什么是 SQL?
SQL, 全称为Structured Query Language(结构化查询语言)。 要讲SQL就绕不开database(数据库), 平时所说的数据库,一般就是指的 Relational database(关系型数据库)
关系型数据库(Relational databases)
数据库由若干张表(Table)组成,这里说的数据Table很像Excel里的表; 正如Excel里的表格,Table也是由 行(rows)和列(columns)组成
一个Table存储一个类别的数据,每一行是一条数据,每一列是这种数据的一个属性; Table就像一个二维的表格,列(columns)是有限固定的,行(rows)是无限不固定的
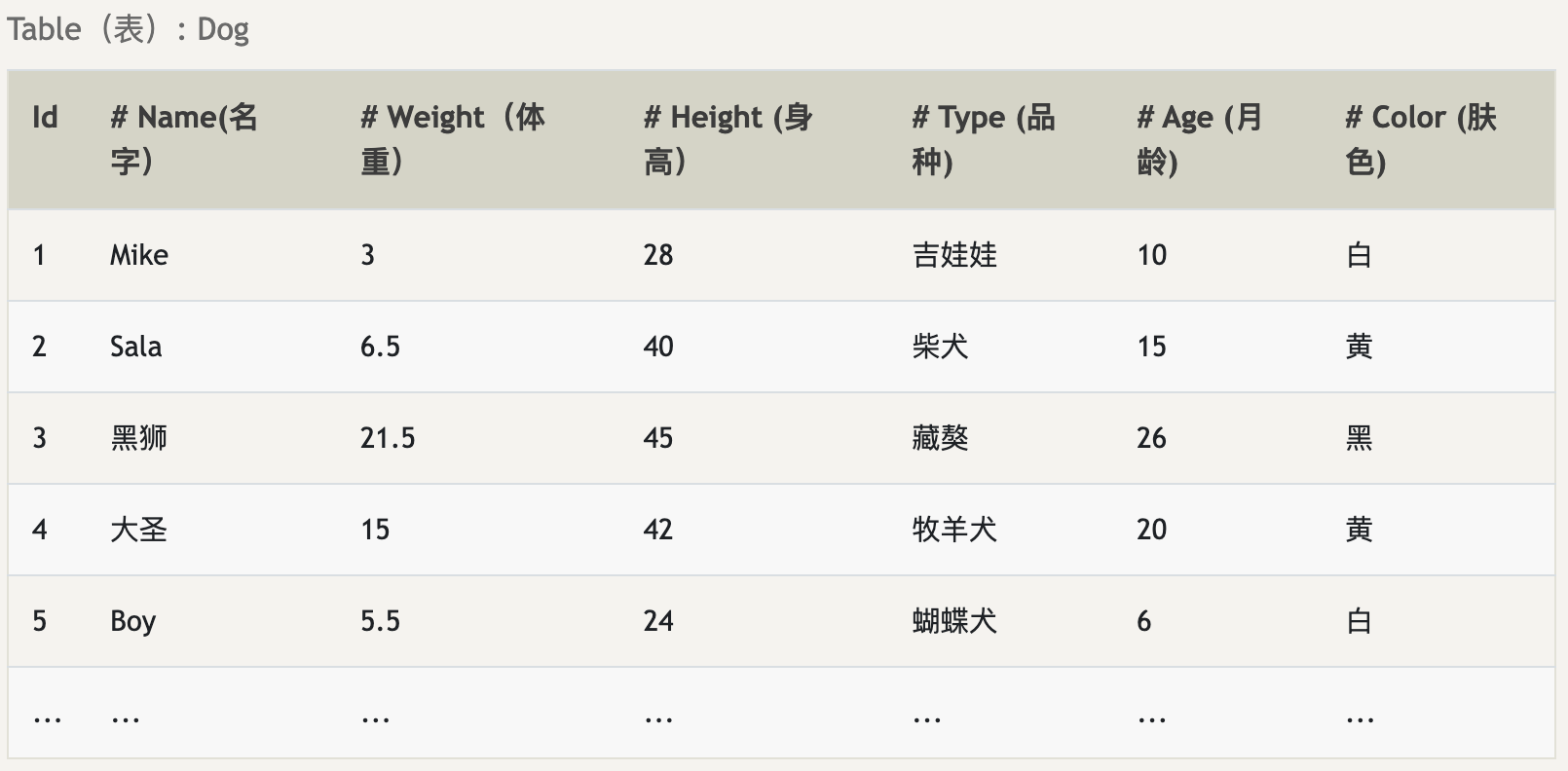
SELECT 查询 101
Select 查询某些属性列(specific columns)的语法
SELECT column(列名), another_column, …FROM mytable(表名);
Select 查询所有列
SELECT *FROM mytable(表名);
对结果查询
条件查询语法
SELECT column, another_column, …FROM mytableWHERE conditionAND/OR another_conditionAND/OR …;注:这里的 condition 都是描述属性列的
筛选数字属性列语法
| Operator(关键字) | Condition(意思) | SQL Example(例子) |
|---|---|---|
| =, !=, < <=, >, >= | Standard numerical operators 基础的 大于,等于等比较 | col_name != 4 |
| BETWEEN … AND … | Number is within range of two values (inclusive) 在两个数之间 | col_name BETWEEN 1.5 AND 10.5 |
| NOT BETWEEN … AND … | Number is not within range of two values (inclusive) 不在两个数之间 | col_name NOT BETWEEN 1 AND 10 |
| IN (…) | Number exists in a list 在一个列表 | col_name IN (2, 4, 6) |
| NOT IN (…) | Number does not exist in a list 不在一个列表 | col_name NOT IN (1, 3, 5) |
筛选字符串属性列语法
| Operator(操作符) | Condition(解释) | Example(例子) |
|---|---|---|
| = | Case sensitive exact string comparison (notice the single equals)完全等于 | col_name = “abc” |
| != or <> | Case sensitive exact string inequality comparison 不等于 | col_name != “abcd” |
| LIKE | Case insensitive exact string comparison 没有用通配符等价于 = | col_name LIKE “ABC” |
| NOT LIKE | Case insensitive exact string inequality comparison 没有用通配符等价于 != | col_name NOT LIKE “ABCD” |
| % | Used anywhere in a string to match a sequence of zero or more characters (only with LIKE or NOT LIKE) 通配符,代表匹配0个以上的字符 | col_name LIKE “%AT%” (matches “AT”, “ATTIC”, “CAT” or even “BATS”) “%AT%” 代表AT 前后可以有任意字符 |
| _ | Used anywhere in a string to match a single character (only with LIKE or NOT LIKE) 和% 相似,代表1个字符 | colname LIKE “AN“ (matches “AND”, but not “AN”) |
| IN (…) | String exists in a list 在列表 | col_name IN (“A”, “B”, “C”) |
| NOT IN (…) | String does not exist in a list 不在列表 | col_name NOT IN (“D”, “E”, “F”) |
特别注意:在字符串表达式中的字符串需要用引号 “ 包含,如果不用引号,SQL会认为是一个属性列的名字,如:col_name = color 表示 col_name和color两个属性一样的行 col_name = “color” 表示 col_name 属性为字符串 “color”的行
选取出唯一的结果的语法
SELECT DISTINCT column, another_column, …FROM mytableWHERE condition(s);
结果排序
SELECT column, another_column, …FROM mytableWHERE condition(s)ORDER BY column ASC/DESC;
ORDER BY col_name 这句话的意思就是让结果按照 col_name 列的具体值做 ASC升序 或 DESC 降序,对数字来说就是升序 1,2,3,… 或降序 … 3,2,1 . 对于文本列,升序和降序指的是按文本的字母序。
通过Limit选取部分结果
SELECT column, another_column, …FROM mytableWHERE condition(s)ORDER BY column ASC/DESCLIMIT num_limit OFFSET num_offset;
注意:limit 结果数量 offset 第几位(数组里,需要实际顺序 - 1)
用JOINs进行多表联合查询
用INNER JOIN 连接表的语法
SELECT column, another_table_column, …FROM mytable (主表)INNER JOIN another_table (要连接的表)ON mytable.id = another_table.id (想象一下刚才讲的主键连接,两个相同的连成1条)WHERE condition(s)ORDER BY column, … ASC/DESCLIMIT num_limit OFFSET num_offset;
在查询条件中处理 NULL
SELECT column, another_column, …FROM mytableWHERE column IS/IS NOT NULL --- 关键AND/OR another_conditionAND/OR …;
在查询中使用表达式
SELECT particle_speed / 2.0 AS half_particle_speed (对结果做了一个除2)FROM physics_dataWHERE ABS(particle_position) * 10.0 >500(条件要求这个属性绝对值乘以10大于500);
-- AS使用别名 --SELECT col_expression AS expr_description, …FROM mytable;
在查询中进行统计I
对全部结果数据做统计SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …FROM mytableWHERE constraint_expression;
常用统计函数
| Function | Description |
|---|---|
| COUNT(*), COUNT(column)** | 计数!COUNT(*) 统计数据行数,COUNT(column) 统计column非NULL的行数. |
| MIN(column) | 找column最小的一行. |
| MAX(column) | 找column最大的一行. |
| AVG(column) | 对column所有行取平均值. |
| SUM(column) | 对column所有行求和. |
分组统计
-- 用分组的方式统计 --SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …FROM mytableWHERE constraint_expressionGROUP BY column;
HAVING 语法(对分组之后的数据再做SELECT筛选)
-- 用HAVING进行筛选 --SELECT group_by_column, AGG_FUNC(column_expression) AS aggregate_result_alias, …FROM mytableWHERE conditionGROUP BY columnHAVING group_condition;
所有语法集中到一个句子中
-- 这才是完整的SELECT查询 --SELECT DISTINCT column, AGG_FUNC(column_or_expression), …FROM mytableJOIN another_tableON mytable.column = another_table.columnWHERE constraint_expressionGROUP BY columnHAVING constraint_expressionORDER BY column ASC/DESCLIMIT count OFFSET COUNT;

若有收获,就点个赞吧
0 人点赞
