设置协调节点的默认preferedinstance参数为”s”,即从备实例读。
sdb‘db=Sdb()’sdb‘db.updateConf({preferedinstance:”S”},{GroupName:”SYSCoord”})’
- 更改MySQL配置文件参数,添加如下参数。vi /MySQL实例安装目录/auto.cnf。
[mysqld]sequoiadb_use_transaction=OFF
- 重启mysql实例
sdb_sql_ctlstopallsdb_sql_ctlstartall
- 进入MySQL查看事务是否关闭成功
mysql> show variables like “sequoiadb_use_transaction”;+—————————————-+———-+| Variable_name | Value |+—————————————-+———-+| sequoiadb_use_transaction | OFF |+—————————————-+———-+1 row in set (0.00 sec)
- 在MySQL端对一个大表进行表扫描查询(2亿数据)
mysql> select * from company.employee;
- 使用sdblist -l查看哪些是备节点,哪些是主节点
SvcNamePRY GroupName 11810Y SYSCoord 11820N SYSCatalogGroup 11830Y group3 11840N group2 11850N group1 11860Y group4 12000Y SYSCoord
- 使用top命令查看各节点压力
%CPU %MEMTIME+ COMMAND 28.8 8.5 2:27.81sequoiadb(11850) D 28.5 9.3 2:32.03sequoiadb(11840) D 0.3 8.1 3:06.69sequoiadb(11830) D 0.2 8.7 2:27.99sequoiadb(11860) D
可以看出备节点上的压力明显较大,读写分离测试成功。
总结
读写分离架构能够有效减少单一节点的负载压力,同时避免锁等待,解决数据库很大一部分的读性能瓶颈。
往期技术干货
巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool
巨杉Tech | 基于Kafka+Spark+SequoiaDB实时处理架构快速实战
巨杉Tech | SequoiaDB数据域及存储规划
巨杉Tech | SparkSQL+SequoiaDB 性能调优策略
巨杉Tech | 使用 etlAlchemy 工具迁移数据实战
巨杉Tech | Hbase迁移至SequoiaDB 实战
巨杉Tech | SequoiaDB 巨杉数据库高可用容灾测试
巨杉Tech | 使用 SequoiaDB + Docker + Nodejs 搭建 Web 服务器
巨杉学习笔记 | SequoiaDB MySQL导入导出工具使用实战
巨杉内核笔记 | 会话(Session)
180秒揭秘数据库金融级灾备架构


点击阅读原文,获取更多精彩内容~
文章已于修改
阅读原文
在看
已使用 OneNote 创建。

若有收获,就点个赞吧
0 人点赞
