你要做的第一件事是使用加州人口普查的数据建立起加州的房价模型。数据中有很多指标,诸如每个街区的人口数量、收入中位数、房价中位数等。街区是美国人口普查局发布样本数据的最小地理单位(一个街区通常人口书为600到3000人)。这里将其简称为“区域”。
模型需要从这个数据中学习,从而能够根据所有其他指标,预测任意区域的房价中位数。
提示作为一个习惯良好的数据科学家,要做的第一件事应该是拿出机器学习项目清单。你可以从附录B中的项目清单项开始,它适合大多数机器学习项目,但还是要确保它能满足要求。本章将会讨论这个清单中的部分内容,但也会跳过一部分,有些是不需要多做解释,有些则在后面章节展开介绍。
2.2.1 框架问题
作为数据工程师,你问老板的第一个问题应该是业务目标是什么,因为建立模型本身可能不是最终的目标。公司期望指导如何使用这个模型,如何从中获益?这才是重要的问题,因为这将决定你怎么设定问题,选择什么算法,使用什么测量方式来评估模型的性能,以及应该化多少精力来进行调整。
老板回答说,这个模型的输出(对一个区域房间中位数的预测)将会跟其他许多信号一起被传输给另一个机器学习系统(如下图所示)。而这个下游系统将被用来决策一个给定的区域是否值得投资。因为直接影响到收益,所以正确获得这个信息至关重要。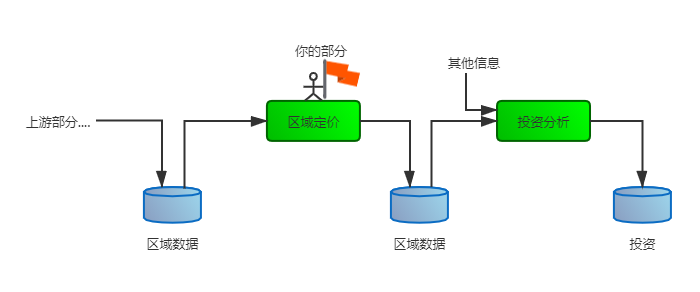
图2-1:一个针对房地产投资的机器学习流水线
要向老板询问的第二个问题时当前的解决方案(如果有的话)。你可以将其当作参考,也能从中获得解决问题的洞察。老板回答说现在是由专家团队在手动估算区域的住房价格:一个团队持续收集最新的区域信息,当他们不能得到房价中位数时,便使用复杂的规则来进行估算。
这个过程既昂贵又耗时,而且估算结果还不令人满意,在某些情况下,他们估计的房价和实际房价的偏差高达20%。这就是为什么该公司认为给定该区域的其他数据有助于训练模型来预测该区域的房价中位数。普查数据看起来像是一个可用于此目的的很好的数据集,因为它包括数千个区域的房价中位数和其他数据。
有了这些信息,你现在可以开始设计系统了。首先,你需要回答框架问题:是有监督学习、无监督学习还是强化学习?是分类任务、回归任务还是其他任务?应该使用批量学习还是在线学习技术。
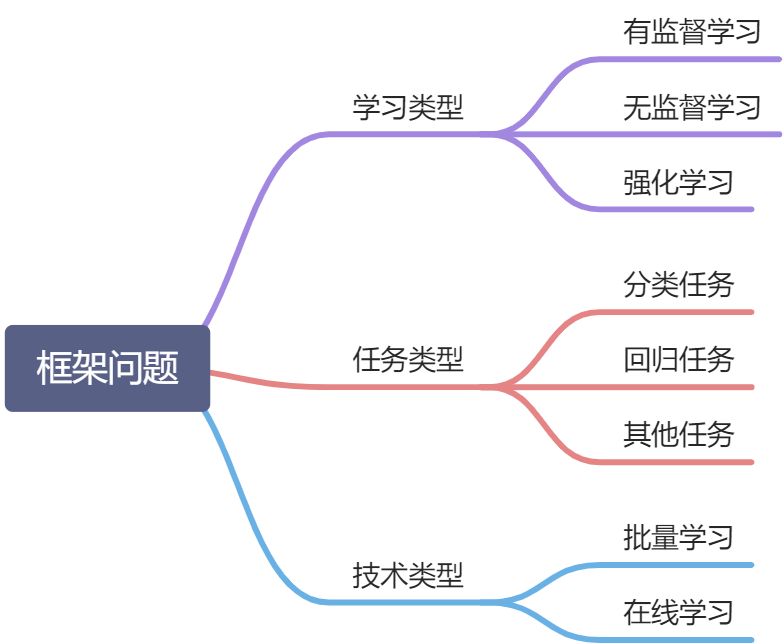 图2-2:机器学习框架问题
图2-2:机器学习框架问题
显然,这是一个典型的有监督学习任务,因为已经给出了标记的训练示例(每个实列都有预期的产出,也就是该区域的房价中位数)。并且这也是一个典型的回归任务,因为你要对某个值进行预测。更具体地说,这是一个多重回归问题,因为系统要使用多个特征进行预测(使用区域的人口,收入中位数等)。这也是一元回归问题,因为我们仅仅尝试预测每个区域的单个值。如果我们试图预测每个区域的多个值,那将是多元回归问题。最后,我们没有一个连续的数据流不断流进系统,所以不需要针对变化的数据做出特别调整,数据量也不是很大,不需要多个内存,所以简单的批量学习应该就能胜任。
提示如果数据庞大,则可以跨多个服务器拆分批处理学习(使用MapReduce技术)或使用在线学习技术。
2.2.2 选择性能指标
下一步是选择性能指标。回归问题的典型性能指标是均方根误差(RMSE)。它给出了系统通常会在预测中产生多大误差,对于较大的误差,权重较高。公式2-1给出了计算RMSE的公式。
公式2-1:均方根误差(RMSE)
尽管RMSE通常是回归任务的首选性能指标,但在某些情况下,你可能更喜欢使用其他函数。例如,假设有许多异常区域。在这种情况下,你可以考虑使用平均绝对误差(Mean Absolute Error,MAE,也称为平均绝对偏差。参见公式2-2):
公式2-2:平均绝对误差(MAE):
2.2.3 检查假设
最后,列举和验证到目前为止(由你或者其他人)做出的假设,是一个非常好的习惯。这可以在初期检查出严重问题。例如,当机器学习系统输出区域价格给下游系统时,我们的假设是价格会被使用。但是,如果下游系统实际上是将价格转换成为类别(例如,廉价,中等或者昂贵),转而使用这些类别,而不是价格本身呢?在这种情况下,并不需要完全准确地预估价格,你的系统只需要得出正确的类别就够了。如果是这种情况,那么这个问题就应该被设定为分类任务而不是回归任务。你肯定不会愿意在回归系统上努力几个月之后才发现这一点。
跟下游系统的团队证实需要的确实是价格而不是类别,那么一切准备就绪,可以开始编程了。

若有收获,就点个赞吧
0 人点赞
