〇、线性一致性
Alice和Bob坐在同一个房间里,盯着各自的手机,关注着2016年NBA总决赛文字直播。在最后时刻,Alice刷新页面,告诉Bob骑士夺冠了。Bob难以置信地刷新了自己的手机,但他的请求被路由到一个落后的数据库上,手机显示比赛仍在进行。
在弱一致性的数据库系统中,同一时刻访问两个不同副本,可能会得到两个不同的答案,这令用户感到困惑。观看体育比赛的例子显得有些轻率,因为晚几秒钟看到结果不会造成什么实质性的伤害。然而对于某些业务场景,出现这样的问题是无法接受的:
- 一个电子邮箱地址只能被一个用户注册
- 银行账户余额永远不能为负数
- 两个人不能预定某航班的同一个座位
- 不能出售比仓库库存更多的物品数量
如果我们的分布式系统可以提供只有一个数据库的假象,事情就简单多了。这正是线性一致性(强一致性)背后的想法,也是本文将要讨论的主要问题,其基本要求是——让系统看起来好像只有一个数据库,并且所有操作都是原子发生的。
一、尝试实现线性一致
我们已经见到了几个线性一致性有用的例子,如何才能实现线性一致的系统?
最简单的做法是:真的只用一个数据库。但显然这种方案缺少容错性。
第二种可能的方法是:单主复制。将所有的写入操作都交给主库,用户只从主库或同步更新的从库读取数据。这看起来好像可以,但是依赖一个假设——所有节点都确定主库是谁。
单主复制的系统需要确保主库真的只有一个,而不是几个(脑裂)。我们可以让所有节点在启动时尝试获取锁,成功者成为主库,主库故障时重复此过程,但这个过程必须是线性一致的,即所有节点必须就哪个节点拥有锁达成一致——这将引出共识问题。
二、共识
共识(consensus)是分布式计算中最重要也是最基本的问题,它想要做的事情是:让所有节点就某事达成一致。尽管这听起来好像很简单,但即使在学术界,对共识的理解也用了几十年的时间才逐渐沉淀下来。
共识在很多场景下都非常有用,如果我们有办法做到“让所有节点就某事达成一致”,那么之前单主复制的脑裂的问题就解决了。另一种情况是,在跨多节点的分布式系统中,一个事务可能在某些节点上成功,但在其他节点上失败。如果想要维护事务的原子性,就必须让所有节点对事务的结果达成一致:要么全部中止/回滚,要么全部提交。这个问题叫做原子提交(atomic commit)。
原子提交也是共识的一种,它在所有节点都同意提交的情况下才能提交,如果有任意一个节点需要中止,则必须中止。而共识的一般意思是,尽管存在各种不同意见,但最终所有节点对采取谁的意见达成一致即可。
共识算法的实现与单主复制类似,但是它包含了防止脑裂的措施,可以安全地做到线性一致,例如Zookeeper就是这样工作的。ZooKeeper通过全序广播提供共识服务,进而帮助构建线性一致的系统。
三、全序广播
之前提到,线性一致的行为就好像只有单个数据库,且每个操作似乎都在某个时间点以原子性的方式生效。这隐含着一个保证:对任何两个数据库操作,无论发生时间有多紧凑,我们总是能判定先后。这个保证叫做全序。
如果程序只运行在单个CPU上,那么定义操作的全序是很容易的:CPU执行这些操作的顺序。在分布式系统中,如何让各节点对所有操作的顺序达成一致?答案是全序广播(也叫做原子广播),它通常被描述为在节点间交换消息的协议:如果每条消息代表一次数据库的写入,且每个数据库都以相同的顺序处理这些消息,那么所有数据库将相互保持一致。这包含了两个保证:
- 可靠交付:没有消息丢失。如果消息被传递到一个节点,它将被传递到所有节点。
- 全序交付:消息总以相同的顺序传递给每个节点。
全序广播并不难理解:传递消息就像在一个日志的末尾写入(仅追加日志),任何节点读取日志,都能看到相同的消息序列。并发传递的消息可能冲突,比如多个客户端同时注册同一个用户名,那就需要所有节点对于谁成功注册了此用户名这件事达成一致。所以全序广播相当于是所有节点对每一条消息进行共识(包括内容和顺序),在仅追加日志中记录共识的结果。
如果某节点网络中断,那么全序广播协议会不断重试,以保证在网络最终修复时,消息能及时送达,且必须按照正确的顺序送达(使用FIFO消息队列)。全序广播显然不等价于线性一致,线性一致的系统要求读取一定能看到最新的写入,而全序广播没有保证消息何时被送达。
四、使用全序广播实现线性一致
假如我们有了全序广播,就可以在此基础上构建线性一致的系统。先看下面这套操作:
在先前航班座号的例子中,让每个座号都有一个标志位,初值为0。在被预定时对此标志位进行CAS操作,如果先前标志位为0,将其设置为1,代表此座已被占领。如果多个用户试图同时预定相同的座位,也只会有一个CAS操作会成功。
然后我们把全序广播当作仅追加日志:
- 你广播一条消息“对座位12A尝试CAS”。
- 读日志,期待日志上出现你的消息。
- 接下来,如果这条消息真的出现了,你就成功抢到座了;如果第一条对12A座进行CAS的消息来自其他人,你就返回失败信息给用户。
这个过程实现了线性一致的存储,但它并不能保证读取也是线性一致的——如果你从与日志异步更新的数据库中读取数据,结果可能是陈旧的。为了让读取也是线性一致的,有下面几种做法:
- 同步日志的消息序号,等待直到该序号前的所有消息都传达到你(Zookeeper的sync()方法)
- 把读取操作也当作一条消息广播出去,当它出现在日志上时,在它之前的最近的写入就是最新值。
- 仅从含有最新日志的数据库中读取。
想象一下,座位就是锁,多个节点抢占锁决定谁是主库,这可以解决脑裂问题,单主复制的架构也就线性一致了。
五、先有鸡还是先有蛋
在全序广播协议中,如果要让所有节点看到一致的消息顺序,我们仍然需要一个领导者,以它的本地日志作为基准,然后广播到所有节点中——这不还是单主复制吗?
我们讨论过单主复制的脑裂的问题,结论是所有的节点都需要对谁是领导达成统一,否则就违背了线性一致性。选出唯一的领导需要共识算法,但如果这个共识实际上是全序广播,然后全序广播就像单主复制,而单主复制需要共识,所以…
这样看来,要选出一个领导,我们首先需要一个领导。要解决共识,我们首先需要共识。如何跳出这个先有鸡还是先有蛋的问题?
本文的剩余部分将从共识的特殊情况——原子提交开始,最终到达Zookeeper的原子广播(全序广播)协议。
六、两阶段提交
两阶段提交(two-phase commit)是一种跨多节点实现原子提交的算法,即确保所有节点提交或所有节点中止。它有点像西式婚礼仪式:司仪分别询问新娘和新郎是否要结婚,只有从双方都收到“我愿意”的答复后,司仪才能宣布这对情侣成为夫妻——事务提交了。如果新娘和新郎之一回复“我不愿意”,司仪就宣布婚礼中止。
这个过程中,司仪是协调者(也称为事务管理器),新郎新娘均为参与者。当应用准备提交时,协调者开始第一阶段——发送一个准备请求到每个节点,询问它们是否可以提交。然后协调者跟踪参与者的响应:
- 如果所有参与者都回答“是”,协调者就在第二阶段发出提交请求,让提交在所有节点上真正发生。
- 如果任意一个参与者回答了“否”或超时,那么协调者在第二阶段发出中止请求,所有节点回滚。
协调者可以是发起请求事务的进程,也可以是一个单独的进程。
七、为什么两阶段提交可以保证原子性?
两阶段提交的准备请求和提交请求当然也可能丢失,那为什么它可以保证原子性,而跨多节点的一阶段提交却不行?
为了说明这一点,就必须更详细地分解两阶段提交的过程:
- 当应用想要启动一个分布式事务时,它向协调者请求一个事务ID,并把此事务消息(包括ID)发送给所有参与者。
- 参与者尝试执行事务,无论成功与否都不提交。到目前为止,协调者以及任何参与者都可以单方面中止事务。
- 当应用准备提交时,就让协调者向所有参与者发送一个准备请求,然后等待回复。如果有任何参与者回复“否”或超时,协调者就向所有参与者发送针对该事务ID的中止请求。
- 在另一边,当参与者收到准备请求时,各自检查是否在任意情况下都确实可以提交事务。这是一个承诺:如果一个参与者回复了“可以提交”,那么将来宕机、电源故障、硬盘空间不足以及任何冲突都不能作为反悔的理由。换言之,参与者放弃单方面中止事务的权利,尽管此时还没有实际提交。
- 协调者收到所有准备请求的答复后,就对提交或中止作出决定。协调者必须先把这个决定写到硬盘上,这样哪怕它随后就崩溃,在恢复后也能知道自己之前做的决定。这一步被称为提交点。
- 提交点写入后,协调者把决定发送给所有参与者。如果发送失败,协调者必须永远保持重试,直到成功为止,没有回头路。哪怕有参与者突然崩溃,事务也将在其恢复后提交。
再来看一下两阶段提交的两个“不归路”时刻:
- 当参与者回复“可以提交”时,它承诺稍后肯定提交。
- 当协调者做出决定后,这一决定不可撤销。
八、协调者失效
参与者回复“可以提交”后,协调者突然故障怎么办?此时参与者已经不能单方面中止事务了,但是协调者永远不做最终决定。这种事务状态称为存疑或不确定的。
协调者失联,原则上参与者可以相互沟通,搞清楚每个节点是如何投票的,最后达成一致,但这不是两阶段提交协议的一部分。我们唯一的办法是等待协调者恢复,这也是为什么协调者在向参与者发送提交或中止的决定前,必须先将这个决定持久化。
九、三阶段提交
三阶段提交解决了两阶段提交的协调者失效问题,但不能保证原子性。它做出如下改动:
- 参与者也可以应对超时(两阶段提交只有协调者有超时机制,三阶段提交就都有了)。
- 把准备阶段再次一分为二。
第一阶段为准备阶段(CanCommit):协调者向参与者发送准备请求,参与者反馈“是”或“否”或超时。
协调者汇总回复,将结果发送给参与者:如果有任意参与者回复“否”或超时,就发送中止请求;否则进入预提交阶段。
第二阶段为预提交阶段(PreCommit):协调者发送预提交请求,参与者仍不提交,但是获知其他参与者已全部通过第一阶段,然后再次反馈“是”或“否”(最后的反悔机会);如果协调者发送的是中止请求或超时,参与者中止事务。
协调者汇总回复,将结果发送给参与者:如果有任意参与者回复“否”或超时,就发送中止请求;否则进入执行提交阶段。
第三阶段为执行提交阶段(DoCommit):协调者将最终决定写入硬盘,然后发送给参与者。如果发送执行提交请求,参与者就真正提交事务;如果发送中止请求,参与者就中止事务;如果协调者超时,参与者提交事务!能到达此阶段,说明第一阶段准备请求都已通过,即使此时协调者故障,参与者仍然相信可以提交——这也是为什么三阶段提交不能保证原子性。
抛开三阶段提交糟糕的性能,超时也不是一种可靠的故障检测机制,因为即使没有节点崩溃,请求也可能由于网络问题而超时。出于这个原因,两阶段提交仍然被广泛使用,尽管存在协调者失效的问题。
十、回到共识
如果明白了原子提交的原理,那么共识算法就变得容易理解。与原子提交相比,共识具有了更强的容错性:
- 采取大多数参与者的意见
- 领导者(即协调者)是选举出来的
- 在领导者故障后能够重新回到正常状态(通过重新选举)
如何在没有领导的情况下选举出一个领导(先有鸡还是先有蛋)?接下来的这段描述可能有些抽象,但是我们即将通过Zookeeper的原子广播协议(Zab)详细了解这个过程。
迄今为止所有的共识协议,都不能保证领导者是独一无二的。相反,它们做出了更弱的保证:通过定义一个全序且单调递增的ID:时代编号(epoch number),确保在每个时代中,领导者都是唯一的。 时代编号就像皇帝年号,编号增加就说明改朝换代了。如果两个领导出现冲突,那么谁的时代编号更大就听谁的。
Paxos其实是更早被提出的共识算法,但是理解起来相当困难。Zab借鉴了它,而且比Paxos算法更简单一些,我们从它开始看起。
十一、ZooKeeper Atomic Broadcast (Zab)
Zab协议是Zookeeper设计的支持崩溃恢复的原子广播协议。它使用单领导者(Leader)处理所有客户端的写入请求,然后将数据状态的变更以提议(proposal)的形式广播到所有的追随者(Follower)上去,只要半数以上的追随者反馈“是”,领导者就发送提交请求。
一旦领导者崩溃,或者领导者与过半追随者失去联系,那么就会进入崩溃恢复模式:领导者选举 + 数据恢复。选举算法不仅需要让领导者自己知道它已被选中,集群中的所有其他节点也要认可它,同时系统还能保持数据一致性。
首先来看领导者选举:
在Zab协议中,导致节点状态改变的每一个事件, 领导者都会为之分配一个全局单调递增的ID:zxid。由于需要保证全序,所有节点都必须按照事件的zxid由小到大依次处理。
zxid是一个64位的数字,其中低32位是一个计数器,针对每一次状态改变,领导者对该计数器加1。zxid的高32位则代表了时代编号,每当选举产生一个新的领导者,就会取出此领导者的本地日志,从其记录的最大zxid中解析得到时代编号,然后对其加1,作为新的时代编号,再将低32位数字归零,从0开始重新生成zxid。领导者死亡后,所有节点进入选举状态,将zxid最大的节点推选为新的领导者。任何时候,如果有多个节点均认为自己是领导者,那么谁的时代编号大就听谁的,这解决了脑裂问题。
选举出新的领导者之后,Zab协议还需要保证系统的数据一致性。确切地说,要做到以下两点:
- 领导者已经提交的Proposal必须被所有的追随者提交。
- 丢弃已经被提出但是还没有被提交的Proposal。
我们通过一个例子了解这个过程:
现在节点A是领导者,B、C、D、E是追随者。图中写明了每个节点此刻的本地日志。其中P1代表Prososal1,C1代表对Proposal1的Commit。此时领导者突然挂掉。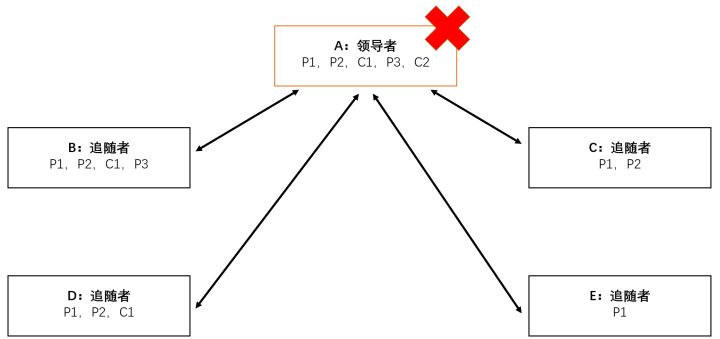
节点B、C、D、E需要选举新的领导者。在相互比较zxid之后,节点B当选新的领导者,时代编号加1。然后节点C,D,E将自己的本地日志发给新领导B,等候命令。
新领导者B最后的Commit消息是C1,那么P1、P2、C1三条消息在所有节点中必须一致(全序保证)。所以节点C收到来自节点B的消息C1,节点E收到来自B的消息P2,C1。
由于原先拥有消息P3的节点没有超过半数,所以领导者B将消息P3丢弃。同时,由于原先拥有消息P2的节点超过了半数(这是必然,从上帝视角看,老领导A已经有C2了,只不过没来得及发送就挂了),所以新领导者B决定将P2提交,即产生消息C2。如下图: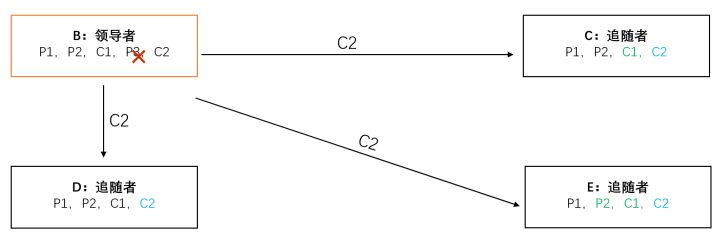
一段时间后节点A恢复,根据时代编号获知节点B是新领导者,那么它就作为追随者加入,并以节点B的日志为准同步数据。其实节点A早已提交了C2,而我们的算法也保证了C2一定会出现,保证了数据的一致性。
由于所有写操作都需要领导者处理,而读操作可通过任意节点完成,因此ZooKeeper的读性能远好于写性能,更适合读多写少的场景。这并不是大问题,因为我们很少直接把Zookeeper当作数据库使用。为保证性能,ZooKeeper会将数据放在内存中(数据必须是少量的,尽管它仍然会写入磁盘以保证持久性),所以应用数据不应该被放在这里!如果需要线性一致,单主复制的数据库架构依然是最好的选择,我们只需在用到共识的时候,把这部分工作“外包”给Zookeeper。
其实Zab协议的完整流程比这复杂得多,Zookeeper也不仅仅提供共识服务。本文仅叙述它的核心思想,隐去了很多细节。
十二、Paxos算法
Paxos算法没有了领导者和参与者,取而代之的是多个提议者(Proposer)和多个决策者(Acceptor),每个提议者都可以接受客户端的写请求,并通过Paxos算法解决客户端的并发写入冲突。与两阶段提交类似,Paxos也包含两个阶段,但理解起来困难许多。我们通过一个小故事来模拟整个过程。
有一个村子选村长,有多个村长候选人,然后村民进行投票,票数最多的当选。候选人可以贿赂村民,村民也不关心谁当村长,谁给的钱多就选谁。票选分为两天,第一天村民在小纸条上写下自己支持的候选人,第二天把纸条扔进投票箱,实名制一人一票。
为了方便叙述,假设有2个村长候选人(Proposer),3个村民(Acceptor)。
现在开始第一天:
候选人Ⅰ带着现金开始贿赂村民,给了村民①10块钱,村民①就在投票的小纸条上写上了候选人Ⅰ的名字,然后找到村民②,也做了同样的事情。最后找到村民③,但是村民③说,候选人Ⅱ给了他11块钱。候选人Ⅰ想,反正有2票也赢定了,就直接回家了。
如果此时候选人Ⅰ认为自己的支持者还没有超过半数,就会加大金额,把村民①~③全部重新贿赂一遍,直到他认为自己得到了多数派的支持为止。
候选人Ⅱ贿赂完村民③以后,又找到村民①和②,分别给他们11块钱。村民都是非常没有原则的,既然给的钱多,那就直接把小纸条涂改为候选人Ⅱ的名字。
至此第一天结束,开始第二天:
候选人去找村民催他们赶紧把纸条扔进投票箱。候选人Ⅰ找到村民①,发现自己居然被干掉了,这意味着他已经失去多数派支持。候选人Ⅰ赶紧去银行又取了一大笔钱,准备把村民①~③重新贿赂一遍,这次每人给20块钱。
候选人Ⅰ给了村民①20块钱,还没来得及见②和③的时候,候选人Ⅱ已经通知村民把纸条扔进投票箱了(当然这个要求被收了20块钱的村民①拒绝,但是②和③扔进去了)。等候选人Ⅰ找到村民②和③的时候,只能接受这个现实,承认候选人Ⅱ赢了,并把这个结果通知给村民①。
Paxos算法运行到最后,所有人都明确了新的村长是候选人Ⅱ,保证了数据的一致性。这有点像是一堆人同时执行两阶段提交,谁最先敲定就听谁的。这则小故事并不能完全概括Paxos算法,其完整流程相当复杂。在最后推荐一篇非常详细讲解Paxos算法的文章:Paxos算法原理与推导
参考:

若有收获,就点个赞吧
0 人点赞
