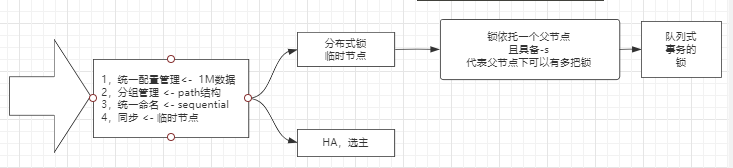
实现功能
- 统一配置管理<- 1M数据
- 分组管理<-paath结构(文件系统)
- 统一命名<-sequential
- 同步<-临时节点
设计目标
ZooKeeper很简单。ZooKeeper允许分布式进程通过共享的分层名称空间相互协调,该命名空间的组织方式类似于标准文件系统。名称空间由数据寄存器(在ZooKeeper看来,称为znode)组成,它们类似于文件和目录。与设计用于存储的典型文件系统不同,ZooKeeper数据保留在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。
ZooKeeper实施对高性能,高可用性,严格有序访问加以重视。ZooKeeper的性能方面意味着它可以在大型的分布式系统中使用。可靠性方面使它不会成为单点故障。严格的排序意味着可以在客户端上实现复杂的同步原语。
ZooKeeper已复制。像它协调的分布式进程一样,ZooKeeper本身也可以在称为集合的一组主机上进行复制。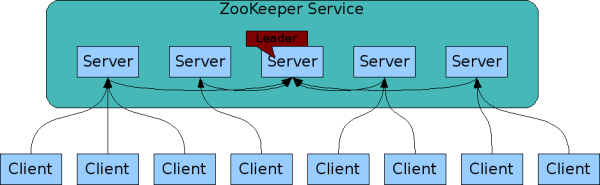
组成ZooKeeper服务的服务器都必须彼此了解。它们维护内存中的状态图像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务将可用。
客户端连接到单个ZooKeeper服务器。客户端维护一个TCP连接,通过该连接发送请求,获取响应,获取监视事件并发送心跳。如果与服务器的TCP连接断开,则客户端将连接到其他服务器。
ZooKeeper已订购。ZooKeeper用一个反映所有ZooKeeper事务顺序的数字标记每个更新。后续操作可以使用该命令来实现更高级别的抽象,例如同步原语。
ZooKeeper很快。在“读取为主”的工作负载中,它特别快。ZooKeeper应用程序可在数千台计算机上运行,并且在读取比写入更常见的情况下,其性能最佳,比率约为10:1。
它公开了一组简单的原语,分布式应用程序可以基于这些原语来实现用于同步,配置维护以及组和命名的更高级别的服务。
数据模型和分层名称空间
ZooKeeper提供的名称空间与标准文件系统的名称空间非常相似。名称是由斜杠(/)分隔的一系列路径元素。ZooKeeper命名空间中的每个节点均由路径标识。
ZooKeeper的层次命名空间
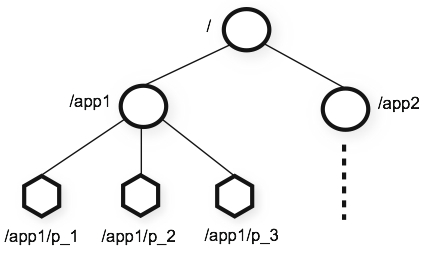
节点能存数据(1MB),但是不要把zk当数据库,zk的目的是减少网络带宽和时延
节点和临时节点
与标准文件系统不同,ZooKeeper命名空间中的每个节点都可以具有与其关联的数据以及子节点。就像拥有一个文件系统一样,该文件系统也允许文件成为目录。(ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点上的数据通常很小,在字节到千字节范围内。)我们使用术语znode来明确表示在谈论ZooKeeper数据节点。
Znodes维护一个统计信息结构,其中包括用于数据更改,ACL更改和时间戳的版本号,以允许进行缓存验证和协调更新。znode的数据每次更改时,版本号都会增加。例如,每当客户端检索数据时,它也会接收数据的版本。
原子地读取和写入存储在命名空间中每个znode上的数据。读取将获取与znode关联的所有数据字节,而写入将替换所有数据。每个节点都有一个访问控制列表(ACL),用于限制谁可以做什么。
ZooKeeper还具有短暂节点的概念。只要创建znode的会话处于活动状态,这些znode就存在。会话结束时,将删除znode。
client连接 zk会有一个session,session过期会做相应的处理
临时节点:生命周期和客户端会话绑定,一旦客户端会话失效,这个客户端创建的所有临时节点都会被移除。
序列节点
担保
ZooKeeper非常快速且非常简单。但是,由于其目标是作为构建更复杂的服务(例如同步)的基础,因此它提供了一组保证。这些是:
- 顺序一致性-来自客户端的更新将按照发送的顺序应用。(通过主从模型来保证)
- 原子性-更新成功或失败。没有部分结果。(client面对集群的原子性,不会用强一致性而是最终一致性(投票过半))
- 单个系统映像-无论客户端连接到哪个服务器,客户端都将看到相同的服务视图。也就是说,即使客户端故障转移到具有相同会话的其他服务器,客户端也永远不会看到系统的较旧视图。
- 可靠性(持久性)-应用更新后,此更新将一直持续到客户端覆盖更新为止。
- 及时性(最终一致性)-确保系统的客户视图在特定时间范围内是最新的。
节点数据类型
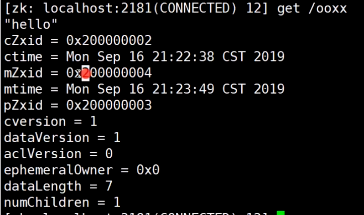
pZxid: 当前节点下最后一个创建节点的事务id
cZxid:节点创建时的zxid
ctime:节点创建时间
mZxid:节点最近一次更新时的zxid
mtime:节点最近一次更新的时间
cversion:子节点数据更新次数
dataVersion:本节点数据更新次数
aclVersion:节点ACL(授权信息)的更新次数
ephemeralOwner:如果该节点为临时节点,ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是临时节点,ephemeralOwner值为0
dataLength:节点数据长度,本例中为hello world的长度
numChildren:子节点个数主从
问题:当leader挂了,如何实现高可用
解决:当主挂掉之后,zk会进入无主模型,这时候是不能进行读写的(不可用状态),需不到200毫秒即可选出新的leader
初始化配置

3888用于选举leader,选举成功后,在2888中通信事务之类的
安装
准备 node01~node041,安装jdk,并设置javahome*, node01:2,下载zookeeper zookeeper.apache.org3,tar xf zookeeper.*.tar.gz4,mkdir /opt/mashibing5, mv zookeeper /opt/mashibing6,vi /etc/profileexport ZOOKEEPER_HOME=/opt/mashibing/zookeeper-3.4.6export PATH=$PATH:$ZOOKEEPER_HOME/bin7,cd zookeeper/conf8,cp zoo.sem*.cfg zoo.cfg9,vi zoo.cfgdataDir=server.1=node01:2888:388810, mkdir -p /var/mashibing/zk11,echo 1 > /var/mashibing/zk/myid12,cd /opt && scp -r ./mashibing/ node02:`pwd`13:node02~node04 创建 myid14:启动顺序 1,2,3,415:zkServer.sh start-foregroundzkCli.shhelpls /create /ooxx ""create -s /abc/aaacreate -e /ooxx/xxoocreate -s -e /ooxx/xoxoget /ooxxnetstat -natp | egrep '(2888|3888)'
问题
- 当client连接某一个节点,但是节点挂了,session会同步嘛
会,因为zk有一个统一视图,session也在其中,
原理知识
paxos
zab
watch
API:不怕写zk client
callback -> reactive 响应式编程,成分压榨OS、HW资源
案例
分布式配置
分布式锁
1,争抢锁,只有一个人能获得锁
2,获得锁的人出问题,临时节点(session)。
3,获得锁的人成功了。释放锁。
4,锁被释放、删除,别人怎么知道的?
4-1:主动轮询,心跳。。。弊端:延迟,压力
4-2:watch: 解决延迟问题。。 弊端:压力
4-3:sequence+watch:watch谁?watch前一个,最小的获得锁~!一旦,最小的释放了锁,成本:zk只给第二个发事件回调!!!!

若有收获,就点个赞吧
0 人点赞
