2.4 从数据探索和可视化中获得洞见
将测试集放一边,你能探索的只有训练集。此外,如果训练集非常庞大,你可以抽样一个探索集,不过我们这个案例的测试集非常小,完全可以在整个数据集上操作。让我们创建一个副本,这样可以随便尝试而不损害训练集:
housing = strat_train_set.copy()
2.4.1 将地理数据可视化
由于存在地理位置信息(经度和纬度),因此建立一个各区域的分布图以便于可视化数据是一个很好的想法(见图2-11):
housing.plot(kind="scatter",x="longitude",y="latitude")
图2-11:数据的地理散点图
没错,这除了看起来跟加州一样以外,很难再看出任何其他的模式。将alpha选项设置为0.1,可以更清楚的看到高密度数据点的位置(见图2-12)
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)
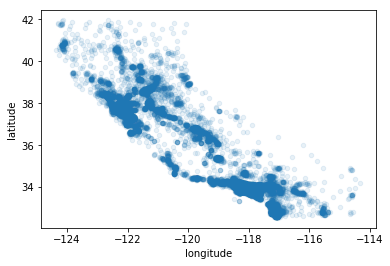
图2-12:突出高密度区域的更好的可视化
现在好多了:可以清楚地看到高密度区域,也就是湾区,洛杉矶和圣地亚哥附近,同时在中央山谷有一条相当高密度的长线,特别是萨克拉门托和弗雷斯诺附近。
我们的大脑非常善于从图片中发现模式,但是你需要玩转可视化参数才能让这些模式凸显出来。
现在,再来看看房价(见图2-13)。每个圆的半径大小代表每个区域的人口数量(选项s),颜色代表价格(选项c)。我们使用一个名叫jet的预定义颜色表(选项cmap)来进行可视化,颜色范围从蓝(低)到红(高):
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing["population"]/100,label="population",figsize=(10,7),c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True)plt.legend()
图2-13表明房价和地理位置(例如靠近海)和人口密度息息相关,这一点你可能早已知晓。一个通常很有用的方法是使用聚类算法来检测主集群,然后再为各个集群中心添加一个新的衡量邻近距离的特征。海洋邻近度可能就是一个很有用的属性,不过在北加州,沿海地区的房价并不是很高,所以这个简单的规则也不是万能的。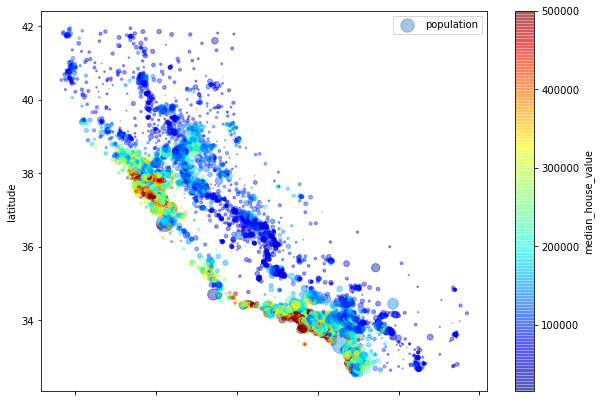
图2-13:加州房价:红色昂贵,蓝色便宜,较大的圆圈表示人口较多的地区。
2.4.2 寻找相关性
由于数据集不大,你可以使用corr()方法轻松计算出每对属性之间的标准相关系数(也称为皮尔逊r):
corr_matrix = housing.corr()
现在看看每个属性与房价中位数的相关性分别是多少:
>>>corr_matrix["median_house_value"].sort_values(ascending=False)median_house_value 1.000000median_income 0.688075total_rooms 0.134153housing_median_age 0.105623households 0.065843total_bedrooms 0.049686population -0.024650longitude -0.045967latitude -0.144160Name: median_house_value, dtype: float64
相关系数的范围从-1变化到1 。越接近1,表示有越强的正相关,例如,当收入中位数上升时,房价中位数也趋于上升。当系数接近于-1时,表示有较强的负相关。我们可以看到纬度和房价中位数之间呈现出轻微的负相关(也就是说,越往北走,房价趋于下降)。最后,系数越靠近0则说明二者之间没有线性相关性。
还有一种方法可以检测属性之间的相关性,就是使用pandas的scatter_matrix函数,它会回值出每个数值属性相对于其他数值属性的相关性。现在我们有11个数值属性,可以得到 个图像,篇幅原因无法完全展示,这里我们仅关注那些与房价中位数属性最相关的,可算作时最有潜力的属性(见图2-15):
个图像,篇幅原因无法完全展示,这里我们仅关注那些与房价中位数属性最相关的,可算作时最有潜力的属性(见图2-15):
from pandas.plotting import scatter_matrixattributes = ["median_house_value","median_income","total_rooms","housing_median_age"]scatter_matrix(housing[attributes],figsize=(12,8))
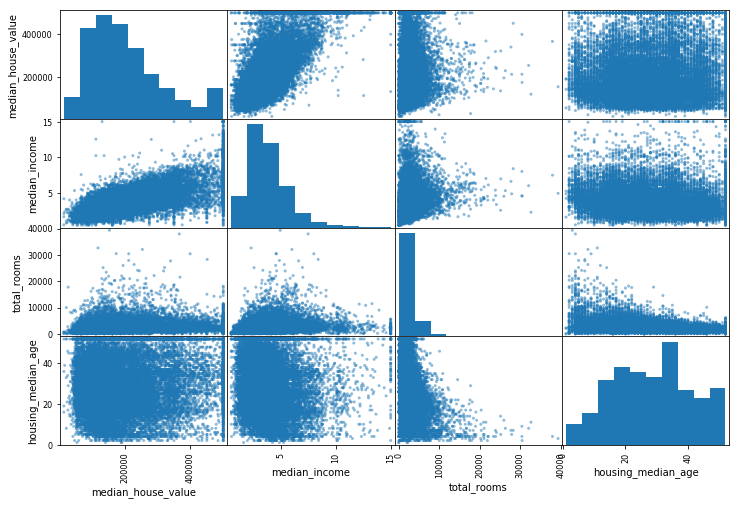
图2-15:这个散布矩阵显示每个数值属性相对于其他数值属性,并绘制每个数值属性的直方图
如果pandas绘制每个变量对自身的图像,那么主对角线(从左上到右下)将全部都是直线,这样毫无意义。所以取而代之的方法是,pandas在这几个图中显示了每个属性的直方图(还有其他选择可选,详情请参考pandas文档)。
最有潜力能够预测房价中位数的属性是收入中位数,所以我们放大来看看其相关性的散点图(见图2-16):
housing.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)
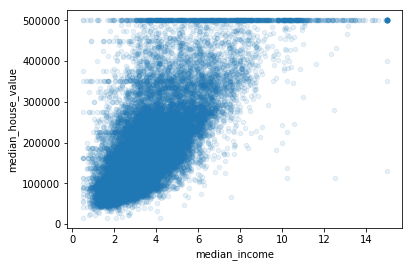
图2-16:收入中位数与房价中位数
图2-16说明了几个问题,首先,二者的相关性确实很强,你可以清楚的看到上升的趋势,并且也不是太分散。其次,前面我们提到过50万美元的价格上限在图中是一条清晰的水平线,不过除此之外,图中还显示出几条不那么明显的直线,为了避免你的算法学习之后重现这些怪异的数据,你可能会尝试删除这些相应区域。
2.4.3 实验不同属性的组合
在准备给机器学习算法输入数据之前,你要做的最后一件事应该事尝试各种属性的组合。我们试着创建一些新属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]housing["population_per_household"] = housing["population"]/housing["households"]
再看看相关矩阵:
>>>corr_matrix = housing.corr()>>>corr_matrix["median_house_value"].sort_values(ascending=False)median_house_value 1.000000median_income 0.688075rooms_per_household 0.151948total_rooms 0.134153housing_median_age 0.105623households 0.065843total_bedrooms 0.049686population_per_household -0.023737population -0.024650longitude -0.045967latitude -0.144160bedrooms_per_room -0.255880Name: median_house_value, dtype: float64
怎么样,还不错吧,新属性bedroom_per_room较之“房间总数”或“卧室总数”与房价中位数的相关性都要高得多。

若有收获,就点个赞吧
0 人点赞
