到目前为止,我们已经探讨了不同机器学习的模型,但是它们各
自的训练算法在很大程度上还是一个黑匣子。回顾前几章里的部分案
例,你大概感到非常惊讶,在对系统内部一无所知的情况下,居然已
经实现了这么多:优化了一个回归系统,改进了一个数字图片分类
器,从零开始构建了一个垃圾邮件分类器,所有这些,你都不知道它
们实际是如何工作的。确实是这样,在许多情况下,你并不需要了解
实施细节。
但是,很好地理解系统如何工作也是非常有帮助的。针对你的任
务,它有助于快速定位到合适的模型、正确的训练算法,以及一套适
当的超参数。不仅如此,后期还能让你更高效地执行错误调试和错误
分析。最后还要强调一点,本章探讨的大部分主题对于理解、构建和
训练神经网络(本书第二部分)是至关重要的。
本章我们将从最简单的模型之一——线性回归模型,开始介绍两
种非常不同的训练模型的方法:
·通过“闭式”方程,直接计算出最拟合训练集的模型参数(也
就是使训练集上的成本函数最小化的模型参数)。
·使用迭代优化的方法,即梯度下降(GD),逐渐调整模型参数
直至训练集上的成本函数调至最低,最终趋同于第一种方法计算出来
的模型参数。我们还会研究几个梯度下降的变体,包括批量梯度下
降、小批量梯度下降以及随机梯度下降。等我们进入到第二部分神经
网络的学习时,会频繁地使用这几个的变体。
接着我们将会进入多项式回归的讨论,这是一个更为复杂的模
型,更适合非线性数据集。由于该模型的参数比线性模型更多,因此更容易造成对训练数据过拟合,我们将使用学习曲线来分辨这种情况
是否发生。然后,再介绍几种正则化技巧,降低过拟合训练数据的风
险。
最后,我们将学习两种经常用于分类任务的模型:Logistic回归
和Softmax回归。
4.1 线性回归
在第1章中,我们学过一个简单的生活满意度的回归模型:
life_satisfaction=θ0+θ1×GDP_per_capita。
这个模型就是输入特征GDP_per_capita的线性函数,θ0和θ1是模
型的参数。
更为概括地说,线性模型就是对输入特征加权求和,再加上一个我
们称为偏置项(也称为截距项)的常数,以此进行预测,如公式4-1所
示。
公式4-1:线性回归模型预测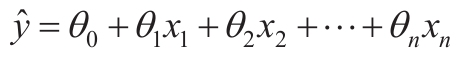
在此等式中:
- 是预测值。
- n是特征数量。
- xi是第i个特征值。
- θj是第j个模型参数(包括偏差项θ0和特征权重θ1,θ2,…,θn)。
可以使用向量化的形式更简洁地表示,如公式4-2所示。
公式4-2:线性回归模型预测(向量化形式)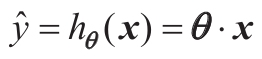
在此等式中:
- θ是模型的参数向量,其中包含偏差项θ0和特征权重θ1至 θn。
- x是实例的特征向量,包含从x0到xn,x0始终等于1。
- θ·x是向量θ和x的点积,它当然等于θ0x0+θ1x1+θ2x2+…+θnxn。
- hθ是假设函数,使用模型参数θ
在机器学习中,向量通常表示为列向量,是有单一列的二维数
组。如果θ和x为列向量,则预测为 ,其中θT为θ(行向量而
不是列向量)的转置,且θTx为θT和x的矩阵乘积。当然这是相同的预
测,除了现在是以单一矩阵表示而不是一个标量值。在本书中,我将使
用这种表示法来避免在点积和矩阵乘法之间切换。
这就是线性回归模型,我们该怎样训练线性回归模型呢?回想一
下,训练模型就是设置模型参数直到模型最拟合训练集的过程。为此,
我们首先需要知道怎么测量模型对训练数据的拟合程度是好还是差。在
第2章中,我们了解到回归模型最常见的性能指标是均方根误差
(RMSE)(见公式2-1)。因此,在训练线性回归模型时,你需要找到
最小化RMSE的θ值。在实践中,将均方误差(MSE)最小化比最小化
RMSE更为简单,二者效果相同(因为使函数最小化的值,同样也使其平
方根最小)[1]。
在训练集X上,使用公式4-3计算训练集X上线性回归的MSE,hθ为
假设函数。
公式4-3:线性回归模型的MSE成本函数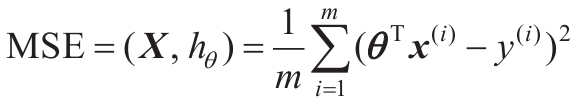
这些符号大多数在第2章中提到过,唯一的区别是h换成了hθ,以
便清楚地表明模型被向量θ参数化。为了简化符号,我们将MSE(X,
hθ)直接写作MSE(θ)。
4.1.1 标准方程
为了得到使成本函数最小的θ值,有一个闭式解方法——也就是一
个直接得出结果的数学方程,即标准方程(见公式4-4)。
公式4-4:标准方程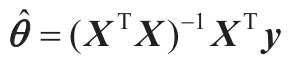
这个方程中:
· 是使成本函数最小的θ值。
·y是包含y(1)到y(m)的目标值向量。
我们生成一些线性数据来测试这个公式(见图4-1):
图4-1:随机生成的线性数据集

若有收获,就点个赞吧
0 人点赞
