
1.1 Flink是什么
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
1.2 为什么要用Flink
- 流数据更真实地反映了我们的生活方式
- 传统数据架构是基于优先数据集的
- 我们的目标
- 低延迟
- 高吞吐
- 结果的准确性和良好的容错性
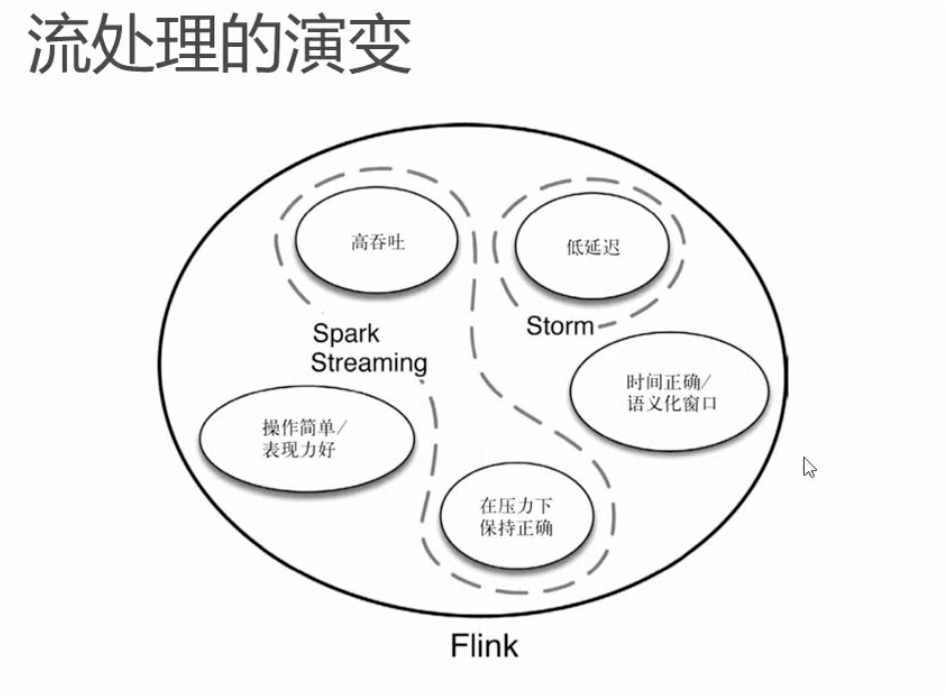
1.3 流处理的发展和演变


上面为“第一代流处理架构”。缺点是,在分布式架构下(即有多个Application Logic)时,数据处理的顺序无法保证。

演进历史:批处理架构 -> 流处理架构 -> Lambda架构(批处理+流处理)
Flink可以处理流数据或批数据
1.4 Flink的主要特点




参考:
1.5 Flink vs Spark Streaming

Spark出发点是“批”,把流处理认为是“微批”处理; Flink出发点是“流”,把批处理认为是“有界流”处理。 Spark Streaming通常有秒级延迟;Flink通常是毫秒级延迟。


若有收获,就点个赞吧
0 人点赞
