注意:varchar定义的长度的单位是字符,哪怕是1个多字节字符也是1个字符,如中文和英文字母都被当作1个字符来对待。
sql语句
1、简单单表查询语句
select * from 表名;
select 属性 from 表名;
select 属性 as ‘xxx’ from 表名 设置别名xxx,as可以省略
2、单表的添加语句
insert 表名(属性)values(属性值);
3、单表的删除语句
delete from 表名 where 条件
deletefrom dept where deptno = 50;
4、单表的修改语句
update 表名 set xxx where 条件
update dept set dname = 'shshh',loc = 'nisod' where deptno = 50;
5、条件查询
条件查询需要用到where语句,where必须放到from语句表的后面
支持如下运算符
运算符 说明= 等于<>或!= 不等于< 小于<= 小于等于> 大于>= 大于等于between … and …. 两个值之间,等同于 >= and <=is null 为null(is not null 不为空)and 并且or 或者in 包含,相当于多个or(not in不在这个范围中)not not可以取非,主要用在is 或in中like like称为模糊查询,支持%或下划线匹配%匹配任意个字符下划线,一个下划线只匹配一个字符
5.1 <>操作符
查询薪水不等于5000的员工select empno, ename, sal from emp where sal <> 5000;select empno, ename, sal from emp where sal != 5000;
5.2 between … and …操作符
查询薪水为1600到3000的员工(第一种方式,采用>=和<=)select empno, ename, sal from emp where sal >= 1600 and sal <= 3000;select empno, ename, sal from emp where sal between 1600 and 3000;
5.3 is null
Null为空,但不是空串,为null可以设置这个字段不填值,如果查询为null的字段,采用is null
查询津贴为空的员工select * from emp where comm is null;
5.4 and
and表示并且的含义,表示所有的条件必须满足
工作岗位为MANAGER,薪水大于2500的员工select * from emp where job='MANAGER' and sal > 2500;
5.5 or
or,只要满足条件即可,相当于包含
查询出job为manager或者job为salesman的员工select * from emp where job='MANAGER' or job='SALESMAN';
5.6 表达式的优先级
查询薪水大于1800,并且部门代码为20或30的员工(错误的写法)select * from emp where sal > 1800 and deptno = 20 or deptno = 30;查询薪水大于1800,并且部门代码为20或30的(正确的写法)select * from emp where sal > 1800 and (deptno = 20 or deptno = 30);
5.7 in
in表示包含的意思,完全可以采用or来表示,采用in会更简洁一些
查询出job为manager或者job为salesman的员工select * from emp where job in ('manager','salesman');
5.8 not
查询出薪水不包含1600和薪水不包含3000的员工(第一种写法)select * from emp where sal <> 1600 and sal <> 3000;查询出薪水不包含1600和薪水不包含3000的员工(第二种写法)select * from emp where not (sal = 1600 or sal = 3000);查询出薪水不包含1600和薪水不包含3000的员工(第三种写法)select * from emp where sal not in (1600, 3000);
5.9 like
Like可以实现模糊查询,like支持%和下划线匹配
查询姓名以M开头所有的员工select * from emp where ename like 'M%';查询姓名以N结尾的所有的员工select * from emp where ename like '%N';查询姓名中包含O的所有的员工select * from emp where ename like '%O%';查询姓名中第二个字符为A的所有员工select * from emp where ename like '_A%';
Like 中的表达式必须放到单引号中|双引号中
6、数据排序
6.1单一字段排序 order by
排序采用order by子句,order by后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by默认采用升序,如果存在where子句那么order by必须放到where语句的后面**asc :升序
desc:降序
6.2多个字段排序
按照job和薪水倒序select * from emp order by job desc, sal desc;
6.3使用字段的位置来排序
按照薪水升序select * from emp order by 6;
不建议使用此种方式,采用数字含义不明确,程序不健壮
7、分组函数/聚合函数/多行处理函数
count 取得记录数
sum 求和
avg 取平均
max 取最大的数
min 取最小的数
注意:分组函数自动忽略空值,不需要手动的加where条件排除空值。
select count(*) from emp where xxx; 符合条件的所有记录总数。select count(comm) from emp; comm这个字段中不为空的元素总数。
注意:分组函数不能直接使用在where关键字后面。
mysql> select ename,sal from emp where sal > avg(sal);ERROR 1111 (HY000): Invalid use of group function正确写法:select ename,sal,from emp where sal > (select avg(sal) from emp)
注意:where 后面不能存在聚合函数
7.1 聚合函数(支持取别名)
count
取得所有的员工数select count(*) from emp;
7.2 sum
Sum可以取得某一个列的和,null会被忽略
取得薪水的合计select sum(sal) from emp;
7.3 avg
取得某一列的平均值
取得平均薪水select avg(sal) from emp;
7.4 max
取得某个一列的最大值
取得最高薪水select max(sal) from emp;取得最晚入职得员工select max(str_to_date (hiredate, '%Y-%m-%d')) from emp;
7.5 min
取得某个一列的最小值
取得最低薪水select min(sal) from emp;取得最早入职得员工(可以不使用str_to_date转换)select min(str_to_date(hiredate, '%Y-%m-%d')) from emp;
7.6 组合聚合函数
可以将这些聚合函数都放到select中一起使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;
如下:
mysql> select count(),sum(sal),avg(sal),max(sal),min(sal) from emp;
+—————+—————+——————-+—————+—————+
| count() | sum(sal) | avg(sal) | max(sal) | min(sal) |
+—————+—————+——————-+—————+—————+
| 14 | 29025.00 | 2073.214286 | 5000.00 | 800.00 |
+—————+—————+——————-+—————+—————+
8、分组查询
分组查询主要涉及到两个子句,分别是:group by和having
8.1、group by
:对字段进行分组
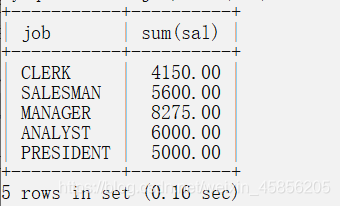
取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
select job, sum(sal) from emp group by job;
如果使用了order by,order by必须放到group by后面
按照工作岗位和部门编码分组,取得的工资合计
分组语句select job,deptno,sum(sal) from emp group by job,deptno;
在SQL语句中若有group by 语句,那么在select语句后面只能跟分组函数+参与分组的字段
8.2 having
如果想对分组数据再进行过滤需要使用having子句
取得每个岗位的平均工资大于2000
select job, avg(sal) from emp group by job having avg(sal) >2000;
分组函数的执行顺序:
根据条件查询数据
分组
采用having过滤,取得正确的数据
8.3、select语句总结
一个完整的select语句格式如下
select 字段from 表名where …….group by ……..having …….(就是为了过滤分组后的数据而存在的—不可以单独的出现)order by ……..
以上语句的执行顺序
1.执行from找到表2.首先执行where语句过滤原始数据3.执行group by进行分组4.执行having对分组数据进行操作5.执行select选出数据6.执行order by排序7.如有limit,limit在排序之后
原则:能在where中过滤的数据,尽量在where中过滤,效率较高。having的过滤是专门对分组之后的数据进行过滤的。
9、连接查询
9.1、连接查询:也可以叫跨表查询,需要关联多个表进行查询
显示每个员工信息,并显示所属的部门名称
SQL92语法select emp.ename, dept.dname from emp, dept where emp.deptno=dept.deptno;SQL99语法(join...on...)select emp.ename, dept.dname from emp,join dept on emp.deptno=dept.deptno;
也可以使用别名
select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno;
以上查询也称为 “内连接”,只查询相等的数据(连接条件相等的数据)
9.2、SQL99语法(join … on…)
(内连接)显示薪水大于2000的员工信息,并显示所属的部门名称
采用SQL92语法:
select e.ename, e.sal, d.dname from emp e, dept d where e.deptno=d.deptno and e.sal > 2000;
采用SQL99语法:
select e.ename, e.sal, d.dname from emp e join dept d on e.deptno=d.deptno where e.sal>2000;或select e.ename, e.sal, d.dname from emp e inner join dept d on e.deptno=d.deptno where e.sal>2000;在实际中一般不加inner关键字
Sql92语法和sql99语法的区别:99语法可以做到表的连接和查询条件分离,特别是多个表进行连接的时候,会比sql92更清晰
(外连接)显示员工信息,并显示所属的部门名称,如果某一个部门没有员工,那么该部门也必须显示出来
右连接:select e.ename, e.sal, d.dname from emp e right join dept d on e.deptno=d.deptno;左连接:select e.ename, e.sal, d.dname from dept d left join emp e on e.deptno=d.deptno;
以上两个查询效果相同
连接分类:
内连接
- 表1 inner join 表2 on 关联条件
- 做连接查询的时候一定要写上关联条件
- inner 可以省略
缺点:如果有字段是null,不会被筛选出来,会被过滤掉
**外连接
左外连接**
- 表1 left outer join 表2 on 关联条件
- 做连接查询的时候一定要写上关联条件
- outer 可以省略
- 左连接查询,左表的信息全展示,右表只展示符合条件的信息id,不足的地方记为NULL
右外连接
- 表1 right outer join 表2 on 关联条件
- 做连接查询的时候一定要写上关联条件
- outer 可以省略
- 右连接查询,右表的信息全展示,左表只展示符合条件的信息id,不足的地方记为NULL
左连接和右连接也可以加入outer关键字,但一般不建议这种写法,如:
select e.ename, e.sal, d.dnamefrom emp eright outer join dept d on e.deptno=d.deptno;
select e.ename, e.sal, d.dnamefrom dept dleft outer join emp e on e.deptno=d.deptno;
左连接能完成的功能右连接一定可以完成
10、子查询
子查询就是嵌套的select语句,可以理解为子查询是一张表
10.1、在where语句中使用子查询,也就是在where语句中加入select语句
查询员工信息,查询哪些人是管理者,要求显示出其员工编号和员工姓名
实现思路:
1、首先取得管理者的编号,去除重复的
select distinct mgr from emp where mgr is not null;
//distinct 去除重复行
2、查询员工编号包含管理者编号的
select empno, ename from emp where empno in(select mgr from emp where mgr is not null);
查询哪些人的薪水高于员工的平均薪水,需要显示员工编号,员工姓名,薪水
实现思路
1、取得平均薪水
select avg(sal) from emp;
2、取得大于平均薪水的员工
select empno, ename, sal from emp where sal > (select avg(sal) from emp);
10.2、在from语句中使用子查询,可以将该子查询看做一张表
查询员工信息,查询哪些人是管理者,要求显示出其员工编号和员工姓名
首先取得管理者的编号,去除重复的
select distinct mgr from emp where mgr is not null;
将以上查询作为一张表,放到from语句的后面
使用92语法:
select e.empno, e.ename from emp e,(select distinct mgr from emp where mgr is not null) m where e.empno=m.mgr;
使用99语法:
select e.empno, e.ename from emp esqjoin (select distinct mgr from emp where mgr is not null) m on e.empno=m.mgr;
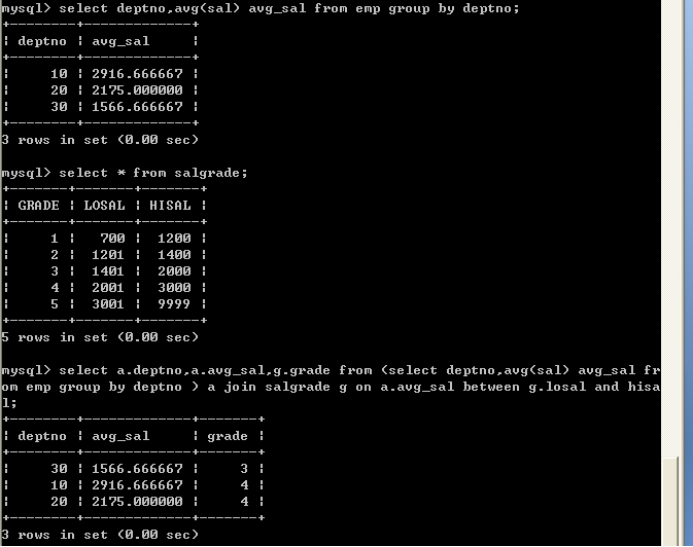
查询各个部门的平均薪水所属等级,需要显示部门编号,平均薪水,等级编号
实现思路
1、首先取得各个部门的平均薪水
select deptno, avg(sal) avg_sal from emp group by deptno;
2、将部门的平均薪水作为一张表与薪水等级表建立连接,取得等级
select * from salgrade;select a.deptno,a.avg_sal,g.gradefrom (select deptno,avg(sal) avg_sal from emp group by deptno ) a join salgrade gon a.avg_sal between g.losal and hisal;
10.3、在select语句中使用子查询
查询员工信息,并显示出员工所属的部门名称
第一种做法,将员工表和部门表连接
select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno;
第二种做法,在select语句中再次嵌套select语句完成部分名称的查询
select e.ename, (select d.dname from dept d where e.deptno=d.deptno) as dname from emp e;
11、分页 limit
limit 起始索引位置,分页单位(查询个数)
起始索引位置下标索引从0开始
起始索引位置与分页单位关系:起始索引位置 = (当前页-1)*分页单位
limit关键字永远出现在sql语句的最后面。
例子:
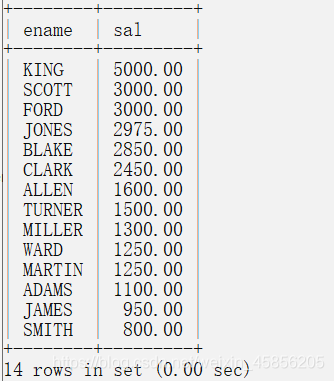
找出员工薪水排在前五的员工
select ename,sal from emp order by sal desc;
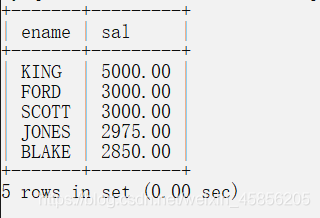
select ename,sal from emp order by sal desc limit 0,5;
找出员工薪水排在4-9名的员工
select ename,sal from emp order by sal desc limit 3,6;

若有收获,就点个赞吧
0 人点赞
