2.3 获取数据
2.3.1 创建工作区
使用Anaconda创建一个隔离的Python环境,并在环境中安装需要使用到的Python模块:Jupyter、Numpy、Pandas、Matplotlib以及Scikit-Learn。
打开jupyter,新建Python3文档,检查环境是否安装成功,上述各模块可在需要时安装即可。
图2-3:jupyter hello world
2.3.2 下载数据
在典型环境中,数据存储在关系型数据库里(或其他一些常用数据库),并分布在多个表/文档/文件中。访问前,你需要先获得证书和访问权限,并熟悉数据库模式。不过,在本项目中,事情要简单得多,:你只需要下载一个压缩文件housing.tgz即可,这个文件已经包含所有的数据——一个以逗号来分隔值的CSV文档housing.csv.
你可以选择使用浏览器下载压缩包,运行 tar xzf housing.tgz 来解压缩并提取CSV文件,但更好的选择是创建一个小函数来实现它。尤其是当数据会定期发生变化时,这个函数非常有用:你可以编写一个脚本,在需要获取最新数据集时直接运行(或者也可以设置一个定期自动运行的计划任务)。如果需要在多台机器上安装数据集,这个自动获取数据的函数也非常好用。
获取数据的函数如下所示:
import osimport tarfileimport urllib.requestDOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"HOUSING_PATH = os.path.join("datasets","housing")HOUSING_URL = DOWNLOAD_ROOT+"datasets/housing/housing.tgz"def fetch_housing_data(housing_url = HOUSING_URL,housing_path = HOUSING_PATH):os.makedirs(housing_path,exist_ok= True)tgz_path = os.path.join(housing_path,"housing.tgz")urllib.request.urlretrieve(housing_url,tgz_path)housing_tgz = tarfile.open(tgz_path)housing_tgz.extractall(path = housing_path)housing_tgz.close()
现在,每当你调用fetch_housing_data(),就会自当在工作区中创建一个datasets/housing目录,然后下载housing.tgz文件,并将housing.csv解压到这个目录。
现在我们使用pandas加载数据。也应该写一个小函数来加载数据。
import pandas as pddef load_housing_data(housing_path=HOUSING_PATH):csv_path = os.path.join(housing_path,"housing.csv")return pd.read_csv(csv_path)
这个函数会返回一个包含所有数据的pandas DataFrame对象。
2.3.3 快速查看数据结构
使用DataFrames的head()方法查看前5行数据时怎样的(图2-5)。
housing = load_housing_data()
housing.head()
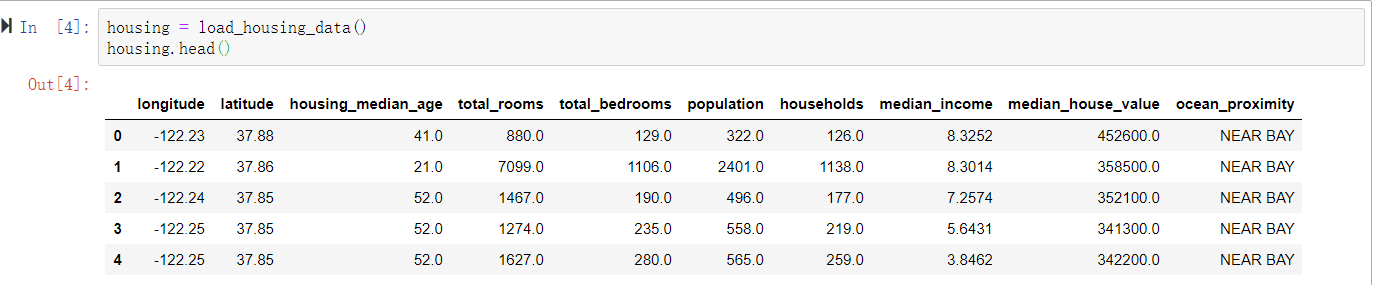
图2-5:数据集的前5行
每一行代表一个区域,总共有10个属性:longitude、latitude、housing_median_age、total_rooms、total_bedrooms、population、households、median_income、median_house_value以及ocean_proximity。
通过info()方法快速获取数据集的简单描述,特别是总行数、每个属性的类型和非空值的数量(见图2-6)。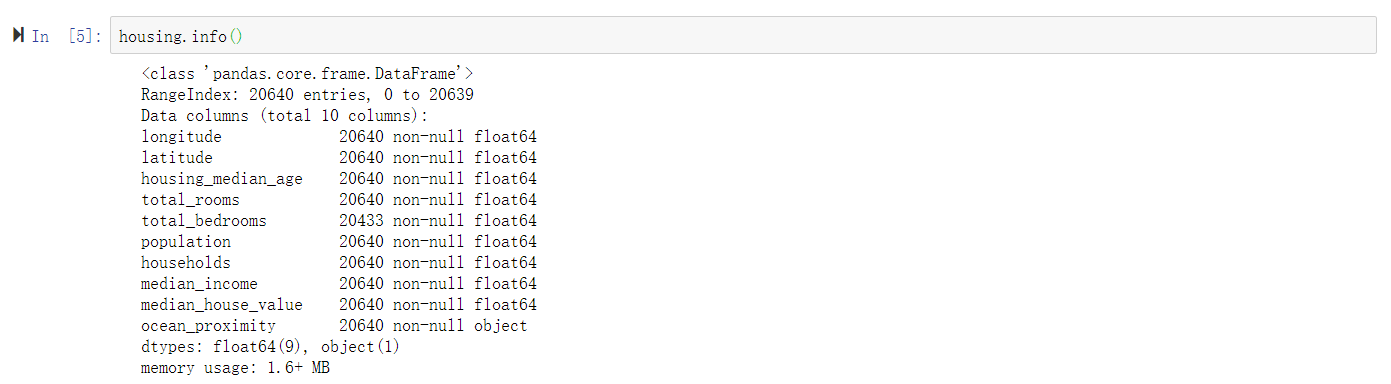
图2-6:住房信息
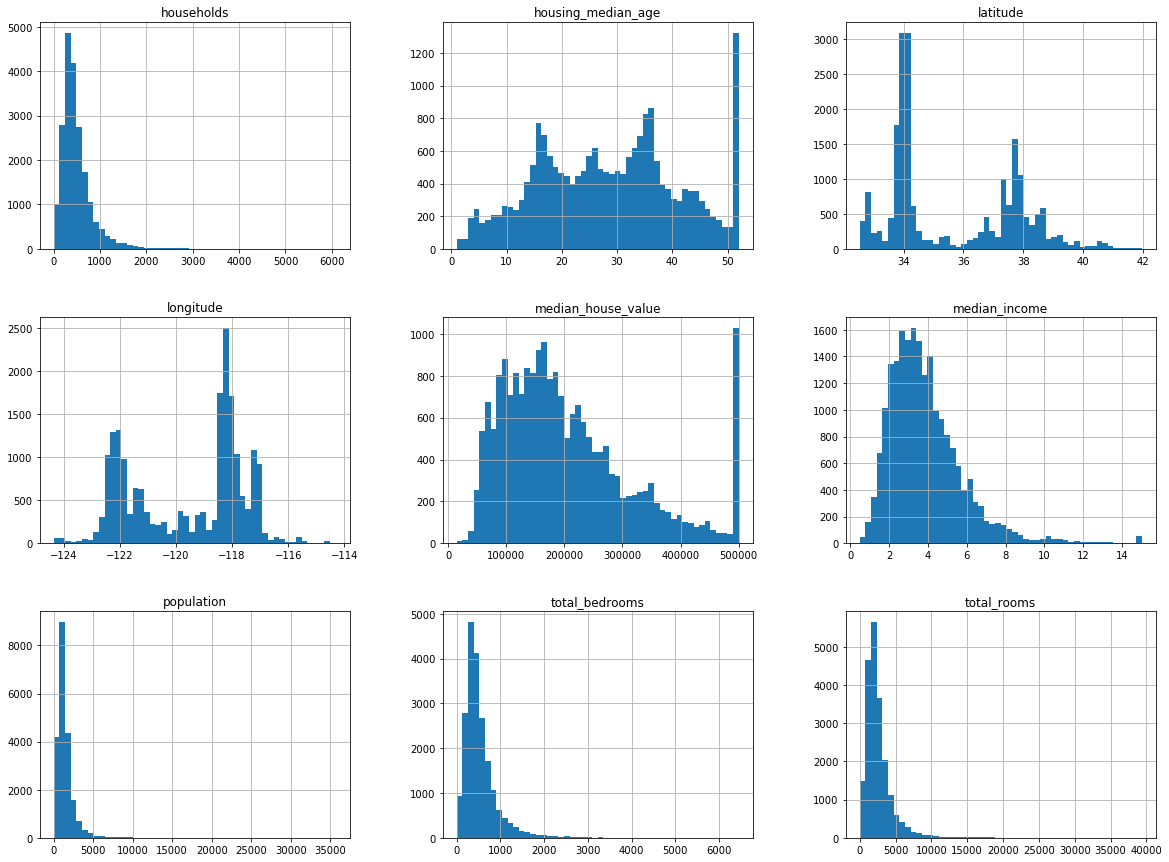
数据集中包含20640个实列,以机器学习的标准来看,这个数字非常小,但是用来学习是个完美的开始。注意,total_bedrooms这个属性只有20433个非空值,这意味着有207ge 区域缺失这个特征。我们后面需要考虑到这一点。
除了ocean_poximity类型是object以外,其他所有属性的字段都是数字,因此它可以是任何类型的Python对象,不过从CSV文件中加载了该数据,所以它必然是文本属性。通过查看前5行,注意该列的值是重复的,意味着它有可能是一个分类属性。使用value_counts()方法查看有多少种分类存在,每种分类下分别有多少个区域:
>>>housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
再看看其他区域,通过describe()方法可以显示数值属性的摘要(见图2-7)。
count、mean、min以及max行的意思很清楚。需要注意的是,这里的空值会被忽略(因此本例中,total_bedrooms的count是20433而不是20640)。std行显示的是标准差(用来测量数据的离散程度)。25%、50%和75%行显示相应的百分位数:百分位数表示一组观测值中给定百分比的观测值都低于该值。例如,对于housing_median_age的值,25%的区域小于18,50%的区域小于29,以及75%的区域小于37。这些通常称为25百分位数(或者第一四分位数)、中位数以及75百分位数(或者第三四分位数)。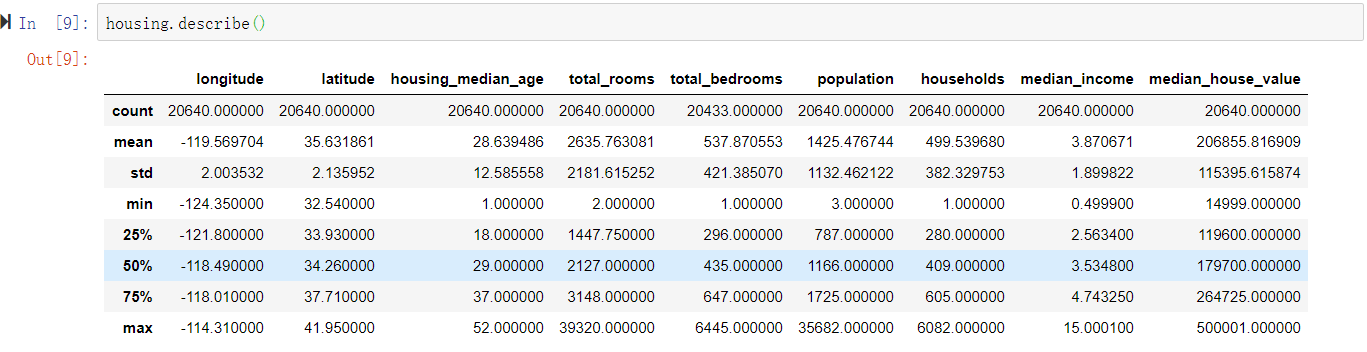
图2-7:每个数值属性的摘要
另一种快速了解数据类型的方法是回值每个数值属性的直方图。直方图用来显示给定值范围(横轴)的实例数量(纵轴)。你可以一次绘制一个属性,也可以再整个数据集上调用hist方法(如以下代码示例所示),绘制每个属性的直方图(见图2-8)。
%matplotlib inline #only in jupyter notebook
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(20,15))
plt.show()
2.3.4 创建测试集
理论上,创建测试集非常简单,只需要随机选择一些实例,通常是数据集的20%(如果数据集很大,比例将更小),然后将他们放在一边:
import numpy as np
def split_train_test(data,test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_setsize]
train_indices = shuffled_indices[test_setsize:]
return data.iloc[train_indices],data.iloc[test_indices]
你可以这样使用如下函数:
>>>train_set,test_set = split_train_test(housing,0.2)
>>>len(train_set)
16512
>>>len(test_set)
4128
这样确实可以,但是并不完美,如果你再运行一遍,它又会产生不同的数据集!这样下去,你将会看到整个完整的数据集,而这正是创建测试集时需要避免的。
解决方案之一时在第一次运行程序后即保存测试集,随后的运行只是加载它而已。另一种方法实在调用np.random.permutation()之前设置一个随机数生成器的种子(例如,np.random.seed(42)),从而让它始终生成相同的随机索引。
但是,这两种解决方案在下次获取更新的数据时都会中断。为了即使在更新数据集之后也有一个稳定的训练测试分割,常见的解决方案是每个实例都使用一个标识符来决定是否进入测试集(假定每个实例都有一个唯一且不变的标识符)。例如,你可以计算每个实例标识符的哈希值,如果这个哈希值小于或等于最大哈希值的20%,则将该实例放入测试集。这样可以确保测试集在多个运行里都是一致的,即便更新数据集也仍然一致。新实例的20%将被放入新的测试集,而之前训练集中的实例也不会被放入新的测试集。
实现方式如下:
from zlib import crc32
def test_set_check(idntifier,test_ratio):
return crc32(np.int64(identifier)) & oxffffffff < test_ratio * 2**32
def split_train_test_by_id(data,test_ratio,id_columu):
ids = data[id_columu]
in_test_set = ids.apply(lambda id_:test_set_check(id_,test_ratio))
return data.loc[~in_test_set],data.loc[in_test_set]
不幸的是,housing数据集没有标识符列。最简单的解决方法是使用行索引作为ID:
housing_with_id = housing.reset_index() adds an 'index' column
train_set,test_set = split_tarin_test_by_id(housing_with_id,0.2,"index")
如果使用行索引作为唯一标识符,你需要确保在数据集的末尾添加新数据,并且不会删除任何行。如果不能保证这一点,那么你可以尝试使用某个最稳定的特征来创建唯一标识符。例如,一个区域的经纬度肯定几百万年都不会变,你可以将它们组合成如下的ID:
housing_with_id["id"] = housing["longitude"]*1000 + housing["latitude"]
train_set,test_set = split_train_test_by_id(housing_with_id,0.2,"id")
注意位置信息实际上是相当粗糙的,因此许多区域将具有完全相同的ID,它们将最终会在同一组(测试集或训练集)中。这引入了一些不幸的抽样偏差。
Scikit-Learn 提供了一些函数,可以通过多种方式将数据集分成多个子集。最简单的函数时train_test_split(),它与前面定义的函数split_train_test()几乎相同,除了几个额外的特征。首先,它也有random_state参数,让你可以像之前提到过的那样设置随机生成器种子;其次,你可以把函数相同的多个数据集一次性发送给它,它会根据相同的索引将其拆分(例如,当你有一个单独的DataFrame用于标记时,这就非常有用):
from sklearn.model_selection import train_test_split
train_set,test_set = train_test_split(housing,test_size=0.2,random_state=42)
到目前为止,我们思考了纯随机的抽样方法,如果数据集足够庞大,这种方法通常不错,如果不是,则有可能导致明显的抽样偏差。如果你咨询专家,他们会告诉你,要预测房价中位数,收入中位数是一个非常重要的属性。于是你希望在收入属性上,测试集能够代表整个数据集种各种不同类型的收入。由于收入中位数是一个连续的数值属性,所以你得先创建一个收入类别得属性。我们先来看一下收入中位数得直方图(见图2-8):大多数收入中位数值聚集在1.5~6左右,但也有部分超过了6万美元。在数据集种,每一层都要有足够数量的实例,这一点至关重要,不然数据不足的岑,其重要程度很有可能会被错估。也就是说,你不应该将层数分的太多,每一层应该要足够大才行。下面这段代码是用 pd.cut()来创建5个收入类别属性的(用1~5来做标签),0~1.5是类别1,1.5~3是类别2,以此类推:
housing["income_cat"] = pd.cut(housing["median_income"],bins=[0.,1.5,3.0,4.5,6.,np.inf],labels=[1,2,3,4,5])
housing["income_cat"].hist()
这些收入类别如图2-9所示。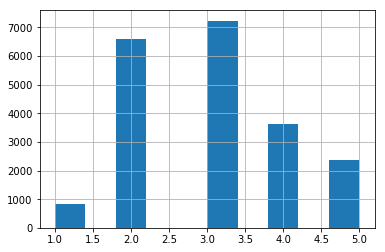
图2-9:收入类别的直方图
现在,你可以根据收入类别进行分层抽样了。使用Scikit-Learn的StratifiedShuffleSplit类:
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index,test_index in split.split(housing,housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
看看这个运行是否如我们所料。首先,可以看看测试集中收入类别比例分布:
>>>strat_test_set["income_cat"].value_counts()/len(strat_test_set)
3 0.350533
2 0.318798
4 0.176357
5 0.114583
1 0.039729
Name: income_cat, dtype: float64
如果你比较在三种不同的数据集(完整数据集、分成抽样的测试集、纯随机抽样的测试集)中收入类别比例分布。你会发现,分层抽样的测试集中的比例分布与完整数据集中的几乎一致,而纯随机抽样的测试集结果则是有偏的。
现在,你可以删除income_cat属性,将数据恢复原样了:
for set_ in (strat_train_set,strat_test_set):
set_.drop("income_cat",axis=1,inplace=True)
我们花了相当长的时间在测试集的生成上,理由很充分:这是机器学习项目中经常被忽视但是却至关重要的一部分。并且,当讨论到交叉验证时,这里谈到的许多想法也是对其大有裨益。现在,是时候进入下一阶段了(数据探索)。

若有收获,就点个赞吧
0 人点赞
