3.1 Standalone模式
Standalone指不依赖外部系统进行资源管理(比如yarn、k8s、mesos等)。
3.1.1 安装
(1) 下载
下载地址:https://flink.apache.org/zh/downloads.html
flink 1.7及之前,安装包分为“添加了Hadoop依赖”和“未添加Hadoop依赖”两种。添加了Hadoop依赖的,常用于集群部署时,且需要使用yarn进行资源管理的场景。此时需要注意依赖的Haddoop版本。未添加Hadoop依赖的,则适用于Standalone模式。
flink 1.8之后,安装包只提供“未添加Hadoop依赖”的版本。而Hadoop依赖则作为额外组件(jar包)单独下载(如下图所示),下载后放到flink解压目录下的lib文件夹下。
(2) 解压,进入解压后目录
(3) 修改配置文件
配置文件路径:
- 主配置文件:${FLINK_HOME}/conf/flink-conf.yaml
- master所在地址配置:${FLINK_HOME}/conf/masters
- slave所在地址配置:${FLINK_HOME}/conf/workers 或 slaves
flink-conf.yaml常用配置:
jobmanager.rpc.address:jobmanager所在机器的主机名。jobmanager.rpc.port:jobmanager监听的端口。jobmanager.memory.process.size:jobmanager可用的总内存大小。taskmanager.memory.process.size:每个taskmanager可用的总内存大小。taskmanager.numberOfTaskSlots:每个taskmanager同一时间可并行执行的任务数量。parallelism.default:对于提交给集群的一个程序来说,在没有指定并行度的情况下,默认的任务执行并行度。(4) 启动集群
./bin/start-cluster.sh
执行jps,确认进程是否启动成功。以下为单机启动时的截图。
可通过浏览器访问master所在IP的8081端口,打开Flink控制台,查询flink集群状态。
3.1.2 提交并执行Job
(1) Web UI提交
将编写好的Java程序打包为Jar文件。
在Flink控制台,左侧菜单,选择Subnit New Job,点击右侧的Add New按钮,选择Jar文件,执行上传。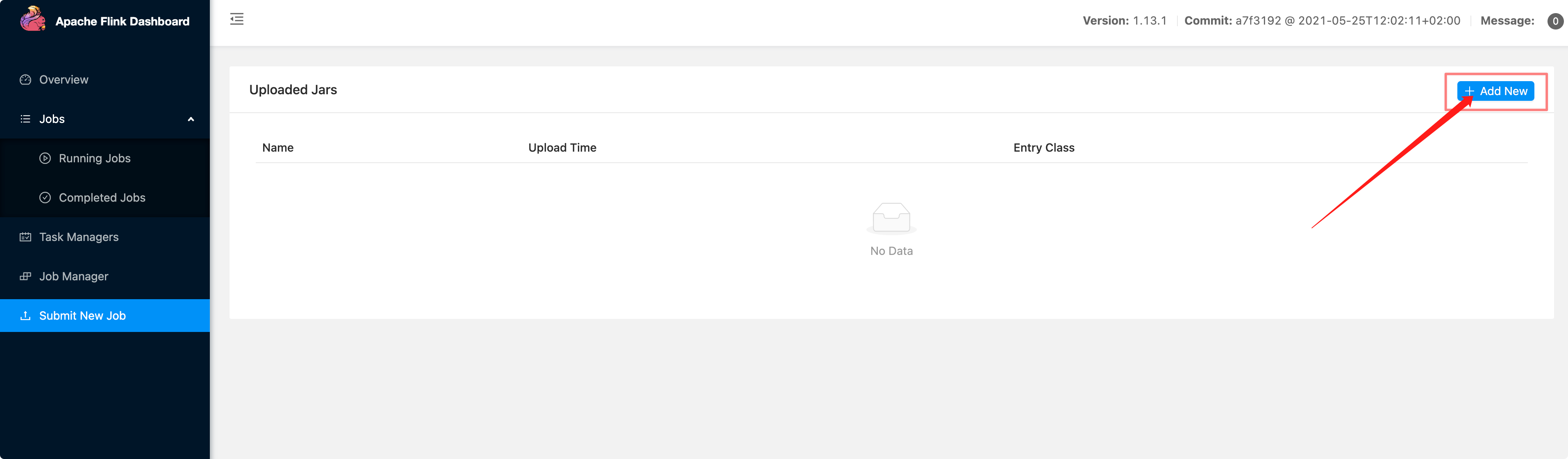
点击已上传的jar包,设置各种参数。
提交。
(2) 命令行提交
把jar包上传到服务器。
执行命令来提交任务:
./bin/flink run \-c <入口类> \-p <并行度> \<jar包路径> <启动参数>
其他命令:
./bin/flink list [-a] # 查看当前所有Job
./bin/flink cancel <JobID> # 取消任务
3.2 Yarn模式
以Yarn模式部署Flink任务时,要求Flink包含Haddop支持组件(自行下载jar包并放置于lib目录下),Hadoop环境需要版本在2.2以上,并且集群中安装有HDFS服务。
3.2.1 Flink on Yarn
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式。
(1) Session-Cluster模式
关键词:所有Job共享资源

Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下一个作业才能正常提交。所有作业共享Dispatcher和ResourceManager,共享资源。适合规模小执行时间短的作业。类似Standalone模式。
(2) Per-Job-Cluster模式
关键词:各个Job资源隔离,独自申请,独自使用。
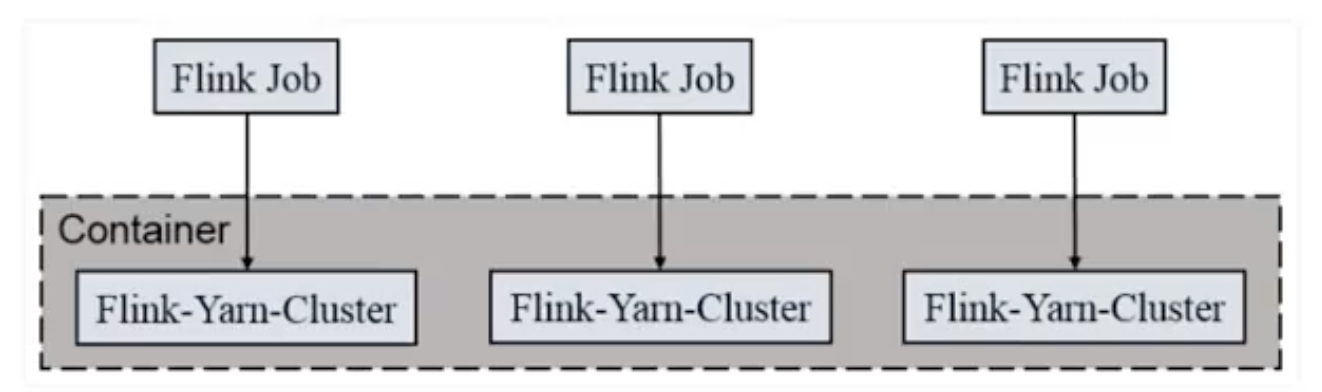
一个Job会对应一个集群,每提交一个作业,都会根据自身情况,单独向yarn申请资源,直到作业执行完成。一个作业的失败不会影响笑一个作业的正常提交和运行。各任务独享Dispatcher和ResourceManager,按需申请资源。适合规模大长时间运营的作业。
3.2.2 Session Cluster
3.2.3 Per Job Cluster
3.3 Kubernetes部署

若有收获,就点个赞吧
0 人点赞
