学习大规模数据集中产生的问题

随机梯度下降


梯度更新每次只在一个样本上面(数据集需要预先打乱)。外层重复次数一般在1-10次
Mini-batch梯度下降

随机梯度下降中存在的收敛问题
计算单个样本在使用这个样本更新参数之前的损失。以几千个样本均值为一个数据点。
第一种情况可以加大产生数据点的平均样本数,平均的样本数量越大,曲线越光滑。
第三幅图对应,有可能在下降,但是产生数据点的平均样本数少,所以不明显。
第四种算法在发散,使用更小的学习率,或者调整特征。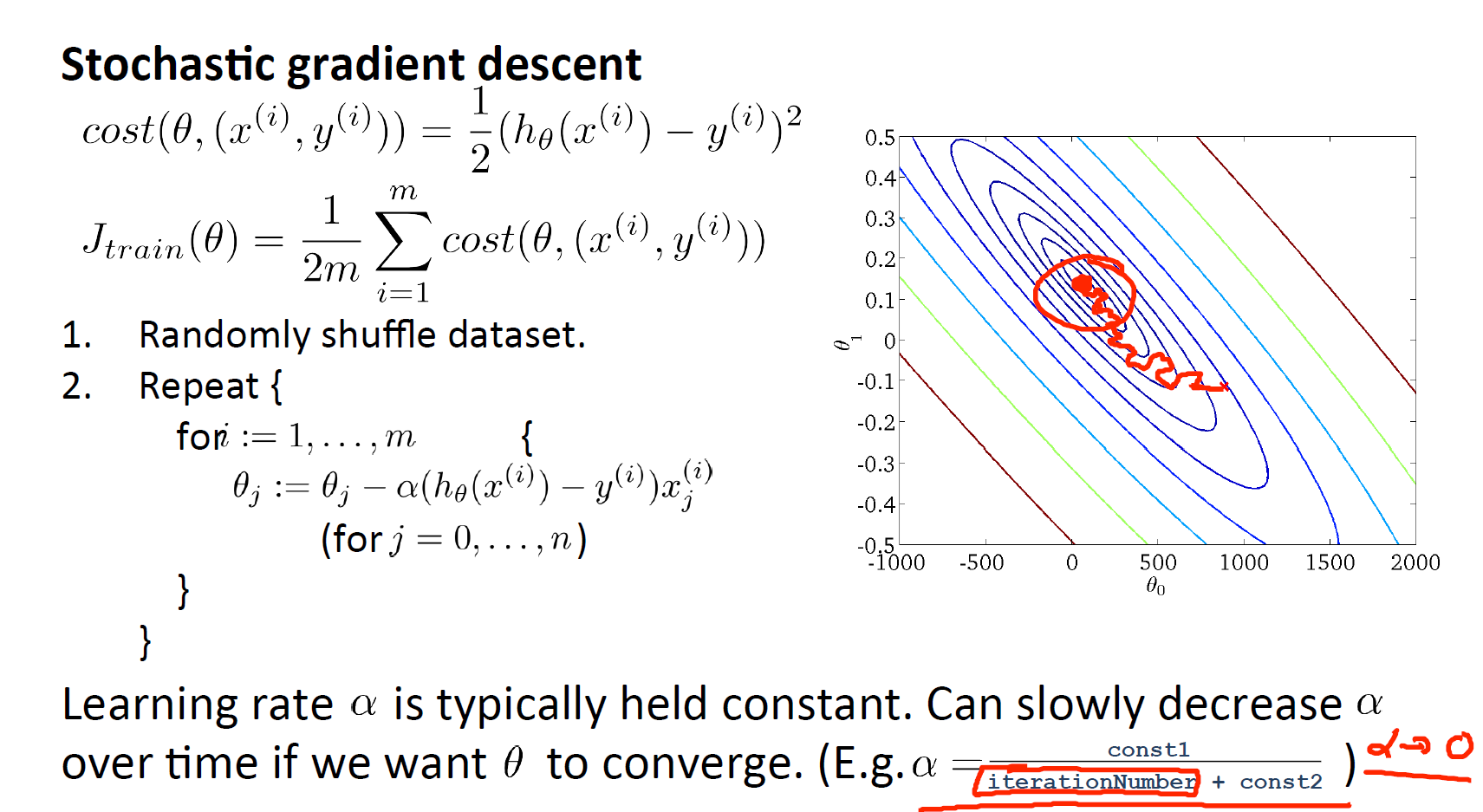
也可以调整学习率随时间变化而减小。但是需要确定额外参数,用的不多。
在线学习

Map-Reduce

将耗时的求和部分分散到多台机器或者核心上。hadoop可以如此实现。

若有收获,就点个赞吧
0 人点赞
