Shell简介
Shell 是一个C语言编写的程序,他是用户使用Linux的桥梁。Shell 这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Shell 既是一种命令语言,又是一种程序设计语言。
- 种类
- Bourne Shell(/usr/bin/sh 或 bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for root(/sbin/sh)
程序编程风格:
- 过程式:以指令为中心,数据服务于命令
- 对象式:以数据为中心,命令服务于数据
Shell 是一种过程式编程,过程式编程的特征是:顺序执行、循环执行、选择执行
编程语言分类:
- 编译型语言
- 解释型语言
Shell是一种解释型语言。
运行脚本的方法有两种:
- 给予文件执行权限,通过具体的文件路径指定文件执行:chmod +x test.sh,./test.sh
- 直接运行解释器,将脚本作为解释器的参数执行:bash test.sh
- bash 退出状态码:
- 范围是0-255
- 脚本中一旦遇到 exit 命令,脚本会立即终止,终止退出状态取决于 exit 后面的数字
- 如果没有给脚本指定退出状态码,整个脚本的退出状态码取决于脚本中执行的最后一条命令的状态
变量
变量命名
- 规则
- 只能使用英文字母,数字和下划线,首字母不能是数字
- 中间不能有空格,可以使用下划线
- 不能使用标点符号
- 不能使用 bash 中的关键字(可用 help 命令查看bash保留的关键字) ```bash 有效命名: RUNOOB LD_LIBRARY_PATH _var var2
无效命名: ?var=123 user*name=runoob
如果要将命令执行的结果赋予变量的话可以使用反引号` `或者是 $() ,如:```bashfor file in `ls /etc`或for file in $(ls /etc)
以上语句是将命令ls /etc 的执行结果循环出来。
使用变量
使用一个定义过的变量,只要在变量前面加上美元符号 $ 即可,如:
your_name="qinjx"echo $your_nameecho ${your_name}
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
for skill in Ada Coffe Action Java; doecho "I am good at ${skill}Script"done
如果不给skill变量加花括号,写成echo “I am good at $skillScript”,解释器就会把$skillScript当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
已定义的变量,可以被重新定义,如:
your_name="tom"echo $your_nameyour_name="alibaba"echo $your_name
注意第二次复制时不能写成$yourname="alibaba",只有在使用变量的时候才使用 $ 符号。
只读变量
使用 readonly 可以把变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bashmyUrl="https://www.google.com"readonly myUrlmyUrl="https://www.runoob.com"# 运行脚本,结果如下:/bin/sh: NAME: This variable is read only.
删除变量
使用 unset 命令可以删除变量,语法:
unset variable_name
变量被删除后不能再次使用。unset 命令不能删除只读变量。
#!/bin/shmyUrl="https://www.runoob.com"unset myUrlecho $myUrl
变量类型
运行shell时,会同时存在三种变量:
- 局部变量,局部变量是在当前命令或脚本中定义的,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量(包括子shell进程)。
- 变量赋值:name = “value”
- 环境变量,所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- 变量声明1:export name = “value”
- 变量声明2:declare -x name = “value”
- bash中有许多内建的变量环境:SHELL,PATH等等
- shell变量,shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
- 特殊变量:? 0 @ # ```bash $1,$2,…:对应调用第1,第2等参数 $0:命令本身 $:传递给脚本的所有参数(把素有参数当作整体) $@:传递给脚本的所有参数 $#:传递给脚本的参数的个数
案例1:创建myecho.sh
!/bin/bash
echo “命令本身是 $0” echo “第一个参数是 $1” echo “第二个参数是 $2” echo “一共有 $# 个参数” echo “所有参数是 $@”
执行:./myecho.sh 1 2 3 4 5 [root@server1 ~]# bash myecho.sh 1 2 3 4 5 命令本身是 myecho.sh 第一个参数是 1 第二个参数是 2 一共有 5 个参数 所有参数是 1 2 3 4 5
===================================================
案例2:判断所给文件的行数 [root@server1 ~]# wc -l /etc/passwd 21 /etc/passwd [root@server1 ~]# wc -l /etc/passwd | cut -d ‘ ‘ -f1 21
创建linecount.sh
!/bin/bash
linecount=wc -l $1 | cut -d ' ' -f1
echo “$1 文件有 ${linecount}行”
执行判断/etc/passwd有多少行 [root@server1 ~]# bash linecount.sh /etc/passwd /etc/passwd 文件有 21行
PS:这里要区分单引号和双引号。单引号是弱引用,单引号中就是字符串,没有其他意义;双引号是强引用,双引号中的$变量会取到变量的值。<a name="zHwaT"></a># 数组- 数组赋值```bash语法格式:array_name=(value1 ... valuen)示例:my_array=(A B "C" D)array_name[0]=value0array_name[1]=value1array_name[2]=value2
读取数组
读取数组:${array_name[index]}获取数组中的所有元素:my_array[0]=Amy_array[1]=Bmy_array[2]=Cmy_array[3]=Decho "数组的元素为: ${my_array[*]}"echo "数组的元素为: ${my_array[@]}"
获取数组的长度
获取数组的长度:my_array[0]=Amy_array[1]=Bmy_array[2]=Cmy_array[3]=Decho "数组元素个数为: ${#my_array[*]}"echo "数组元素个数为: ${#my_array[@]}"
算术运算
运算符 ```bash
- / % * … 增强赋值: +=,-=,=,/=,%= 乘法符号有些场景中需要转义 : *\ bash有内建随机数生成器:$RANDOM ```
- 完成算术运算
(1) let var(变量名)=算术表达式(2) var=$[算术表达式](3) var=$((算术表达式))(4) var=$(expr argl arg2 arg3 …)
练习1:计算/etc/passwd文件中第10个用户和第20个用户的ID之和
思路:
首先要知道/etc/passwd文件中用户ID在哪
可以发现第三列是用户ID,所以现在的任务是将文件的第三列过滤出来: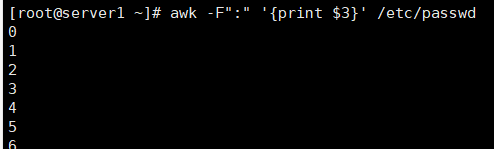
最后要把第10个和第20个用户ID提取出来 ```bash
[root@server1 ~]# vim id_sum.sh
```bash
[root@server1 ~]# vim id_sum.sh!/bin/bash
userid1=$(awk -F”:” ‘{print $3}’ /etc/passwd | sed -n ‘10p’) userid2=$(awk -F”:” ‘{print $3}’ /etc/passwd | sed -n ‘20p’) userid_sum=$[$userid1+$userid2] echo $userid_sum
[root@server1 ~]# bash id_sum.sh 1011
<a name="iUMsC"></a>## 练习2:传递两个文件路径参数给脚本,计算这两个文件之中所有空白行之和思路:首先要提取出文件中的空白行:grep '^$' [文件名]。<br />然后计数有多少行<br />```bash[root@server1 ~]# vim blankline_count.sh#!/bin/bashblank1=`grep '^$' $1 | wc -l`blank2=`grep '^$' $2 | wc -l`let count=$blank1+$blank2echo "$1 和 $2 两个文件的空白行之和为 $count"[root@server1 ~]# bash blankline_count.sh /root/anaconda-ks.cfg /root/test1/root/anaconda-ks.cfg 和 /root/test1 两个文件的空白行之和为 8
练习3:统计/etc/,/var/,/usr/目录下有多少一级子目录和文件
[root@server1 ~]# vim count_file.sh#!/bin/bashsum_etc=$(find /etc/ | wc -l)sum_var=$(find /var/ | wc -l)sum_usr=$(find /usr/ | wc -l)sum_file=$[$sum_etc+$sum_var+$sum_usr]echo "/etc/、/var/、/usr/下一级子目录和文件有${sum_file}个"[root@server1 ~]# bash count_file.sh/etc/、/var/、/usr/下一级子目录和文件有37284个
条件测试
案例
采集系统相关信息
#!/bin/bashpid_sum=`ps -ef | wc -l`mem_use_per=`free | awk '/Mem/{print$3/$2*100 '%'}'`let disk_volume=`df|awk '{disk_volume+=$2} END {print disk_volume}'`let disk_free=`df|awk '{disk_free+=$4} END {print disk_free}'`disk_use_per=`awk 'BEGIN{printf"%.2f\n",((1-'$disk_free/$disk_volue')*100)}'`cpu_cores=`cat /proc/cpuinfo | awk -F: '/core/{cores+=$2} END {print cores}'`echo "系统进程总数:$pid_sum"echo "内存使用率:$mem_use_per"echo "磁盘总空间:$disk_volume"echo "磁盘剩余空间:$disk_free"echo "磁盘占用率:${disk_use_per}%"echo "cpu总核数:$cpu_cores"
详解:
- 进程总数,通过ps -ef命令查看所有进程,在通过wc -l统计输出了多少行,即有多少进程。
- 内存使用率,通过free命令可以查看实体内存和交换内存,再通过awk工具的正则表达式/Mem/先找到Mem这条记录,然后执行 打印第3列除第2列乘100 加上一个百分号。
- 磁盘总空间,通过df命令查看磁盘使用情况,再通过awk工具第2列的和并打印出来,然后通过let命令赋值给disk_volume(需注意的是let命令只能整数赋值)。磁盘剩余空间类似。
- 磁盘占用率,通过磁盘剩余空间和磁盘总空间可以计算出,(测试时计算发现输出为0,因为除法保留整数,实际值是0.9左右),通过awk保留两位小数输出。
- cpu总核数,查看文件/prc/cpuinfo,通过awk工具,以”:”为分隔符,查找core这条记录并执行累加第2列,执行完后打印结果
检测httpd进程数,确保httpd处于稳定运行状态
#!/bin/bashfunction check_httpd_process_number(){httpd_process_num=`ps -ef|grep httpd|wc -l`if [ $httpd_process_num -ge 50 ];thensystemctl restatrt httpd &> /dev/null# 如果重启失败,尝试重启apache服务5次if [$? -ne 0];thennum_httpd_restart=0while true;dolet num_httpd_restart++systemctl restart httpd &> /dev/null[$? -eq 0] && break[num_httpd_restart -eq 5] && breakdoneelseecho "重启一次就成功了" && return 0fi# 判断apache重启是否成功了systemctl status httpd &> /dev/null[$? -ne 0] && echo"apache启动失败,向管理员发送告警" && return 1sleep 60# 判断apache重启后是否还是异常if [$httpd_process_num -ge 50];thenecho "apache重启后进程数异常,向管理员发送告警" && return 1elsereturn 0fielseecho "httpd进程数为${httpd_process_num},小于50"sleep 10return 0fi}# 每10秒执行一次函数,检测httpd进程数是否正常,return 1推出检测while true;docheck_httpd_process_number[$? -eq 1] && exitdone
统计两个目录下相同文件以及不同文件,通过md5散列值的方式进行比较
#!/bin/bash# server1:192.168.80.10:/test/ server2:192.168.80.20:/root/demo/# 输出相同的文件、各自不同的文件,md5仅校验文件内容,不比对文件名、修改时间等属性#server1_ip=192.168.80.10dir1=/test/echo "==========server1 md5=========="index1=0for i in `ls $dir1`;domd5=`md5sum $dir1$i | awk '{print $1}'`arr1[$index]=$md5:$iecho ${arr1[$index]}let index1++done#server2_ip=192.168.80.20dir2=/root/demo/echo "==========server2 md5=========="index2=0for i in `ls $dir1`;domd5=`md5sum $dir2$i awk '{print $1}'`arr2[$index]=$md5:$iecho ${arr2[$index]}let index2++doneecho "==========server1上的文件=========="for i in ${arr1[@]};doserver1_md5=`echo $i | awk -F: '{print $1}'`server1_filename=`echo $i | awk -F: '{print $2}'`tmp_same_num=0for j in ${arr2[@]};doserver2_md5=`echo $i | awk -F: '{print $1}'`server2_filename=`echo $i | awk -F: '{print $2}'`if [server1_md5 == server2_md5];thenlet tmp_same_num++echo "相同文件:$dir1${server1_filename}" && breakfidoneif [tmp_same_num -eq 0];thenecho "server1上的独立文件:$dir1${server1_filename}"fidone

若有收获,就点个赞吧
0 人点赞
