Netty需要学习的内容: 编解码器、TCP粘包/拆包及Netty如何解决、ByteBuf、Channel和Unsafe、ChannelPipeline和ChannelHandler、EventLoop和EventLoopGroup、Future等
netty3:
在3时,大多时候我们在堆上创建对象即堆缓冲区,当你要往Socket写内容的时候, 就需要做内存拷贝,拷贝到直接内存,然后交给Socket,做了太多的内存拷贝netty3也没有一个好的内存池,为什么这很重要?因为如果你想写一个高性能的网络程序,大多时候你会想使用本地内存(Native Memory),比如直接内存,创建直接内存时很耗费性能的,销毁直接内存也是耗费性能的。
为什么销毁直接内存也是耗费性能的?为什么要用内存池来解决这个问题?<br /> <br /> netty3没有针对linux进行优化 ,Java有一个对NIO接口的抽象,使得它在Windows Linux或OSX等<br /> 系统上都可以工作,但有时候你会有一些个性化的性能需求,或者只想要Linux上才支持的某些特性,<br /> Netty3没有提供这种功能,因为Netty3只使用了Java提供的NIO接口Netty4不再是这样。<br /> <br /> Netty3的线程模型也不太合理,为什么?在Netty3中每次想要从socket中读取数据 时,由于使用的是异步模式,所以我们有一个线程运行在一个EventLoop中,当一些Socket或文件描述符就绪时,我们从中读取数据,然后传递到Pipline,在Pipline里我们可以进行数据处理和转换等操作,当你写数据的时候,我们会从pipline再走一遍,直到走到socket,然后经过系统调用进入网络层,再进入内核空间 等等。所以这里的问题是:Inbound数据处理在是一个EventLoop里,一直是同一个线程,但Outbound上写数据却不再是这样,基本上Outbound的处理始终处于调用线程里,这意味着,非常难以理解到底是哪个线程在操作哪个数据和哪个流程,所以Netty4我们修改了它
Netty
现在产生更少的内存垃圾,这意味着垃圾回收器不必再工作的那么频繁,我们有一个针对Linux操作系统做了优化的传输层,我们是通过JNI来实现的。我们有一个高性能的Buffer Pool ,它基于Jemalloc论文,我们用Java重新实现了Jemalloc,用于直接内存,他还有一个非常好的线程模型,inbound和outbound都发生在同一个线程内,这样我们就不必再担心同步问题
Channel
它是对Soccket的抽象,你可以做一个写操作,数据会走到socket然后调用write系统操作来把数据发送出去,这里有 远端地址 和 本地地址 等概念。如果你使用TCP Channel就详单与一个连接,每个Channel会对应一个ChannelPipine,ChannelPipine是一个包含了不同ChannelHandler的双向链表,ChannelHandler可以处理Inbound和outbound事件。什么意思呢,比如说在Inbound里每次读取一些数据,一个新的连接被接受,类似这样的事件,当它发生时,我们会从pipliine的头部开始,经过每个Channel Handler, 我们可以在Channel Handler对事件做一些处理,比如可以记录一下新连接的日志,也可以把Byte转换成POJO,基本上可以做任何事情,如果你做一个Outbound操作,比如写操作,我们会从pipline的尾部开始,然后从尾部流向Channel的头部, 一旦到达这里,就会做一个系统调用, 这允许你做一个拦截器模式的实现, 使你可以在pipline里进行可重用的业务逻辑处理,我们在Netty里使用这种方式来进行协议编解码操作,我们得到Http编解码器其实是一个ChannelInboundHandler+ChannelOunboundHandler ,意味着一旦你想支持http协议,只需要把我们这两个Handler放入Pipline即可,同样对SMPT和STORM等协议也是一样得到,所有Byte到POJO对象的转换操作其实都在Pipline中完成,还有一些其它有趣的操作,比如可以计算连接数,关闭连接,统计信息等等,所有使用Netty的框架也是基于这个模型,比如Finagle基于它实现了链式过滤器,vert.x使用它来分配BufferHandler过BodyHandler等。它类似于UNIX的管道(Pipes) 但它是双向的,所以你可以把不同的命令串联起来,并对输出进行一些修改,然后在终端得到结果,你可以在Inbound和Outbound两个方向上做。
内存垃圾
我想谈一下内存垃圾回收器以及为什么它是一个问题,在Netty3中,每个网络事件都是一个POJO对象,这样看起来很简单,所以我们只有两类方法,对Inbound数据来说我们有UpstreamEvent或者HandleUpstreamEvent,所以我们只需要传递一个Pojo对象,做一些instanceOf检查,然后就知道这个是消息事件,这个是连接事件等等,Outbound也是这样,这个是写事件,这个是连接事件等等。这里的问题是,每次你做网络操作时,都要创建一个POJO对象,更不要说还有数据转换等操作了,如果你要处理非常多的并发连接,这样感觉非常的笨重,更糟糕的是,这也妨碍了JVM进行JIT优化,因为你总是调用同一个方法来处理不同的POJO,做各种instanceOf检查,这些对象可能有着复杂的结构,这是很不友好的。为了解决这个问题,我们引入了一个非常轻量级的对象池,我不建议大家这么做,除非真的需要,不要把所有对象都池化。但我们在Netty里有很多一直被复用得到对象,这些对象被限制在同一个线程里使用,比如我们有一个编解码器,我们想要把Byte转换为不同的对象,然后放到List里,我们不需要每次都创建一个新的List,因为它的生命周期是非常受限的,我们只需要它缓存起来,然后再次重用它,之前我们在Netty3中进行Pojo操作所调用的方法,现在被替换为直接的方法调用,每次从网络层读取到数据时,ChannelRead方法会被调用,然后是channelActive方法,在每次新连接建立的时候被调用,我们有channelInactive方法当文件描述符被关闭时调用,这将会产生很大的影响,即使是节省了一小部分对象,一周前,在Netty的github上有一个非常有趣的issue,Twitter测试了下使用对象池性能的影响,使用这个小型对象池,和不使用它,而完全交给垃圾回收器来回收对象,结论显示,不适用对象的场景吃掉了四倍的CPU,但我们任然允许你关闭对象池,比如你说,我只想要垃圾回收器来帮我处理所有这些事情。

就像我之前说的我们使用JNI ,这里有些问题需使用JNI来解决。Java-NIO是对Socket的抽象,它是一个非常通用的方案,因为它需要在不同的平台上运行,需要兼容不同的线程模型,在Netty中我们不太关心这些,因为我们有一个定义的非常好的线程模型,我们知道哪个线程在一个socket上会调用什么,我们想要提供JDK目前没有的高级特性,我一会将展示一些特性,我们可以直接操作Buffer的指针,我们可以获取内存地址,然后进行传递,这样比传递对香港更轻量,还可以做其它有趣的事情,这些功能都已经内置好,目前它旨在Linux上可用,所以我们只在linux上有优化的扩展传输层,昨天我们开了一个新的PR,用来支持KQueue(类似epoll),如果你在windows平台,你任然可以使用NIO接口(这里指Netty提供的非JNI的NIO接口),API是一样的,这对用户是不可见的,只是我们提供的另一个依赖。 
这里,大家看左边的代码,从一种切换到另一种(指从非JNI的NIO切换到JNI的NIO),第一个使用的是NIO,可以看到有一个Bootstrap,所以它是Client端,启动客户端,设置Group,即eventLoopGroup,eventLoopGroup类似一个线程池,里面包含了很多线程,用来处理愤怒配给他们的不同的Channel,处理每个连接上的事件。你说你想要一个NIO的EventLoopGroup,然后你说你想使用NioSocketChannel.class作为参数,这是用来告诉Netty你要使用的是Java-Nio,如果你想要使用基于Linux的Native传输层,你只需要在保持代码基本不变的情况下,只修改两个类名就行了。如果你想使用Native传输层专用特性,事情就有点困难了,但当KQueue传输层搞定后,你就可以做到了。我们在native传输层到底提供了哪些有趣的功能呢?我不确定大家是否知道列出来的这些网络socket配置项的含义,所以我会给大家解释下它们的作用,以让大家理解为什么要使用它们。
SO_REUSEPORT:它跟SO_REUSEADDR完全不同,SO_REUSEPORT允许不同的线程和socket多次绑定到同一端口,为什么需要这么做呢,基本上我们会让操作系统内核来处理线程之间的负载均衡关系,如果你的程序需要接受狠毒偶的并发socket,只使用一个线程会成为性能瓶颈,因为这样你不能足够快的接受连接,然后你设置的SO_BACKLOG队列会被占据,队列变得过长,然后导致全部超时。比如你可以启动四个线程,然后让这斯恶线程在同一端口上处理不同的连接,另一个有趣的事情是,如果你想搞个DNS服务器,你可以在同一端口上用多个线程接受多个datagram包,这个场景实际上是Google首次开发出来的,大概在四年前merge到了(Linux)Kernel里,你可以靠它做很多有趣的事情,这很有趣,你甚至可以多次启动同一进程,并绑定到同一端口,这里唯一的问题是,Java需要多次保留堆空间,可能会工作的不太好。
TCP_CORK:允许你发送一个永久性的。。比如你有一个http,那么Buffer里会包含Headers和文件内容,你可以把两者在一个roud-trip里发送出去,非常高效,这非常好,尤其是当你提供文件服务时,
TCP_NOTSENT_LOWAT:通常在你使用Http2协议时非常有用。你可以告诉内核应该什么时候缓冲数据,以及缓冲到多少时,再Flush到网络层。
TCP_FASTOPEN:如果您对连接两端都拥有完全按的控制权,再连接第一次握手时你就可以开始发送数据,,如果结合SSL一起使用,你可以节省一次握手的Round-trip时间,但这只适用于你对两端拥有完全的控制权。
TCP_INFO:假设你的Client APP和Server App都运行在同一个数据中心,但你仍然想要使用SSL或者TLS,它可以减少网络延迟。TCP_INFO是一个在Linux里鲜为人知的配置,它允许你获取文件描述符的统计信息,我想你可以获取到你之前意想不到的信息,比如你可以获取到关于round-trip时间的信息,文件描述符所在网卡的错误信息等等。比如你可以写一个TCP客户端连接池,然后根据round-trip时间来选择要对话的主机。输入man TCP在man page里描述的很清楚,其实我们知识把Linux提供的功能展示了出来,所有在这里看到的信息都可以在man page里找到。
因为我们用了JNI,传递了内存地址过去,所以我们不需要生成太多的对象,我们能做到这些是因为它是被隔离起来的,所有这些对终端用户都是不可见的,因为JVM很容易被搞崩溃,如果你对内存地址做了错误的操作,特别是JNI
Buffers
ByteBuffer的问题是接口很不友好,因为你只有一个Index地址,如果你想读取一个刚刚填充好的buffer,你需要先flip一下,以把index地址重新设置到0的位置,然后你才能开始读取,这个操作很容易被忘记,所以你每次调试一个ByteBuffer程序的时候,你好奇为什么没有任何数据被正确的写到网络层或socket上,因为你忘记了对Buffer进行flip操作,另一个关于ByteBuffer的是,它没有提供很多有用的工具方法,比如,当你写网络程序的时候,你需要便利一个Buffer中的所有Byte,在ByteBuffer里做这个操作是很昂贵的,有很多原因
① 首先每次你调用get方法前都会做一次边界检查,比如你i想访问某个地址方位内的i地址,如果做太多这样操作就很昂贵了,比如不便利一个含有一万个Byte的Buffer。
在Netty中我们有一套自己的Buffer实现,可以帮你处理上面的场景,比如我们有个叫做ForeachByte的东西,它允许你传入一个ByteProcessor,在返回false前一直循环,基本上,每次获取一个byte进来,当返回true时,继续循环,当返回false时结束,所以我们只需要一次边界检查。当我们引入这个的时候,我们之前的Http实现里一直不断调用getByte,但使用这个之后,提升了20%的性能,知识因为切换到了这种方式,因为我们需要遍历非常多的byte。在Netty中,我们的读和写有着不同的index,你不再需要flip操作,如果你写,那么写index会递增,如果你读,那么读index会递增,一旦两个index指向同一地址,你就不能再读取数据了,这样很合理,ByteBuffer本身你无法继承JDK里的ByteBuffer,因为它的构造方法时包内私有的,这样就有点头疼,因为如果你想要多个ByteBuffer组合在一起的时候,是不可能的,如果你想要把多个ByteBuffer组合起来,只能把多个ByteBuffer传递到一个ByteBuffer数组里,这就需要你自己来做遍历, 再Netty里我们提供了CompositeByteBuf 类,它允许你把多个BytetBuffer对象组合到一起,所以你时再同一个抽象层面上进行操作, 此外还提供了一些额外的辅助方法,比如你可以获取ByteBuffer的特定Index,等等。也可以再 一个Byte Buffer上新增一个。比如我现在想要把三个ByteBuf组合到一起,只需要组装一下它们,API保持不变,Netty里关于ByteBuf最好的事情是,它是记录引用数的什么意思呢?你需要释放它们,你要像写C一样来写Java,听起来有点吓人,让我来解释下为什么要这么做,先看Java做了什么,如果你想要往Socket里写数据,你需要现有一个处于非堆内存的Direct buffer,也就是Native memory ,某种意义上Native memory是需要被释放的,否则就会产生内存不足,Java想要给你一种不需要关心这些事情的错觉,它交给了垃圾回收器来管理,垃圾回收器再你堆内存不足的时候运行,但我们实在堆外创建内存,这意味着哪里可能永远不会进行垃圾回收或者回收的很晚,当然运气好的话,也可能会及时运行,所以我们无法保证能够及时对直接内存进行回收。接下来就真的吓人了,打开OpenJDK源码,看下创建和销毁直接内存部分的源码,它们再Java9中可能已经做了修改,如果你想要创建直接内存,你需要进入到一个静态同步方法里,因为它们需要追踪你创建了多少直接内存,因为你可以在命令行里指定最大直接内存的大小,一旦超过了设定的大小,就会抛出内存不足的异常或错误,但它是静态同步的,这意味着如果你有很多线程一起创建直接内存,这在编写网络程序时很常见,就会产生大量的阻塞,这很糟糕。然后我们看销毁部分,销毁部分也是静态同步的,这也很糟糕,如果你的内存不足了,你会进入到一个catch块里,然后做一个100毫秒的线程休眠,首先它会调用system.gc来告诉垃圾回收期该运行了,等待100毫秒后再重试创建操作, 这很糟糕,尤其是对于延迟敏感的程序,你可能会说,如果要写延迟敏感的程序,不应该使用Java语言,但现在Java已经够快了,但100毫秒的延迟再生产环境里仍然是很恐怖的,这也是我们做引用计数的原因。在Netty里创建一个bytebuf就会使计数器加1,当结束使用时,需要调用release方法,然后计数器变为0,你可以调用retain方法,就好像在C里做的一样,当计数器为0时,我们为你销毁它,对于Native memory来说,我们拥有cleaner的引用,你们你自己别使用这个,我们拥有cleaner的引用,调用clean方法,或者调用Java9里的run方法,然后会调用垃圾回收器里的销毁代码,这样也行得通,但问题让然在静态同步方法这里,所以仍然会有问题,在netty里我们对此有两种解决方案,
第一种是使用内存池,大概就是每次调用release方法时,引用计数器减到0,然后把它放回内存池等待重用,这样就不会进入到静态同步方法里了,但这样你仍然需要在内存池中保留它
第二种是当我们检测到unsafe可用时,我们可以自己创建内存空间,而不必进入到静态同步区里,因为这丫昂我们就可以自行释放内存了,这样做的缺点是,Netty不会遵守你在命令行里设置的直接内存限制,不过我们提供了不同的配置参数,这是一种妥协,因为正确的释放内存是很难的。
在Netty里提供了内存溢出检测器,具体怎么做的呢,我们有不同级别的溢出检测
简单级别:我们会在你所有创建内存的地方进行溢出检测,在每次创建和释放内存的地方做一个stack trace如果产生了溢出,我们会告诉你,你在这里进行了内存创建,请你检查下ByteBuf,然后小欧会它,这会给你一些先诉讼,但很多时候用处不大,
Advanced:
我们更多时候使用PhantomReference对象把它封装到PhantomReference里,把它放到ReferenceQueue里,然后对它进行poll操作,如果你在生成环境里看到这些,你需要开启Advanced模式,什么意思呢?Advanced模式会在每个buffer的创建和销毁上做一个stack trace ,这回拖慢点速度,但效果还行,如果还是不行,你可以用
激进的模式:激进模式会在buffer的每个动作上都进行 stack trace这样那个代价会很高,如果在生产系统这么干,会拖慢所有操作,别这么干
正确的做法是,Netty里,我们在每次CI构建的时候会运行一次泄露检测,如果检测到溢出,构建就会失败,这样就方便多了,你也可以在运行时这么做,比如写一个JMX放到生产环境里,在你觉得有问题时,进行泄露检测,这样对u定位泄漏点非常有帮助 ,我们默认会使用直接内存,Netty里所有的内存创建都默认时直接内存,你也可以创建堆内存。我们也有类似getUnsignedInt getUnsignedByte这样的方法,你就不需要自己做掩码计算了,还有很多不同的的工具方法供你使用。
Buffer Pooling
Twitter的Finagle框架也是基于Netty的,这是一个压测表,展示了创建和销毁内存得到纳秒耗时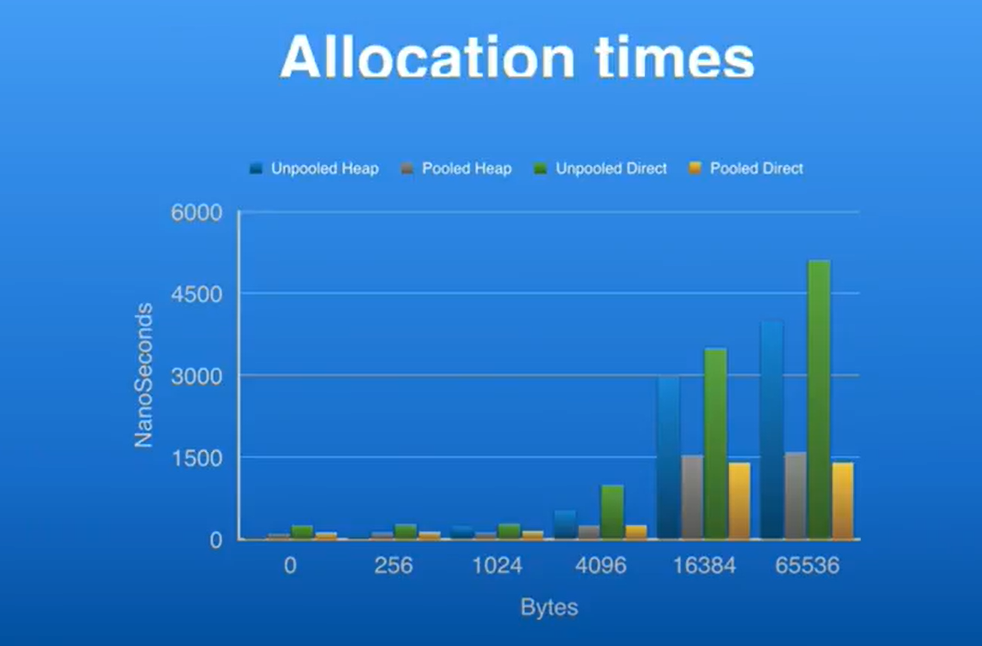
一直在同一个buffer上进行不同大小的创建和销毁操作,首先从0开始,为什么0也有耗时,因为我们对内存进行封装时会有耗时,对于不同的大小,我会挑选最大的来讲,因为越大对事件影响越明显,创建池化的直接内存比出啊关键非池化的直接内存要快三倍,这产生了很大的影响,如果你压测你自己的程序也会看到这个结果,你的检测器(profiler)会显示出来的这个结果,但即使时对于堆内存的创建,也有很大性能差别,这也是我们提供堆内存池的原因,你会问为什么会这样,它只是封装的byte数组而已,原因是这样的,JVM或Java的规范规定,每次创建byte数组的时候需要先做清零操作,这是有性能损耗的,所以如果你有一个完全自有的此程序,你可能并不需要这个, 你只想每次都使用同一片内存区域,及时你写C语言时,你也不需要每次精心gmemory set来重用byte数组,这里也是一样,你可以选择是否使用池或者两者都用,这都是可配置的,它是这么工作的
如果你们看过关于Jemalloc的论文,这个使用Java实现的Jemalloc3规范,它时这样工作的,有多个线程来创建内存,如果它们要创建内存,它们会进入到线程缓存里,在Java里就是ThreadLocal,如果大小合适的buffere已经存在,我们就直接拿来用,因为这样我们就不用再做同步操作了,因为都是再同一个线程里,如果里面没东西,我们就会进到一个叫做Arena的里面Arena类似于一个你创建的卫星内存区,会有很多Arena,可以通过配置来设定具体有多少个Arena,再Netty里默认有2倍内核的数量,每个线程随机选择Arena,绑定后不再变化,进入到Arena后试着进行创建,Arena自身 有多个不同大小的class,比如你想要创建32bytet的内存,你可以通过创建一个最大为64byte的class来实现,比如你想要创建256byte的内存,你可以通过创建一个最大为512byte的class来实现,类似这样,你可以配置不同大小的class,这样非常灵活,两个线程可能会操作同一个Arena,这时候就需要同步操作了,这也是为什么用到了ThreaLocal缓存的原因,如果想深入了解,可以看下Jemalloc的论文,作者叫Jason Evans ,它和Java没什么关系,它是FreeBSD默认的内存创建机制,工作的不错。
一个Channel被绑定到 IO-Thread上后绑定关系不再变化,这样的好处是所有的操作会一直处于同一个线程内,这样就省去了使用类似volatile等线程可见性机制,IO线程驱动了inbound handler和outbound handler里的事件,这让你不必再关心同步问题,因为编写多线程代码是很困难的,这里唯一需要小心的场景是,当你的channel handler 被多个channel共享的时候,因为不同的channel可能绑定在不同线程上,如果你的EventLoopGroup里只有一个线程,那就没问题,如果你有一个计算全部连接数的handler,它就需要却宝宝线程安全了,因为这个handler是被共享的,但如果你的handler只被一个channel使用,那么你就不需要关心同步问题了,它如何工作呢?如果你在Netty的非IO线程里进行方法调用,比如从外部调用,channelWrite方法,我们会检查线程是否是否是当前的EventLoop线程,如果不是我们会把它分配到EventLoop线程里,EventLoop线程其实就是Java里的Executor,对写和读来说都是一样的。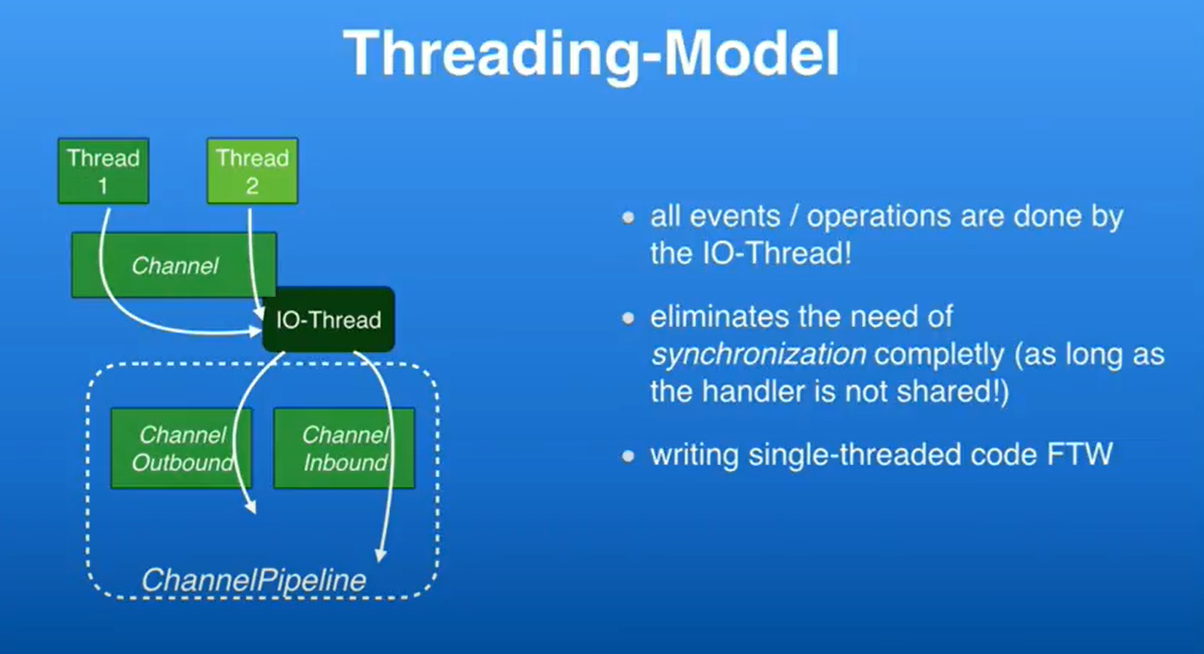
我们再Netty4里对写进行了修改,Netty3里每次调用ChannelWrite,最终都会导致socket write操作,这样也说通,但问题是人们每次再channelWrite时候通常数据量很小,比如当你有一个byte outstream的时候,你会调用多次write方法,我们思考如何改进它,因为再POSIX里,有种writev()操作,意思是允许在一次系统调用中同时包含了多个buffer,这样进行多次系统调用要轻量的多,因为系统调用是很昂贵的操作,首先因为你需要从Java进到C语言的JNI层里,这样代价很昂贵,然后C调用系统方法,从用户空间进到内核空间,也是很昂贵的。
我们在Netty4里是怎么做的呢?
我们把write和flush进行解耦,在Netty3中两者是同一个,在Netty4里,对于Outputstream每次调用write,它不会进入到socket,你需要调用flush,当你调用flush的时候,系统会保证outbound缓冲区里的所有数据都写入到socket中,这会让你可以做很多有趣的事情,这将会很有用,当你有一个支持pipline的协议的时候,如果你要写一个支持pipline的http服务,你现在可以做的是,每次channelRead方法被调用,意味着inbound数据进来,你调用channelWrite来进行回应,然后我们有一个channelReadComplete方法,表示这个channel里没有可读数据了,当这个方法被触发,你再调用channelFlush方法,所有之前被写入缓存的数据会在一个系统调用里完成发送,我们压测了一下,这种方法提升35%的性能,如果你写操作足够多的话,这取决于你写的评论,比如你做pipline有1000个pipline的请求,将会产生很大的影响,在这里的关键是,你可能没办法把所有的东西都写入,因为你可能耗尽了OS网络层的缓冲区,但我们会尽力去写,如果没法全部写入,我们就在selector epoll kQueue等里面循环,一旦状态变为可写,它就会重新唤醒,它知道需要写多少数据,因为当最后一次flush发生时,我们会写入剩余得到数据,所有的这些是非阻塞的,,这里唯一的缺点是,你需要小心再每次调用flush的时候,因为你可能ui吃掉很多内存,为解决这个问题,我们提供了背压(Backpressure)机制,我们称作channelwriteAbilityChange事件。每次channel从可写变为不可写或者相反,我们会发送一个事件,你可以检查到现在channel变为可写了,我将会继续写,现在变为不可写了,我会调用flush方法等等,所有这些取决于你再channel的那端,以及你想要缓存多少byte,因为channel会变为不可写,这非常灵活。你还可以这样做,当我的代理程序outbound channel变为不可写时,我会停止读取数据直到它重新变得可写,所以你可以对pipline里连在一起的两个socket建立背压机制,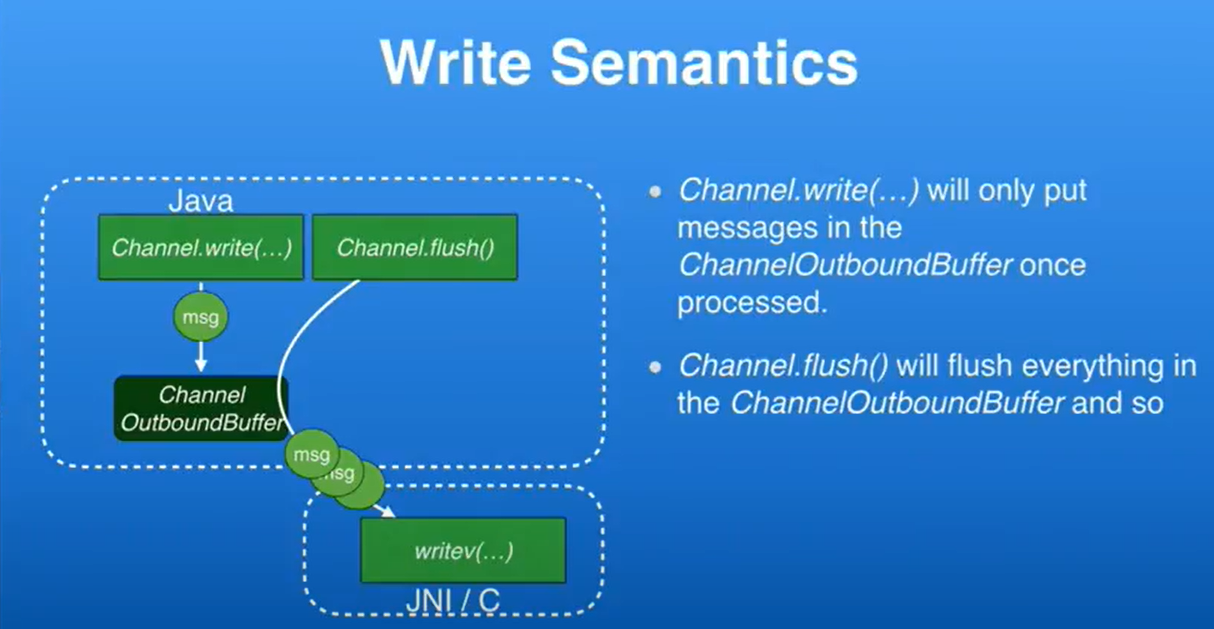
读操作
再netty3里每次有新数据到来,我们都会发送read事件,当我们只想读一次的时候,就不容易实现了,因为它再一个循环里一直运行着,你可以调用setReadable(false)方法,这样读取就停止了,但你仍然没办法控制调用的频率。在Netty4里,你可以调用setAutoRead(false)方法,这样你就可以在需要数据时才调用channelRead方法,这不保证你当时一定可以读取到数据,而是表明你准备好接受数据了,如果有可读取数据的话,你可以基于Netty搞一个Reactive Stream的机制,每次有请求读取对象时,就调用channelRead方法,在订阅者无法再接受苏剧时停止读取,这也是基于Netty搞得Reactive Stream实现的方式,Play框架也使用了这一机制,你也可以设置每次循环读取多少消息,因为如果你一直读取channel里的数据,如果你的远端却很慢,就会出问题,因为你在不同连接里共用了同一个线程,如果每次循环遍历buffer,直到有可读数据,你将无法终止。
RecvByteBufAllocator:它允许你预估需要使用的内存大小,然后给你一个相应的buffer,
IO线程
Netty4里提供了Netty3里没有的线程全局抽象,你可以让serve和client公用同一个线程,为何这样很有趣呢?举例来说,如果你搞了一个代理程序,你可以让accpted状态的inbound socker和outbound的远端主机socket使用同一个线程,这意味着你可以把数据从一个socket传递到另一个上,而且没有线程切换,顺便说下,在Native传输层,我们也支持Splicing,我们可以把socket和另一个socket连起来,而不必离开内核空间,这也非常棒,而且更轻量,但这样你就不能在 用户空间里对数据进行转换了,EventLoop本身继承自EventExecutor,EventExecutor又继承了ScheduleExecutorService,这意味着你可以在一个处理chhannel IO的线程里编排事件,这有什么用?比如如果做一个写操作,你可以安排一个事件,如果操作5秒内没有结束,就关闭连接,你不用更担心同步问题,因为是在同一个线程内,这里唯一的问题是,有些人会说,既然是Executor,那我用来做阻塞操作吧。别这么做,因为如果你阻塞了,就会阻塞线程内的所有其它操作,我们 是非阻塞编程,
使用阻塞API
有时候你需要在IO线程之外做一些操作,因为有时候你需要阻塞操作,比如你可能需要调用一些不支持非阻塞的api,如JDBC接口或者文件系统等,尤其在Java里有很多这样的API,因为Java当初不是为异步并发搞得,所以Java里有很多阻塞的Api,针对这个问题,我们提供了EventExecutor(Group),EventExecutor(Group)类似于EventLoop,每个进程内有多个线程,它仍然是一个类似线程池的东西,有趣的事情是,如果你建立一个pipline,里面有多个处理不同逻辑的handler,用来处理Byte或者转换为POJO等业务逻辑,你可以给它指定一个EventExecutor,这意味着,如果我想要在这个handler里处理一些事情,在这个eventExecutor里来执行,这意味着你可以把一些擦欧总从一个线程移到另一个上,比如,把EventLoop里的曹祖偶转移到EventExecutor上,甚至可以指定这个handler使用这个eventExecutor,哪个handler使用哪个eventExecutor,对另一个我又想要回到eventLoop线程,你可以做所有类似这样的事情,对EventLoop也是这样的,就像我刚才说的,它也继承自ScheduledExecutorService,所以你也可以分配给它,我们有不同的实现,默认的实现,我们为你保留数据顺序,因为如果你有一个http协议,即使你把数据转移到了线程池里处理,你仍然需要保留数据的顺序,用于响应,因为我们不想要把对第一个请求的响应发送给第二个请求,我们为你做了保序,如果你不关心顺序,我们也提供了UnOrderedEventExecutorGroup,这对UDP协议的datagram数据非常有用,因为你不关心顺序,比如cassandra在使用这个,Cassandra使用它的原因是,它们有自己的POJO对象,CQL消息之类的, 它们不关心顺序的问题,因为它们在不同的线程上进行多路复用,然后再把它们汇合到一起,因为它们有messageId,所以你可以使用Netty来完成这些工作,而不需要任何额外的工作

基于JNI的SSL引擎(JNI based SSL Engine)
大多数人仍然觉得,如果使用SSL,肯定不应该使用Java,因为它很慢。
如果你用的是JDK的实现,它确实很慢,虽然不像之前那么慢,这里展示的是最坏的情形,对于当前大多数cipher来说,如果你使用Java8 update 60以及以后的版本,它是比较快的,但它仍然是Netty实现的SSL引擎速度的一般,这里使用了wrk工具做压测,它是一款可以对http进行压测的工具,这是一个很基础的压测。Netty 的SSL引擎基本可达到15万的RPS,但是使用我们基于OpenSSL+JNI的Netty实现,基本可以达到50万的RPS。
我们使用的是OpenSSL或者leap SSL或boringSSL,它们API是相同的,也支持ALP和NPN,这意味着你不需要为了http2运行而进行任何hack,这对Java8来说是非常头疼的,因为你需要使用Boot class parser Hack,就像Jetty所支持的那样,我们的实现是不需要这些的。
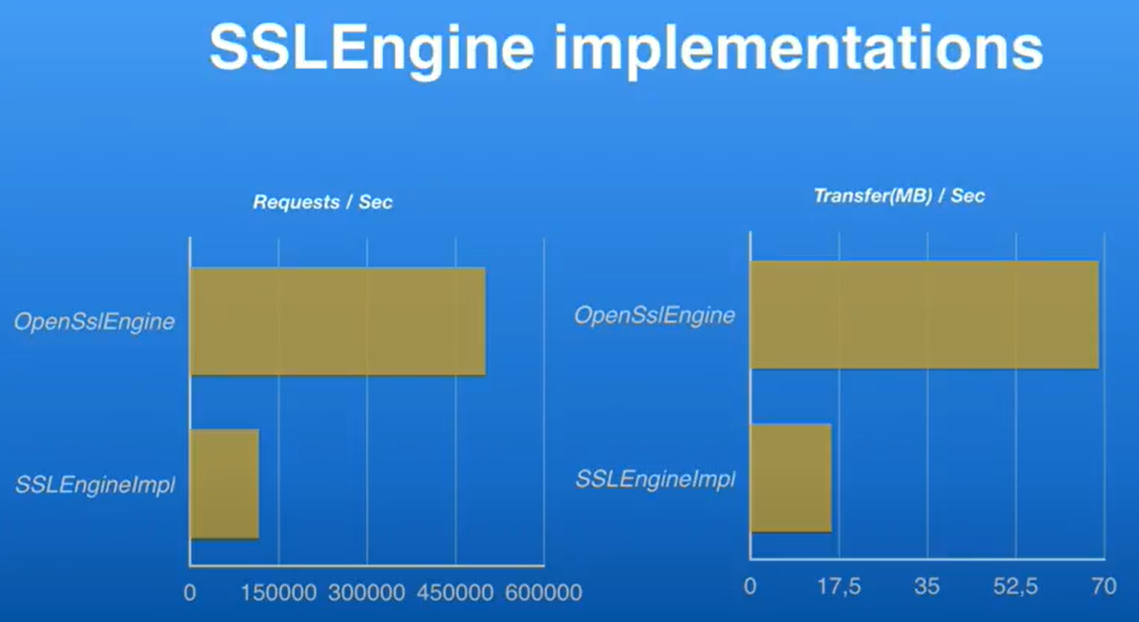
OpenSSL相比于JDK自带的,可以做到更少的GC,因为它没有像JDK实现那样创建很多额外的对象,如果你想要从一个切换到另一个,只需要该一行代码,只需要把
SslProvider.JDK改为SslProvider.OpenSsl
Netty会自动检测是否有OpenSSL的Jar包,Classpath里的module如果有就用它,没有就使用默认的JDK实现,API是相同的。OpenSSL引擎可以在Netty之外单独使用,它是基于Apache Tomcat Native的,Twitter公司Fork了代码,然后开源,并贡献到了Netty项目,
Netty And JVM
直接内存管理通过JVM的finalizer或cleaner来实现的,因为垃圾回收只有在你对空间消耗尽的时候才会进行。而你写网络编程的话,大部分时候你知道何时应该释放内存,因为如果已经把数据发送到了sockete,你会想要啊释放资源,你很清楚这时候可以释放内存了,这也是我们在Netty里做这个的原因,
内存布局(Memory Layout)
有时候JIT编译器会聪明过头了,大多数时候它很不错,因为它尽力为你获取最有的内存占用,所以JIT编译器会冲i性能布局你的class文件,因为存在内存空隙,为了避免浪费内存。但有时候你知道自己在干什么,因为可能会产生内存伪共享(False Sharing): 你有两个对象,两个内存地址,它们处于同一个CacheLine里,而你从不同的线程里访问它,因为不同的而线程在使用同一个CacheLine,它们之间使用Ping-Pong机制来更新值,你为你需要刷新内存里的值,这对性能的影响很大,而且很难观察到产生这个问题的原因,因为如果调试的话,需要进入到硬件系统里,查看类似计数器之类的东西,这对jJava语言来说是不可见的,为解决这个问题,在C语言里通过添加padding来解决,你会说这是一个结构体,我想要它按照我想要的方式来布局,然后GCC之类的编译器就不会触碰你的东西,不会重新布局它,如果你要在Java里做类似的事情,基本上你要做的是,你可能会想要使用一些字段来填充,但是JIT编译器让然可能会基于某些原因重新布局它们,比如为了节省内存。所以在Java里怎么做呢,类似JCTools做的那样,它是一种基于Queue的GC实现,在Netty中使用了它,如果你想使用Queue,它是一种多生产者-单消费者的模式,你应该使用类似JCTools的工具,而不是JDK实现,因为它很快,JDK的实现是多生产者-多消费者模式,用的时候需要确保安全性,如果你知道你要做什么,可以通过使用JCTools获得更快的速度。
JCTools是这样做的:为了防止JIT做愚蠢的事情,我把它们声明为public的,因为这样就不能优化它们了,这样也没起作用,我再把它们声明为public volatile,表示它们可能被多个线程访问,你不允许JIT做任何优化,这也不起作用,它在某种程度上会起作用,但是工作得到不是特别好,所以你会开始这么做,好吧,我自己来做padding,我会在前面放8个Long,因为8个Long表示64个字节,正好是一个CacheLine,这样有效果,但任然行不通,因为JIT仍然会重新布局class文件,最恶心的是,你创建一个CLass,在class里只做padding,然后继承这个class,然后再继承这个class,在其中再做一遍padding,因为你需要在前后都做padding,否则就又会产生内存为共享,然后再添加另一个东西,一直继续下去,所以你会得到20个相互继承的类,仅仅是为了做padding,这样确实可行,这种实现方式可能在以后的JDK版本里不再有效,但目前是有效的,所以这很恶心。但我会想要获得更大的控制权,如果我知道我在做什么,通过一些继承,我会改变对象布局,
JNI为了让JNI工作,有时候需要一些恶心的Hack,例如直接传递内存指针,否则会很耗费性能,最近有一个新的讨论,关于引入一个新标准来提升JNI的性能。如果你需要回调Java层的方法,JNI确实是非常昂贵的操作,尤其是从C层到Java层
Java NIO
产生了太多的垃圾,比如Selector Keyset等,它基于Hash Set,意味着每次访问它的时候,你需要创建一个新的iterator和新的HashSet, 这就产生了内存垃圾,我知道的所有关心性能的Java框架,基本都使用反射来注入它们自己的实现,用于减少内存垃圾,比如Aaron和Netty等框架。
ByteBuffer API对用户不够友好,对于连接重置,没有提供特定的异常事件,导致你不清楚是否是硬件的问题。java.util.concurrent.Future接口默认是阻塞的,我觉得它是违反Future的设计理念的,CompletionStage会是当前更好的设计,但是它仍然有些问题,因为它依然继承了Java的Future,

若有收获,就点个赞吧
0 人点赞
