AKF
单节点存在问题
1、 单点故障
2、容量有限
3、压力
X轴:全量镜像
Y轴:按业务、功能拆分
Z轴:优先级、逻辑再拆分。如1-1000放一个redis,1001-10000放第二个redis
主从复制

命令方式设置主从
5之前:SLAVEOF
5之后:REPLICAOF
6380> REPLICAOF 127.0.0.1 6379 // 追随6379
如果6380挂了,重启的时候要直接追随
6380> REPLICAOF 127.0.0.1 6379 --replicaof 127.0.0.1 6379 // 会增量添加master的数据6380> REPLICAOF no one // 取消追随
replica-serve-stale-data yes主从同步时,是否同步完才能获取数据replica-read-only yes 从是否只读repl-diskless-sync no yes直接通过网络传备份数据,no是先同步到磁盘,再通过网络传输repl-backlog-size 1mbmin-replicas-to-writemin-replicas-max-lag
高可用、哨兵
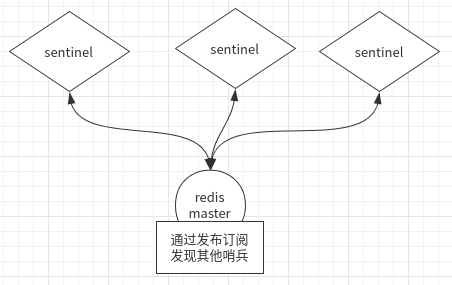
sharding 分片(解决容量问题)
数据能分类,交集不多

数据没办法划分拆解
hash+取模 modula

random 随机 (消息队列形式)

kemata一致性哈希(或者一系列映射算法)
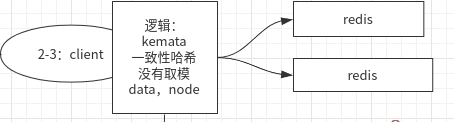
一个节点可以算多个hash,分布多个节点,解决数据倾斜问题

优点:
加节点,的确可以分担其他节点的压力,不会造成全局洗牌
###
缺点:
新增节点造成一小部分数据不能命中
1,问题,击穿,压到mysql
2,方案:没去取离我最近的2个物理节点
总结
代理
解决问题:redis的连接成本很高,对server端有压力

proxy: twemproxy 、predixy、cluster
cluster模型(无主模型)
在modula模型中,可以先预分区(如先模10而不是3),然后每个节点增加一个mapping,映射到对应的节点。当增加新的节点时,,模运算不变,只要同步原先节点的槽位到新节点就可以了,不用rehash。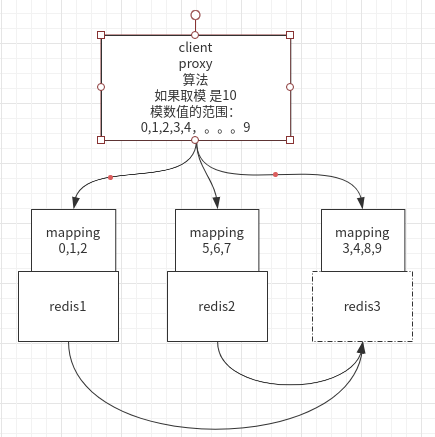
redis的cluster模型在此基础上
每个redis节点中存着其它节点与槽位的映射关系
流程为:
1、client先取redis2取数据,模运算算得对应槽位在redis3节点上
2、则返回redis3地址
3、client再去redis3取数据
问题:但是数据分治之后很难做聚合、事务等操作
Hash Tags
解铃还需系铃人。解决方法还是从分片技术的原理上找。
分片,就是一个hash的过程:对key做md5,sha1等hash算法,根据hash值分配到不同的机器上。
为了实现将key分到相同机器,就需要相同的hash值,即相同的key(改变hash算法也行,但不简单)。
但key相同是不现实的,因为key都有不同的用途。例如user:user1:ids保存用户的tweets ID,user:user1:tweets保存tweet的具体内容,两个key不可能同名。
仔细观察user:user1:ids和user:user1:tweets,两个key其实有相同的地方,即user1。能不能拿这一部分去计算hash呢?
这就是 Hash Tag 。允许用key的部分字符串来计算hash。
当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。
假设hash算法为sha1。对user:{user1}:ids和user:{user1}:tweets,其hash值都等同于sha1(user1)。
Hash Tag 配置
Hash Tag是用于hash的部分字符串开始和结束的标记,例如”{}”、”$$”等。
配置时,只需更改hash_tag字段即可
beta:listen: 127.0.0.1:22122hash: fnv1a_64hash_tag: "{}"distribution: ketamaauto_eject_hosts: falsetimeout: 400redis: trueservers:- 127.0.0.1:6380:1 server1- 127.0.0.1:6381:1 server2- 127.0.0.1:6382:1 server3- 127.0.0.1:6383:1 server4

若有收获,就点个赞吧
0 人点赞
