无监督学习
K-means

随机初始化聚类中心。内循环:
- 计算m个样本到聚类中心的距离,选取距离最小的那个中心作为该样本的类别
- 计算聚类中心所属样本的均值。更新聚类中心
如果一个类中没有点,一般做法是删除这个聚类中心。如果一定要k个类,那么再次随机初始化这个类中心。
优化目标

随机初始化
一般来说 随机初始化选择的聚类中心就是从样本点中选取k个。
为了保证不陷入局部最优,应当多次随机初始化,多次运行K-Means,然后求这些次数中的代价函数,最小的就是最好的结果。
如果聚类数在2-10之间,那么多次随机初始化效果不错。随着聚类数目的增加,多次随机初始化可能效果并不是很好。
选择聚类的数量
肘部法则可以参考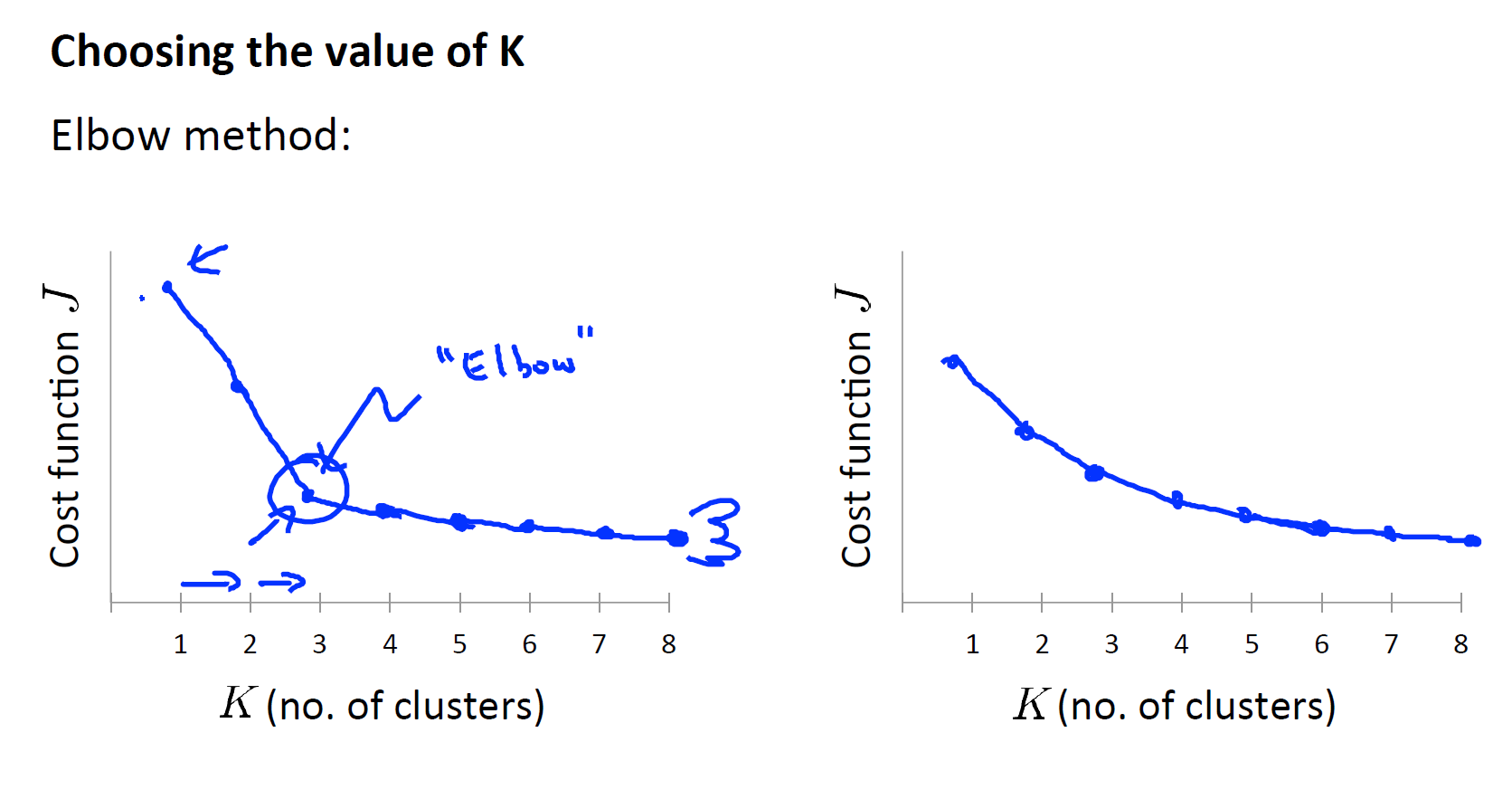
但是大概率是右边那张图
一般来说还是询问自己运行k-means的目的是什么,根据下游需求手动决定聚类的数量。

若有收获,就点个赞吧
0 人点赞
