1.1 分层需求分析
在之前介绍实时数仓概念时讨论过,建设实时数仓的目的,主要是增加数据计算的复用性。每次新增加统计需求时,不至于从原始数据进行计算,而是从半成品继续加工而成。
我们这里从 Kafka 的 ODS 层读取用户行为日志以及业务数据,并进行简单处理,写回到 Kafka 作为 DWD 层。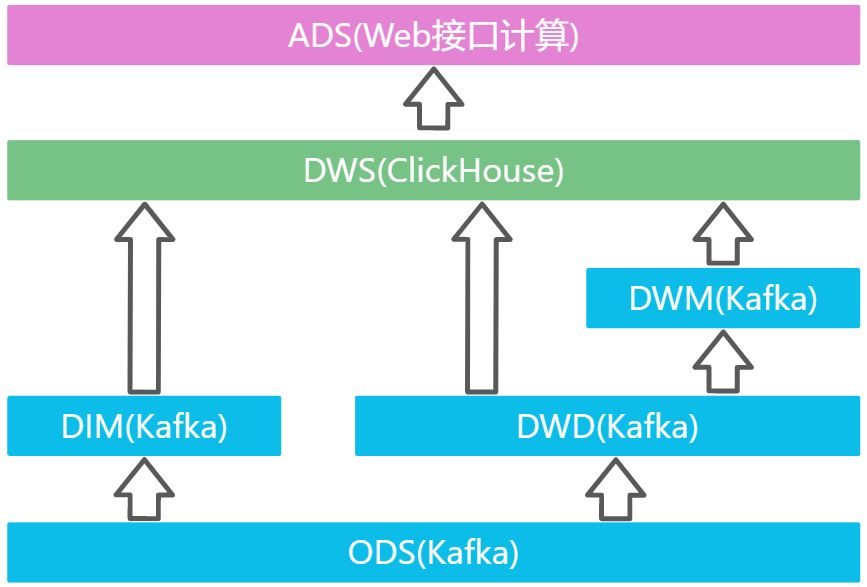
1.2 每层职能
| 分层 | 数据描述 | 生成计算工具 | 存储媒介 |
|---|---|---|---|
| ODS | 原始数据,日志和业务数据 | 日志服务器,FlinkCDC | Kafka |
| DWD | 根据数据对象为单位进行分流,比如订单,页面访问等 | Flink | Kafka |
| DIM | 维度数据 | Flink | HBase |
| DWM | 对于部分数据对象进行进一步加工,比如独立访问,跳出行为。依旧是明细数据。 | Flink | Kafka |
| DWS | 根据某个维度主题将多个事实数据进行轻度聚合,形成主题宽表。 | Flink | Clickhouse |
| ADS | 把Clickhouse中的数据根据可视化需要进行删选 聚合 | Clickhouse SQL |
Clickhouse |
1.3 DWD层数据准备实现思路
- 功能1:环境搭建
- 功能2:计算用户行为日志DWD层
- 功能3:计算业务数据DWD层

若有收获,就点个赞吧
0 人点赞
