global RE printing 全局搜索命令,并将搜索到的行打印出来
RE:Regular Expression 命令
grep是文本过滤工具,可以根据指定的命令,逐行扫描文件的内容,只要行中有满足命令的内容,则整行输出显示
[root@kedacom wyl]# alias grepalias grep='grep --color=auto'
grep命令语法
grep [option1, option2……] ‘命令’ file1,file2
options:
-v 显示不匹配的行
-i 不区分大小写
-o 只显示匹配的串
-A# 显示找到的行以及后面的行,其中#为数字表示后面多少行
-B# 显示找到的行以及前面的行,其中#为数字表示前面多少行
-C# 显示找到的行以及前后的行,其中#为数字表示前后多少行
-E 表示后面的表达式是扩展的命令
—color=auto’ 将匹配的字符串改变颜色显示
显示文件包含指定字符的行
#显示/proc/devices包含usb的行
[root@kedacom proc]# grep 'usb' /proc/devices
180 usb
189 usb_device
247 usbmon
-v 显示文件不包含指定字符的行
#显示/proc/devices不包含usb的行
[root@kedacom proc]# grep -v 'usb' /proc/devices
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
5 /dev/tty
5 /dev/console
5 /dev/ptmx
7 vcs
......
-o 显示匹配的字符
#显示/proc/devices匹配到的usb
[root@kedacom proc]# grep 'usb' -o /proc/devices
usb
usb
usb
-i 不区分大小写
#显示/proc/devices包含usb的行,不区分大小写
[root@kedacom proc]# grep 'usb' -i /proc/devices
180 usb
188 ttyUSB
189 usb_device
247 usbmon
-B# 匹配行及前#行
#显示/proc/devices包含usb的行及前1行
[root@kedacom proc]# grep 'usb' -B1 /proc/devices
162 raw
180 usb
188 ttyUSB
189 usb_device
--
246 hidraw
247 usbmon
#显示/proc/devices包含usb的行及前2行
[root@kedacom proc]# grep 'usb' -B2 /proc/devices
136 pts
162 raw
180 usb
188 ttyUSB
189 usb_device
--
245 ndctl
246 hidraw
247 usbmon
-A# 匹配行及后#行
#显示/proc/devices包含usb的行及后1行
[root@kedacom proc]# grep 'usb' -A1 /proc/devices
180 usb
188 ttyUSB
189 usb_device
195 nvidia-frontend
--
247 usbmon
248 bsg
-C# 匹配行及前后#行
#显示/proc/devices包含usb的行,以及前后1行
[root@kedacom proc]# grep 'usb' -C1 /proc/devices
162 raw
180 usb
188 ttyUSB
189 usb_device
195 nvidia-frontend
--
246 hidraw
247 usbmon
248 bsg
与管道技术结合
[root@kedacom proc]# ifconfig | grep 'inet'
inet 172.16.248.56 netmask 255.255.248.0 broadcast 172.16.255.255
inet 127.0.0.1 netmask 255.0.0.0
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
grep基本正则表达式
元字符
与文件名通配符类似,命令也有元字符
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
匹配任意单个字符
匹配指定范围内的单个字符
匹配指定范围外的单个字符
匹配次数
- 匹配前一个字符0次或多次

\? 匹配前一个字符0次或1次
{m,n} 匹配前一个字符最少m次,最多n次
{0, n} 匹配前一个字符,最多n次
{m} 匹配前一个字符,最少m次
与元字符组合

分组匹配
分组匹配连续内容
(字符串) 字符串反复出现
*分组匹配不连续内容,向后引用
假设users文件内容如下:
[root@kedacom wyl]# cat users
zhang,math=good,english=bad
li,math=good,english=good
wang,math=bad,english=good
guo,math=bad,english=bad,music=good,geography=good
xue,math=good,english=bad,music=good,geography=good
例1:查找到math、english都为good或bad的成绩
命令为:grep ‘.,math=(.),english=\1’ users 其中\1表示前面与前面math分组一致
例2:查找到math、english成绩一样,music、geography成绩一样
命令为:grep ‘.,math=(.),english=\1,music=(.*),geography=\2’ users
锚定符
\< 锚定词首
> 锚定词尾
\< > 锚定单词
^ 锚定行首
$ 锚定行尾
#t1文件内容如下
[root@kedacom wyl]# cat t1
root chroot rooter
this is root
there is chroot.
例1:查找单词以root开头的行
命令:grep ‘\
例2:查找单词以root结尾的行
命令:grep 'root\>‘ t1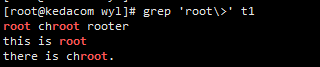
例3:查找单词为root
命令:grep ‘\
例5:查找行首为root
命令:grep ‘^root’ t1
例6:查找行尾为root
命令:grep ‘root$’ t1
假设,行首包含空格,如下数据
[root@kedacom wyl]# cat t1
root chroot rooter
this is root
there is chroot.
再使用grep ‘^root’ t1命令无法查找到,需要使用grep ‘^[[:space:]]*root’ t1
锚定行尾root,带有标点符号。
命令:grep ‘root[[:punct:]]\?$’ t1
字符类
POSIX定义了一些只能在正则表达式中使用的字符类
alnum 字母和数字
alpha 字母
blank 仅表示空格和制表符
cntrl 控制字符
digit 十进制数
graph 打印字符,不包含空格
lower 小写字母
print 打印字符,包含空格
punct 打印字符,不包含字母和数字
space 空白
upper 大写字母
xdigit 十六进制数
egrep扩展正则表达式
元字符
与基本正则表达式一致:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
匹配次数
- 匹配前一个字符0次或多次
? 匹配前一个字符0次或1次
+ 至少匹配1次
{m,n} 匹配前一个字符最少m次,最多n次
例1:echo “rooteeeeer” | egrep ‘ro+te{2,10}’
锚定符
\< 锚定词首
> 锚定词尾
\< > 锚定单词
^ 锚定行首
$ 锚定行尾
\b 锚定词首、锚定词尾
或者
| 表示或者
例1:echo ‘abcde abwde abc wde’ | egrep ‘abc|wde’ 表示匹配到有abc或者wde
例2:echo ‘abcde abwde abc wde’ | egrep ‘ab(c|w)de’ 表示匹配到abcde或者abwde
分组
分组不需要转移了
例1:echo ‘abchanhanhan100’ | egrep ‘abc(han){3}100’
例2:echo ‘a=10b=20c=10d=20’ | egrep ‘a=(..)b=(..)c=\1d=\2’ 向后引用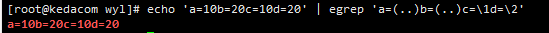
fgrep
不解析正则表达式,直接搜索文本
正则表达式需注意的两点
- 若需要将正则表达式中元字符表示字符本身的含义,需要使用转移字符\

不能使用echo ‘^root abc$’ | grep ‘^root abc$’
- 如果正则表达式中有命令替换,正则表达式只能使用弱引用””,如果正贼表达式中没有命令替换,则强引用’’与弱引用””都可使用


若有收获,就点个赞吧
0 人点赞
