7.1 Flink中的时间语义

- Event Time:事件实际发生的时间
- Ingestion Time:数据进入Flink的时间
Processing Time:执行操作算子的本地系统时间,与机器相关
7.1.1 哪种时间语义更重要
不同的语义有不同的应用场合
- 我们往往更关心事件时间(Event Time)
- 事件时间需要作为事件数据的一部分,由数据源自行设置并传递给MQ;摄入时间和处理时间则不需要。
7.1 设置EventTime
不设置的话,默认是ProcessingTime(处理时间)。这意味着默认情况下时间窗口计时是以本地系统时间为依据。比如设置滚动窗口15S,则需要以本地系统时间为准,等待15S,不管具体接收到的事件的发生事件是什么时候。
如果想修改为Event Time(事件时间),首先要确保事件数据中有事件时间字段,然后:
- 设置全局时间特性。
- 为数据流设置时间字段和watermark。 ```java StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
---<a name="dIajo"></a># 7.3 水位线(watermark)<a name="QMuyo"></a>## 7.3.1 乱序数据的影响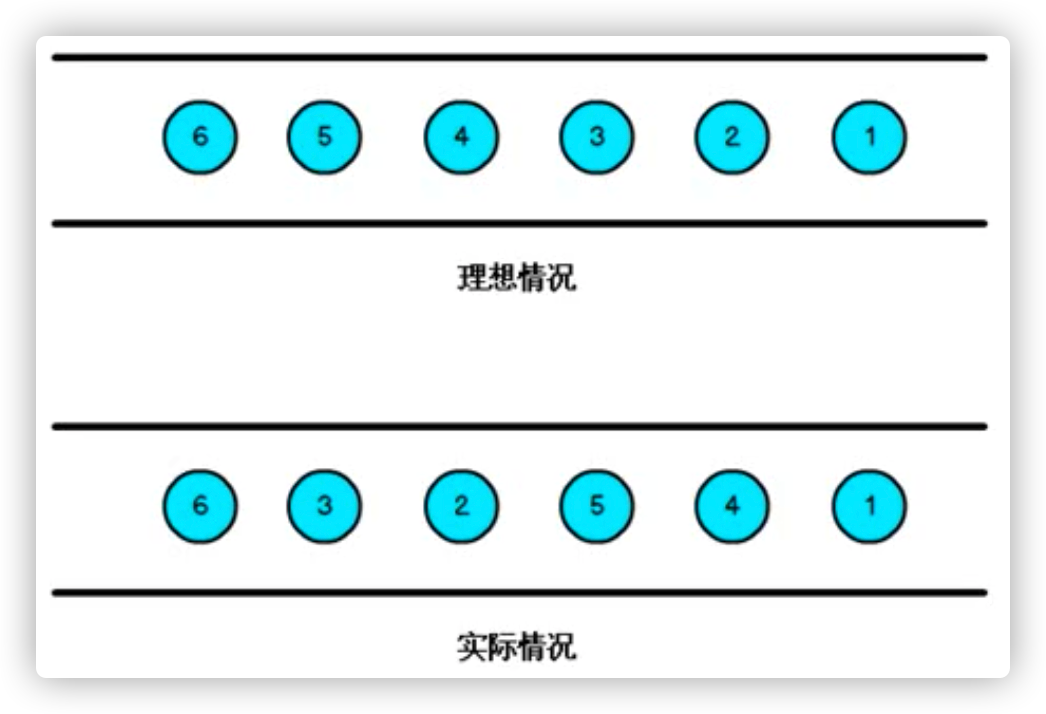- 当Flink以Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子。- 由于网络、分布式等原因,会导致乱序数据的产生。<a name="zIlzG"></a>## 7.3.2 水位线(watermark)- 怎样避免乱序数据带来的计算不正确?- 遇到一个时间戳达到了窗口关闭的时间,不应该like触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口。- watermark是一种衡量Event Time进展的机制,可以设定延迟触发。- watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。- 数据流中的watermark用于表示timestamp小于该watermark的数据都已经到达了,因此,window的执行也是由watermark触发的。- watermark用来让程序自己平衡延迟和结果的正确性。watermark越大,延迟越大,结果越正确。watermark越小,延迟越小,结果越不准确。> watermark、allowedLateness、sideOutputLateData是Flink处理乱序数据的三驾马车。首先,只有在和时间窗口打交道的情况下,才会有乱序的概念。另外,只有当时间语义是“事件时间”时(摄入时间也有可能,但是不常用),才可能乱序。而这三者的功能分别是:> - watermark:延迟窗口关闭、触发计算的时机。> - allowedLateness:在窗口已经关闭、计算已触发之后,在一定时间内,允许接收迟到数据到本窗口,并再次触发计算。> - sideOutputLateData:对于过于延迟的数据,则放入旁路数据流中,单独处理。>> 打个比方,一辆火车计划9:00发车,但买了火车票的乘客可能会迟到,不过大部分只迟到5分钟以内,少部分迟到15分钟,极个别可能迟到更长时间。火车会采用以下三种机制来解决问题:> - watermark:把站台的时钟调慢5分钟。这样火车会延迟发车5分钟,即实际9:05发车,在此之前到来的乘客都能上车。这样大部分迟到乘客可以上车。> - allowedLateness:发车,但不关车门。火车9:05发车,但是直到9:15都不关车门,此时到来的乘客,站台可以将他们“弹射”到火车上。> - sideOutputLateData:乘坐其他火车。如果乘客9:15后才来,站台会安排他们做另外一班火车,会有专人在目的地接待这些乘客。<a name="sxdpX"></a>## 7.3.3 watermark的特点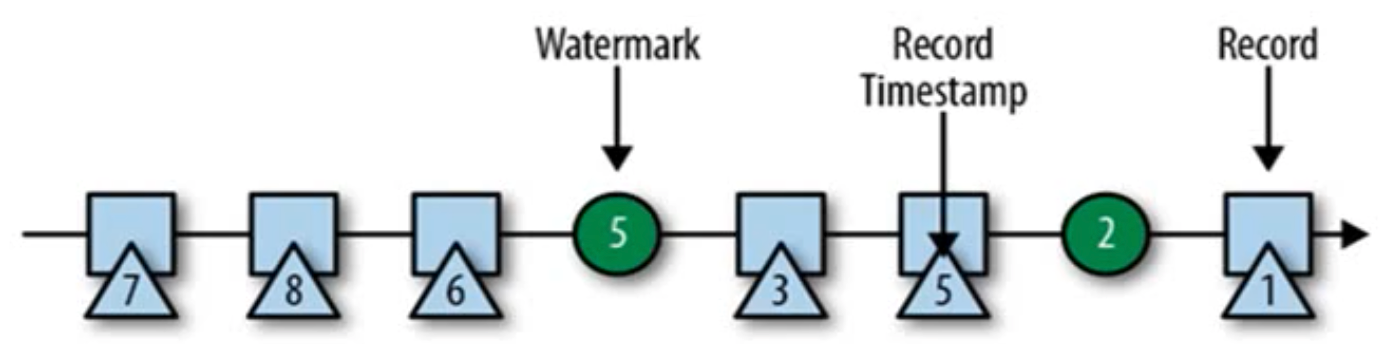```java// Flink中Watermark的定义,省略了不相关方法。public final class Watermark extends StreamElement {// 只有一个名为时间戳的字段private final long timestamp;}
- watermark是数据流中的一条特殊的数据记录,它只有一个名为时间戳的字段。
- watermark与数据的时间戳相关,即watermark基于数据的时间戳而产生。
- watermark必须单调递增,以确保任务的事件时间始终在向前推进,而不是在后退。
- watermark是一个代表时间推进的特殊事件,各算子会根据该事件来触发与事件相关的各种操作,典型的就是时间窗口操作。
7.4 watermark的传递、引入和设定
7.4.1 watermark的传递

- 一个子任务需要像下游广播自己的watermark,以告知下游自己认为在此之前的数据都到了。
一个子任务可能会不定时地从多个上游接收到watermark,此时会动态地选取已接收到的watermark中的最小值,作为自己的watermark,且在更新时广播给下游。
7.4.2 watermark的引入
watermark是在DataStream上调用
assignTimestampsAndWatermarks方法来设置的,需要同时设置时间戳提取方式和watermark生成方式。该方法有两种重载,接收不同类型的参数:AssignerWithPeriodicWatermarks接口:周期性地生成watermark,默认200ms一个周期。AssignerWithPunctuatedWatermarks接口:依据数据流中元素特征来触发生成watermark。
可以自行实现这两个接口,来自定义watermark的生成时机和值。不过Flink已经为我们封装好了一些实现类,可以 直接使用。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 获取Socket文本流
DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777);
// 转换成SensorReading
SingleOutputStreamOperator<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
})
// 指定时间戳和watermark
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.milliseconds(500) /* 指定最大乱序程度,用以计算watermark */) {
// 指定提取时间戳(ms)的方法
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000;
}
}
);
SingleOutputStreamOperator<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
})
// 如果确定数据不会乱序,则可以只指定时间戳
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<SensorReading>() {
@Override
public long extractAscendingTimestamp(SensorReading element) {
return element.getTimestamp() * 1000;
}
});
env.execute();
}
7.4.3 watermark的设定
- 在Flink中,watermark由应用程序开发人员生成,这通常需要对相对应的领域有一定了解(数据的量级、乱序程度,应用场景对延迟和正确性的要求)。
7.5 实战
7.5.1 窗口起始点和偏移量
Flink中,窗口是一个个的左闭右开的区间,这些窗口构成一个集合。第一个区间左边界是0,而所有窗口的右边边界都是窗口尺寸的整数倍。假设窗口尺寸是15s,那么默认窗口集合为:
- [0, 15)
- [15, 30)
- [30, 45)
- [45, 60)
- ……
窗口集合是在程序启动时就确定了的,运行时只需要判断数据属于哪个窗口。
如果窗口默认对齐0的行为不符合预期,则可以通过offset窗口来调整窗口的偏移量。典型的应用场景:用offset来处理时差问题。比如事件原始事件是UTC时间,而我们想计算按照北京时间计算的每天聚合值,则应该给-8小时的偏移量。

若有收获,就点个赞吧
0 人点赞
