kubernetes是对容器进行编排(orchestration)的工具,它支持自动化部署、应用容器化管理。在生产环境中部署应用程序时通常要部署多个实例,以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
- 特点
- 可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)
- 可扩展: 模块化,插件化,可挂载,可组合
- 自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展
coreos以及容器网络模型介绍
为什么要用coreos
Coreos在内存的使用量上比传统Linux少35%左右,它是为容器l器量身定做的,系统自带容器引擎docker、rkt,启动非常快。
Coreos有9个磁盘分区,文件系统分区占两个,每次从其中一个系统分区启动,更新的内容会被写入另一个系统分区,下次运行新的系统分区,可以定时更新防止漏洞。
![N_IM3VDU`$Z9$U{X~1}3FT.png
新的容器引擎rkt
rkt是一个运行容器的引擎,作用和Docker基本一致,但是它的一些安全和性能特性非常有趣。
特性:
- Pod内置—rkt运行的最小单元是pod
- 资源—使用更少的资源来运行rkt引擎
- 安全—支持虚拟机级别的安全机制(和kvm集成)、支持selinux等,在启动容器时不需要root权限来运行。
rkt vs Docker![~EI2]T3L)S~70Z)Z6K3Z9LK.png](/uploads/projects/u427629@ge071f/b7a1967932c349290a1512c645ba538f.png)
容器的网络模型CNM、CNI
k8s对容器编排的最终目的是要让容器对外提供服务,要对外提供服务,网络就是必不可少的,所以k8s依赖于容器的网络。
CNM—container network model是Docker发明的容器的网络模型,libnetwork就是对这个模型的一种具体实现,他可以和很多项目或插件集成,实现对网络的流量转发和管理。![Z_L~%Z}2QG(CLD_Y2]KY@XF.png](/uploads/projects/u427629@ge071f/a5d79c192b30fe3cb39961f7fd58a931.png)
CNI—container network interface是来自于coreos社区的规范或者说模型,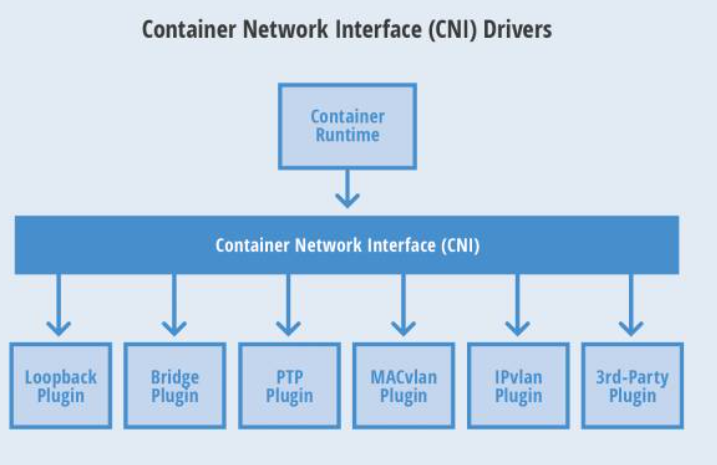
不管哪种网络模型都支持以下网络模式:
- host mode — 主机模式容器,直接使用主机的网络,简单讲进入到容器通过ip a命令查看到的是外面主机的网络信息,这种模式基本不用了。
- bridge mode — NAT模式,所有容器出去的流量和返回的流量都经过NAT(SNAT和DNAT),但是从主机外部无法访问到容器的ip地址和端口,只能访问到主机的ip地址和映射端口,除非设置iptables规则。
- overlay mode — 主要用于多个swarm和容器之间的通信
- macvlan mode — 直接为容器的网卡绑定ip地址,有点像虚拟化中的bridge模式,容器直接拿到主机网段的地址并且有mac地址,就等于在主机的网络中多了一台物理设备,这一般是使用在对网络性能高的情况下。
- plugin mode — 插件模式也是需要主要关注的模式,容器的网络可以通过各种第三方插件集成到容器中,比如flannel、cailco、ovs等。他们都是根据docker的网络模型CNM、CNI来构建的。
Kubernetes整体架构
重要概念
Pod — 是K8s中的最小单元,一个pod是由一个或多个容器组成的,在一个pod中的容器通常用共享存储或者localhost来互相访问,启动这些容器的镜像通常是一个定制过的微服务(一个容器一个服务)。一个标准的pod通常由2个容器组合而成,一个负责提供服务,另一个收集日志,这样的模式叫side car。
Node — 节点是运行Pod的一个载体,可以是物理服务器,也可以是云平台或VMware上的虚拟机。
Namespace — 概念有点像云平台中的租户,把资源通过namespace隔离开,默认的namespace有default和kube-system等等。
kube-apiserver — 整个k8s的心脏,负责处理所有的请求,并返回http请求给发送请求方,它暴露出所有的API接口给给其他组件或第三方调用,它默认运行在master节点上,是以一个或多个pod的形式出现的。
etcd — k8s使用多个数据库,主要存放整个k8s集群的信息,包括service account、node等,它默认运行在master节点上,是以一个或多个pod的形式出现的。
kube-scheduler — 用来调度pod到工作节点的算法,主要通过一定算法算出用户启动的pod应该在那些工作节点上 ,将结果返回给kube-apiserver,它默认运行在master节点上,是以一个或多个pod的形式出现的。
kube-controller-manager — 负责启动controller,这些controller就是一个Linux进程。
Node-controller ,负责检测节点状态是否运行。
Replication Controller,负责保证用户启动的pod实例数量是用户要求的数量,如果少于用户要求的数量,就会创建pod直到满足用户要求的数量。
Endpoint Controller,服务器端点控制器,负责提供pod的ip地址给到service
Service account & Tocken Controllers 负责创建一些默认账号和token的工作
kubelet — 运行在所有节点上,暴露出API等待kube-apiserver的请求,比如修改Pod、创建Pod和删除Pod等,最直接的行为是管理节点上 容器引擎中相对应的容器。
kube-proxy — 运行在所有节点上,当用户将pod对外发布为服务的时候,根据网络配置在工作节点上建立vip并绑定pod的ip地址。
kube-dns — 为k8s集群提供dns域名解析,在k8s中所有pod都会分配自己的dns域名,kubelet会保证pod中的容器都是以kube-dns的地址做域名解析的。
Dashboard(Web UI) — 提供web界面的方式让用户管理k8s

若有收获,就点个赞吧
0 人点赞

{kind=link}