4-1 慢查询日志
慢查询日志用于记录Redis中执行时间长于指定值的命令,并以先进先出的队列形式存储于内存中。
一个Redis请求的生命周期

两点说明:
- 慢查询发生在上图第3阶段:执行命令。
客户端超时不一定是慢查询导致的,但慢查询是客户端超时的一个可能因素。
慢查询日志的参数
slowlog-log-slower-than:慢查询的阈值(单位:微秒),默认10000,即10ms。如果设置为0,则会记录所有命令。如果小于0,则不会记录任何命令。
slowlog-max-len:慢查询日志的队列长度,默认128。
配置慢查询日志的方式
(1)修改配置文件,重启Redis
在redis.conf中,配置如下参数:
slowlog-log-slower-than 10000slowlog-max-len 128
(2)交互式命令方式配置
config set slowlog-max-len 500 config set slowlog-log-slower-than 5000慢查询日志相关命令
slowlog get [n]:查询慢查询日志。slowlog len:获取慢查询日志队列长度。-
慢查询日志运维经验
slowlog-log-slower-than不要设置过大。默认是10ms。推荐设置为1ms。因为通常都期望Redis能够支撑万级QPS,那么平均一条命令不应大于0.1ms,那么1ms已经很慢了。
- slowlog-max-len不要设置过小,至少应为1000以上。
- 应定期持久化慢查询日志。该功能可能需要第三方组件来实现。
4-2 pipeline
什么是流水线
pipeline就是“一次性批量执行多条命令”的功能。
对于Redis来说,执行命令的过程是非常快的,而网络传输才是制约Redis性能的关键瓶颈。pipeline的目的,就是去掉N条命令单独执行时的重复网络传输消耗。
在Jedis中使用pipeline
// 不使用pipeline,设置一万次。
try (Jedis jedis = new Jedis("47.107.149.75", 6382)) {
for (int i = 0; i < 10000; i++) {
jedis.hset("key:" + i, "field" + i, "value" + i);
}
}
// 使用pipeline,设置一万次。
stopwatch.start();
try (Jedis jedis = new Jedis("47.107.149.75", 6382)) {
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
pipeline.hset("key:" + i, "field" + i, "value" + i);
}
pipeline.sync();
}
pipeline与原生批量命令(m命令)的对比
原生批量命令是一条命令,执行是具有原子性的。
pipeline则是多条命令构成的一个包,在服务端执行时,一个pipeline包会拆分出多个pipeline子命令,分别执行。因此一个pipeline包整体来看没有原子性。
使用建议
- 注意一个pipeline携带的数据量,不应过大。
- pipeline每次只能作用在一个Redis节点上。
4-3 发布订阅
角色
- 发布者(publisher)
- 订阅者(subscriber)
- 频道(channel)

需要注意,Redis没有提供“消息堆积”的功能。即一个订阅者订阅一个频道后,没有办法收到这个频道之前已经发布的历史消息。
API
publish
publish channel message:向指定频道发布指定消息,返回订阅者数量。subscribe
subscribe channel [channel1, channel2,...]:订阅指定频道。unsubscribe
unsubscribe channel [channel1, channel2, ...]:取消订阅频道。其他API
PSUBSCRIBE pattern [pattern ...]:订阅所有频道发布的匹配指定模式的消息。PUNSUBSCRIBE [pattern [pattern ...]]:取消订阅所有频道发布的匹配指定模式的消息。pubsub channels:列出至少有一个订阅者的频道。pubsub numsub [channel...]:列出给定频道的订阅者数量。pubsub numpat:列出被订阅的模式的数量。相比于专门的消息队列,Redis的发布订阅模式没有重试机制,也不能缓存消息。
消息队列模式
消息队列模式与上面的发布订阅模式的不同之处在于,消息的消费是抢占式的,一条消息只能被一个消费者消费。Redis没有默认提供这种模式,只能通过list去模拟一个消息队列。
我们在使用时,需要考虑清楚,一条消息是需要所有订阅者消费,还是只能由一个订阅者消费。
4-4 Bitmap
什么是Bitmap(位图)?
Bitmap就是一个二进制位(bit)组成的数组,Redis可以直接操作各二进制位。Bitmap是在String基础类型上提供的功能扩展,因此一个Bitmap最大是512M。
API
setbit key offset value:设置指定offset位置上的二进制位,返回之前的值。value只能是0和1。offset取值范围[0,2^32-1]。offset前如果还没有值,则全部置为0。getbit key offset:获取指定offset上的二进制位。bitcount key [start end]:获取指定范围内值为1的个数。bitop op destkey key [key1, key2, ...]:对多个bitmap进行按为与(and)、或(or)、异或(xor)操作;对单个bitmap进行按位取反操作(not)。将操作结果保存到destkye中。bitpos key targetBit [start] [end]:计算位图指定范围(start到end,单位为字节,如果不指定就是获取全部)第一个值等于targetBit的位的偏移量。应用场景
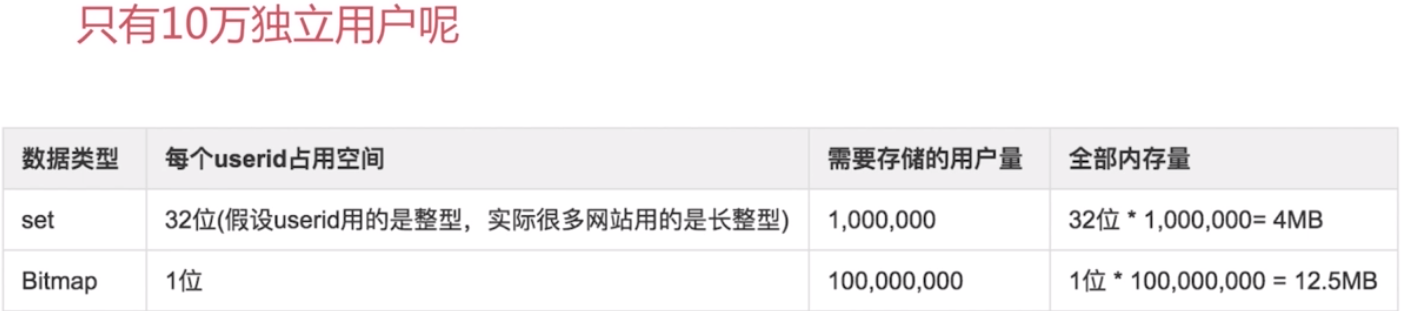
独立用户统计
在数据量极大时,使用Bitmap能够节约空间。
4-5 HyperLogLog
什么是HyperLogLog?
HyperLogLog则是一种算法,它提供了不精确的去重计数方案。在Redis中,可使用HyperLogLog用来做基数统计,其优点是,在输入元素的数量非常非常大时,计算基数所需的空间总是固定的,最多12K。HyperLogLog只用于计算基数数量,不会存储元素本身。需要注意的是,HyperLogLog的基数统计是估计值,有0.81%的误差。
什么是基数?就是不重复的元素。 比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数(不重复元素)个数为5。
在内部存储上,HyperLogLog依然使用字符串,而非一种全新的数据类型。
API
pfadd key element [element1, element2 ... ]:向HyperLogLog中添加元素。添加成功返回1,否则返回0.pfcount key [key ...]:计算指定HyperLogLog中的基数个数估计值。prmerge destkey sourcekey [sourcekey ...]:合并多个HyperLogLog,将结果存入指定的destkey。注意事项
HyperLogLog的基数统计是估计值,有0.81%的误差。应用场景是否允许这样的误差?
- HyperLogLog不会存储实际元素。
总结:用Redis进行独立用户数统计的方法
- Set:适用于数据量不大的场景。
- Bitmap:适用于数据量大的场景。
- HyperLogLog:适用于数据量大,要求存储空间极少,能够容忍微小误差,不需要获取元素本身的场景。
4-6 GEO
什么是GEO?

API
注意,Redis 3.2版本之后才支持GEO。
geoadd key longitude latitude member [longitude latitude member ...]:添加一个或多个地理位置信息。member是这个地理位置的标识。geopos key member [member1 ...]:获取指定member的地理位置信息。geodist key member1 member2 [unit]:获取指定member的距离。unit可取:- m(米)
- km(千米)
- mi(英里)
- ft(尺)
georadius...:获取指定位置范围内的地理位置信息集合。注意事项
Redis 3.2+才支持GEO。
- GEO底层使用Sorted Set(zset)来存储。删除一个member就是使用zrem key member来进行的。

若有收获,就点个赞吧
0 人点赞
