
Card Table
由于做YGC时,需要扫描整个OLD区,效率非常低,所以JVM设计了CardTable, 如果一个OLD区CardTable中有对象指向Y区,就将它设为Dirty,下次扫描时,只需要扫描Dirty Card 在结构上,Card Table用BitMap来实现
只记录到块,具体还要扫描
CMS
CMS
CMS的问题
Memory Fragmentation 内存碎片化
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction 默认为0 指的是经过多少次FGC才进行压缩
Floating Garbage 浮动垃圾

初始标记
并发标记
重新标记 STW
如果在这个过程中,垃圾又被引用了,重新标记 =》 那是如何解决漏标呢?:
并发清理
多线程清理时会产生浮动垃圾,只能下次再清理
Concurrent Mode Failure 产生:if the concurrent collector is unable to finish reclaiming the unreachable objects before the tenured generation fills up, or if an allocation cannot be satisfiedwith the available free space blocks in the tenured generation, then theapplication is paused and the collection is completed with all the applicationthreads stopped(并发模式失败:如果并发收集器无法在终身生成填满之前完成回收无法访问的对象,或者如果终身生成中的可用可用空间块无法满足分配,然后应用程序暂停,收集完成,所有应用程序读取停止) 解决方案:降低触发CMS的阈值 PromotionFailed 解决方案类似,保持老年代有足够的空间 –XX:CMSInitiatingOccupancyFraction 默认 92% 可以降低这个值,让CMS保持老年代足够的空间
CMS日志分析
执行命令:java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC com.mashibing.jvm.gc.T15_FullGC_Problem01
[GC (Allocation Failure) [ParNew: 6144K->640K(6144K), 0.0265885 secs] 6585K->2770K(19840K), 0.0268035 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
ParNew:年轻代收集器 6144->640:收集前后的对比 (6144):整个年轻代容量 6585 -> 2770:整个堆的情况 (19840):整个堆大小
[GC (CMS Initial Mark) [1 CMS-initial-mark: 8511K(13696K)] 9866K(19840K), 0.0040321 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]//8511 (13696) : 老年代使用(最大)//9866 (19840) : 整个堆使用(最大)[CMS-concurrent-mark-start][CMS-concurrent-mark: 0.018/0.018 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]//这里的时间意义不大,因为是并发执行[CMS-concurrent-preclean-start][CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]//标记Card为Dirty,也称为Card Marking[GC (CMS Final Remark) [YG occupancy: 1597 K (6144 K)][Rescan (parallel) , 0.0008396 secs][weak refs processing, 0.0000138 secs][class unloading, 0.0005404 secs][scrub symbol table, 0.0006169 secs][scrub string table, 0.0004903 secs][1 CMS-remark: 8511K(13696K)] 10108K(19840K), 0.0039567 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]//STW阶段,YG occupancy:年轻代占用及容量//[Rescan (parallel):STW下的存活对象标记//weak refs processing: 弱引用处理//class unloading: 卸载用不到的class//scrub symbol(string) table://cleaning up symbol and string tables which hold class-level metadata and//internalized string respectively//CMS-remark: 8511K(13696K): 阶段过后的老年代占用及容量//10108K(19840K): 阶段过后的堆占用及容量[CMS-concurrent-sweep-start][CMS-concurrent-sweep: 0.005/0.005 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]//标记已经完成,进行并发清理[CMS-concurrent-reset-start][CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]//重置内部结构,为下次GC做准备
CMS常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads CMS线程数量
- -XX:CMSInitiatingOccupancyFraction 使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收)
- -XX:+UseCMSCompactAtFullCollection 在FGC时进行压缩
- -XX:CMSFullGCsBeforeCompaction 多少次FGC之后进行压缩
- -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction 达到什么比例时进行Perm回收
- GCTimeRatio 设置GC时间占用程序运行时间的百分比
- -XX:MaxGCPauseMillis 停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1
首先回收的是垃圾最多的那个region特点

G1
新老年代比例为5%-60%
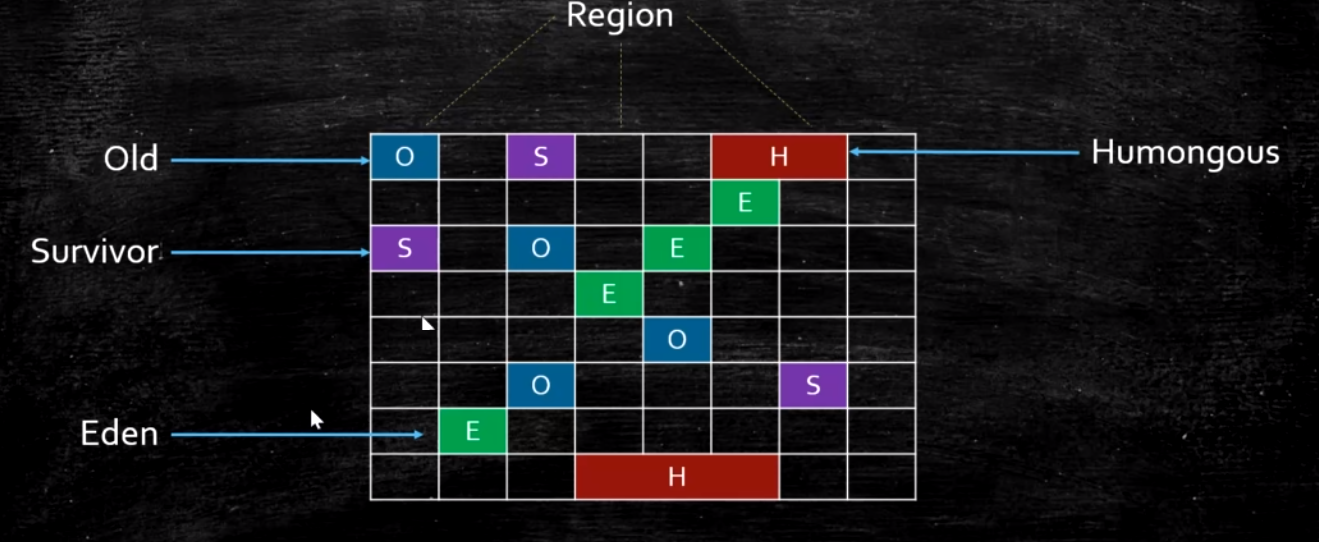

RSet(RemenberedSet)
每个Region里面都有一个RSet(HashSet)
记录了其他Region中的对象到本Region中的引用,详细到对象
使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只需要扫描RSet即可
MixedGC
三色标记


GC何时触发
YGC
FGC(1.10之前用的是Serial Old
为什么使用SATB(关注灰色-》白色引用取消)
引用消失时,如果没有黑色指向白色,引用会被push到堆栈
下次扫描标记时,由于有RSet的存在,可以直接找到这个指向白色的引用而不用全部扫描堆
如果G1产生FGC,如何解决?
- 扩内存
- 提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收的越快,内存空间越大)
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认45%)
G1日志详解
[GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0015790 secs]//young -> 年轻代 Evacuation-> 复制存活对象//initial-mark 混合回收的阶段,这里是YGC混合老年代回收[Parallel Time: 1.5 ms, GC Workers: 1] //一个GC线程[GC Worker Start (ms): 92635.7][Ext Root Scanning (ms): 1.1][Update RS (ms): 0.0][Processed Buffers: 1][Scan RS (ms): 0.0][Code Root Scanning (ms): 0.0][Object Copy (ms): 0.1][Termination (ms): 0.0][Termination Attempts: 1][GC Worker Other (ms): 0.0][GC Worker Total (ms): 1.2][GC Worker End (ms): 92636.9][Code Root Fixup: 0.0 ms][Code Root Purge: 0.0 ms][Clear CT: 0.0 ms][Other: 0.1 ms][Choose CSet: 0.0 ms][Ref Proc: 0.0 ms][Ref Enq: 0.0 ms][Redirty Cards: 0.0 ms][Humongous Register: 0.0 ms][Humongous Reclaim: 0.0 ms][Free CSet: 0.0 ms][Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)][Times: user=0.00 sys=0.00, real=0.00 secs]//以下是混合回收其他阶段[GC concurrent-root-region-scan-start][GC concurrent-root-region-scan-end, 0.0000078 secs][GC concurrent-mark-start]//无法evacuation,进行FGC[Full GC (Allocation Failure) 18M->18M(20M), 0.0719656 secs][Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)], [Metaspace: 3876K->3876K(1056768K)] [Times: user=0.07 sys=0.00, real=0.07 secs]
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis 建议值,G1会尝试调整Young区的块数来达到这个值
- -XX:GCPauseIntervalMillis ?GC的间隔时间
- -XX:+G1HeapRegionSize 分区大小,建议逐渐增大该值,1 2 4 8 16 32。 随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长 ZGC做了改进(动态区块大小)
- G1NewSizePercent 新生代最小比例,默认为5%
- G1MaxNewSizePercent 新生代最大比例,默认为60%
- GCTimeRatio GC时间建议比例,G1会根据这个值调整堆空间
- ConcGCThreads 线程数量
- InitiatingHeapOccupancyPercent 启动G1的堆空间占用比例

若有收获,就点个赞吧
0 人点赞
