设计模式的六大原则
- 开闭原则:对拓展开放,对修改关闭;多使用抽象类和接口
- 里氏代换原则:基类可以被子类替换;使用抽象类继承,不要使用具体类继承
- 依赖转换原则:要依赖多个抽象,不要依赖具体;针对接口编程,不针对实现编程
- 接口隔离原则:使用多个隔离的接口,比使用单个接口好;建立最小接口
- 迪米特法则:一个实体尽可能少的与其他实体发生相互作用;通过中间类建立联系
- 合成复用法则:尽量使用合成/聚合,而不是使用继承;尽量使用合成/聚合,而不是使用继承
总原则:开闭原则,就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有代码而是要扩展原有代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类等
- 单一职责原则
不要存在多于一个导致类变更的原因,也就是说每个类应该实现单一的职责,如若不然,就应该把类拆分;
- 里氏替换原则(Liskov Substitution Principle)
里氏替换原则面向对象设计的基本原则之一。里氏替换原则中说,任何基类可以出现的地方,子类一定可出现。LSP是继承复用的基石,只有衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏替换原则是对”开-闭”原则的补充。实现”开-闭”原则的关键步骤就是抽象化。基类与子类的继承关系就是抽象化的具体实现,所以里氏替换原则是对实现抽象化的具体步骤规范。历史替换原则中,子类对父类的方法尽量不要重写和重载。因为父类代表了定义好的结构,通过这个规范的接口与外界交互,子类不应该随便破坏它。
- 依赖装换原则
这个是开闭原则的基础,具体内容是:面向接口编程,依赖抽象而不依赖具体。写代码时用到具体类时,而与具体类的上层接口交互。
- 接口隔离原则
这个原则的意思是:每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分。使用多个隔离的接口,比使用单个接口要好。
- 迪米特法则(最少知道原则)
一个类对自己依赖的类知道的越少越好。也就是说无论被依赖的类多么复杂,都应该将逻辑封装到方法的内部,通过public方法提供给外部。这样当被依赖的类变化时,才能最小的影响该类。
- 合成复用原则
设计模式分类
总体分为三大类:
- 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者、原型模式。
- 结构型模式,共七种:适配器模式、装配器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
- 行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
- 另外还有两类:并发型模式和线程池模式。
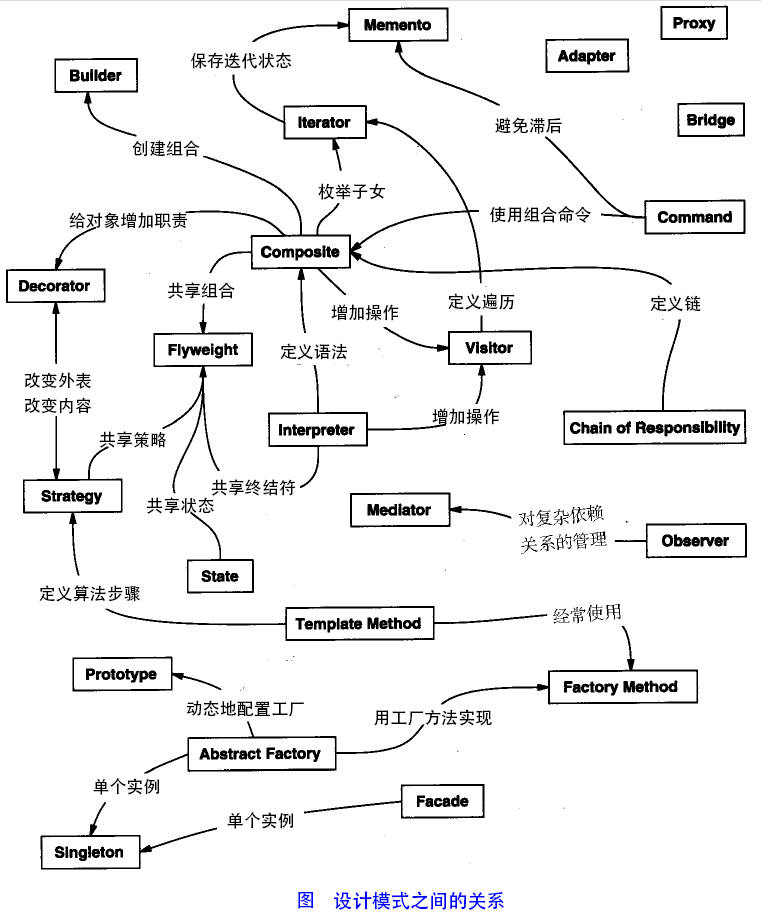
Java的二十三种设计模式
创建型模式
简单工厂模式
简单工厂模式分为三种:
- 普通工厂模式
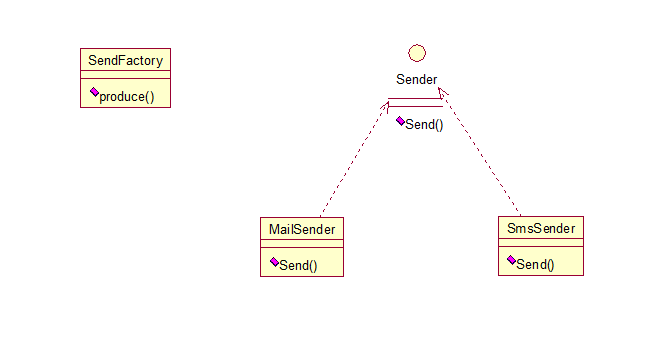
就是建立一个工厂类,对实现了同一个接口的一些类进行实例创建。关系图如上
首先,创建二者的共同接口:
public interface Sender {public void Send();}
其次,创建实现类
public class MailSender implements Sender {@Overridepublic void Send() {}}
- 多个方法
- 多个静态类
单例模式
单例模式做到正确且延迟加载的写法有三种:**
- 使用volatile修饰变量并且双重校验的写法来实现;
- 使用静态内部类来实现(类A有一个静态内部类B,类B有一个静态变量instance,类A的getInstance()方法会返回类B的静态变量instance,因为只有调用getInstance()方法时才会加载静态内部类B,这种写法的缺点是不能传参)。
- 使用枚举来实现。
第一种 不加锁(裸奔写法)
在多线程执行时,可能会在instance完成初始化之前,其他线程判断instance为null,从而也执行第二步的代码,导致初始化失败。public class UnsafeLazyInitialization {private static Instance instance;public static Instance getInstance() {if (instance == null) //1instance = new Instance(); //2}return instance;}
第二种 对方法加synchronize锁(俗称的懒汉模式)
初始化完成以后,每次调用getInstance()方法都需要获取同步锁,导致不必要的开销。public class Singleton {private static Singleton instance;public synchronized static Singleton getInstance() {if (instance == null)instance = new Instance();return instance;}}
第三种 使用静态变量(俗称饿汉模式)
这种方式的缺点在于不能做到延时加载,第一次调用getInstance()方法之前,如果Singleton类被使用到,那么就会对instance变量初始化。public class Singleton {private static Singleton instance = new Singleton();public static Singleton getInstance() {return instance;}}
第四种 使用双重检查锁定
instance = new Singleton();public class Singleton {private static Singleton instance;public static Singleton getInstance() {if (instance == null) {synchronized (Singleton.class) {if (instance == null) { //双重检查存在的意义在于可能会有多个线程进入第一个判断,然后竞争同步锁,线程A得到了同步锁,创建了一个Singleton实例,赋值给instance,然后释放同步锁,此时线程B获得同步锁,又会创建一个Singleton实例,造成初始化覆盖。instance = new Singleton();}}}return instance;}}
这句代码在执行时会分解为三个步骤:
- 为对象分配内存空间;
- 执行初始化的代码;
- 将内存分配好的内存地址设置给instance引用。
但是编译器会对指令进行重排,只能保证单线程执行时结果不会变化,也就是可能第三步会在第二步之前执行,某个线程刚好执行完第三步,正在执行第二步时此时如果有线程访问其他线程B进入if(instance == null)判断,会发现instance不为null,然后将instance返回,但是实际上instance还没有完成初始化,线程B会访问到一个未初始化完成的instance对象。所以需要像第五种解法一样使用volatile修饰变量,防止重排序。
第五种 基于volatile的双重检查锁定的解决方案
public class Singleton {private volatile static Singleton instance;public static Singleton getInstance() {if (instance == null) {synchronized (Singleton.class) {if (instance == null)//双重检查存在的意义在于可能会有多个线程进入第一个判断,然后竞争同步锁,线程A得到了同步锁,创建了一个Singleton实例,赋值给instance,然后释放同步锁,此时线程B获得同步锁,又会创建一个Singleton实例,造成初始化覆盖。instance = new Singleton();}}return instance;}}
volatile可以保证变量的内存可见性及防止指令重排:
volatile修饰的变量在编译后,会多出一个lock前缀指令,lock前缀指令相当于一个内存屏障(内存栅栏),有三个作用:
- 确保指令重排序时,内存屏障前的指令不会排到后面去,内存屏障后的指令不会排到前面去;
- 强制对变量在线程工作内存中的修改操作立即写入到物理内存;
- 如果是写操作,会导致其他CPU中对这个变量的缓存失效,强制其他CPU中的线程在获取变量时从物理内存中获取更新后的值。
所以使用volatile修饰后不会出现第三种写法中,由于指令重排序导致的问题。
第六种 使用静态内部类来实现
class Test {public static Signleton getInstance() {return Signleton.instance ; // 只有调用getInstance()方法时,才会引用到静态内部类Signleton,从而会触发Signleton类的instance变量的初始化,以此实现懒加载的目的。}private static class Signleton {private static Signleton instance = new Signleton();}}
因为JVM底层通过加锁实现,保证一个类只会被加载一次,多个线程在对类进行初始化时,只有一个线程会获得锁,然后对类进行初始化,其他线程会阻塞等待。所以可以使用上面的代码来保证instance只会被初始化一次,这种写法的问题在于创建单例时不能传参。
第七种 使用枚举来实现单例
public enum Singleton {//每个元素就是一个单例INSTANCE;//自定义的一些方法public void method(){}}
这种写法比较简洁,但不太方便阅读和理解,所以实际开发中应用的比较少,而且由于枚举是不能通过反射来创建实例的(反射方法newInstance中判断是枚举类型,会抛出IllegalArgumentException异常),所以可以防止反射。而且由于枚举类型的反序列化是通过 java.lang.Enum的valueOf方法实现的,不能自定义序列化方法,可以通过序列化来创建多个单例。
如何解决序列化时可以创建出单例对象的问题?
如果将单例对象序列化成字节序列后,然后再反序列化成对象,那么就可以创建出一个新的单例对象,从而导致单例不唯一,避免发生这种情况的解决方案是在单例中实现readResolve()方法。
public class Singleton implements java.io.Serializable {private Object readResolve() {return INSTANCE;}}
通过实现readResolve方法,ObjectInputStream实例对象在调用readResolve方法进行反序列化时,就会判断相应的类是否实现了readResolve方法,如果实现了,就会调用方法返回一个对象作为反序列化的结果,而不是去创建一个新的对象。
结构型模式
适配器模式
适配器模式主要是解决由于接口不能兼容而导致类无法使用的问题,这在处理遗留代码以及集成第三方框架的时候使用的比较多。其核心原理为:通过组合的方法,将需要适配的类转换成使用者能够使用的接口。
适配器模式的类图如下所示: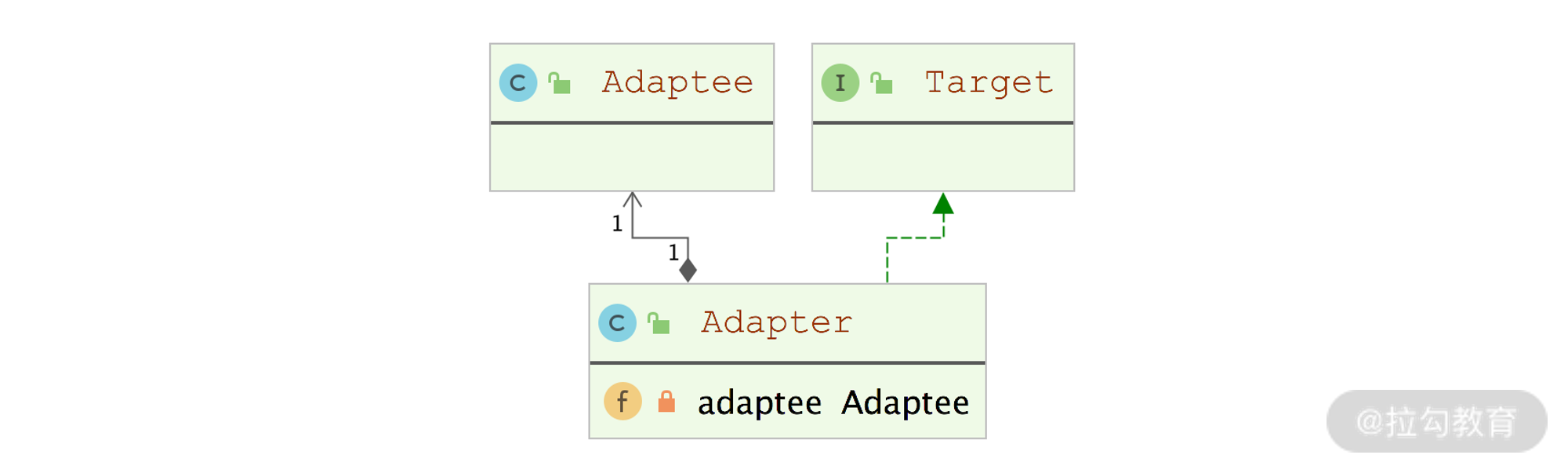
在类图中,可以看到适配器模式涉及的三个核心角色:
- 目标接口(target):使用者能够直接使用的接口。以处理遗留代码为例,target就是重新定义的业务接口。
- 需要适配的类/要使用的实现类(Adaptee):定义了真正要执行的业务逻辑,但是其接口不能被使用者直接使用。这里依然以处理遗留代码为例,Adaptee就是遗留业务实现,由于编写Adaptee的时候还没有定义target接口,所以Adaptee无法实现target接口。
- 适配器(Adapter):在实现target接口的同时,维护了一个指向Adaptee对象的引用。Adapter底层会依赖Adaptee的逻辑来实现target接口的功能,这样就能够复用Adaptee类中的遗留逻辑来完成业务。
适配器模式带来的最大好处就是复用已有的逻辑,避免直接去修改Adaptee实现的接口,这符合开放封闭原则(程序对拓展开放,对修改关闭)。
代理模式
静态代理模式
经典的静态代理模式,其类图如下:
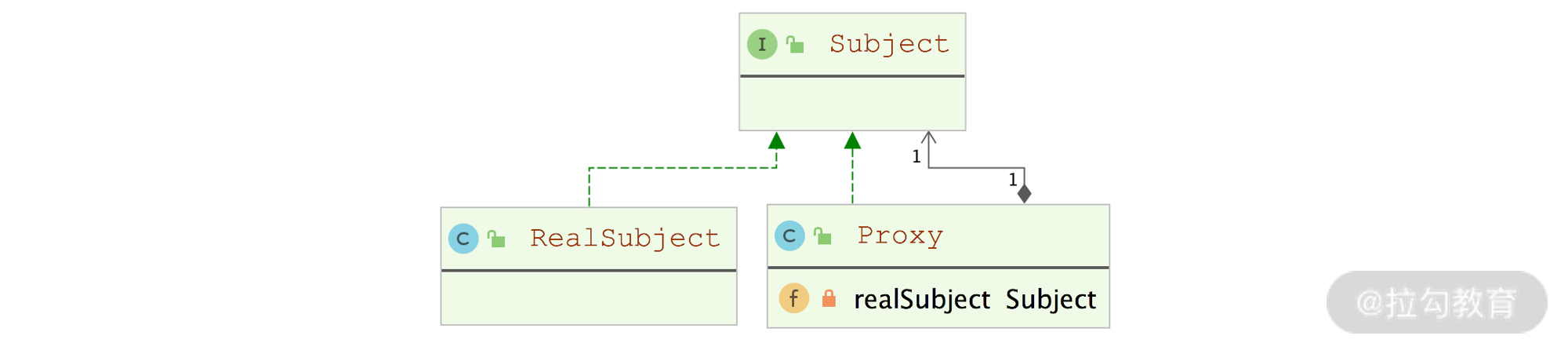
从该类图中,可以看到与代理模式相关的三个核心角色:
- Subject:程序中的业务接口,定义了相关的业务方法;
- RealSubject:实现了Subject接口的业务实现类,其实现中完成了真正的业务逻辑;
- Proxy:代理类,实现了Subject接口,其中会持有一个Subject类型的字段,指向一个RealSubject对象
在使用的时候,会将RealSubject对象封装到Proxy对象中,然后访问Proxy的相关方法,而不是直接访问RealSubject对象。在Proxy的方法实现中,不仅会调用RealSubject对象的相应方法完成业务逻辑,还会在RealSubject方法执行前后进行预处理和后置处理。
通过对代理模式的描述可知,Proxy能够控制使用方对RealSubject对象的访问,或者执行业务逻辑之前执行统一的预处理逻辑,在执行业务逻辑之后执行统一的后置处理逻辑。
代理模式处理实现访问控制以外,还能用于实现延迟加载。延迟加载可以有效的避免数据库资源浪费,其主要原理是:用户在访问数据库时,会立刻拿到一个代理对象,此时并没有任何SQL到数据库中查询数据,代理对象中自然也不会包含任何真正的有效数据;当用户真正需要使用数据时,会访问代理对象,此时会由代理对象去执行SQL,完成数据库的查询。
JDK动态代理
JDK动态代理的核心是InvocationHandler接口。
import java.lang.reflect.InvocationHandler;import java.lang.reflect.Method;import java.lang.reflect.Proxy;public class DemoInvocationHandler implements InvocationHandler {//真正的业务对象;也就是RealSubjectprivate Object target;public DemoInvocationHandler(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {//在执行业务逻辑之前的预处理逻辑Object result = method.invoke(target,args);//在执行业务逻辑之后的后置处理逻辑return result;}public Object getProxy(){return Proxy.newProxyInstance(Thread.currentThread().getContextClassLoader(),target.getClass().getInterfaces(),this);}}
JDK动态代理的入口方法是Proxy.newProxyInstance(),该静态方法有三个参数:
- loader(ClassLoader 类型):加载动态生成的代理类的类加载器;
- interfaces(Class[] 类型):业务类实现的接口;
- h(InvocationHandler 类型):自定义的InvocationHandler对象。
JDK动态代理的原理:动态创建代理类,然后通过指定类加载器进行加载。在创建代理对象时,需要将InvocationHandler对象作为构造参数传入;当调用代理对象是,会调用InvocationHandler.invoke()方法,从而执行代理逻辑,最终调用真正业务对象的相应方法。
装饰器模式
装饰器模式就是一种通过组合方式实现扩展的设计模式,它可以完美的解决上述功能增强的问题。装饰器的核心思想是为已有实现类创建多个包装类,由这些新增的包装类完成新需求的扩展。
装饰器模式使用的是组合方式,相较于继承这种静态的扩展方式,装饰器模式可以在运行时根据系统状态,动态决定为一个实现类添加那些扩展功能。
装饰器模式的核心类图,如下: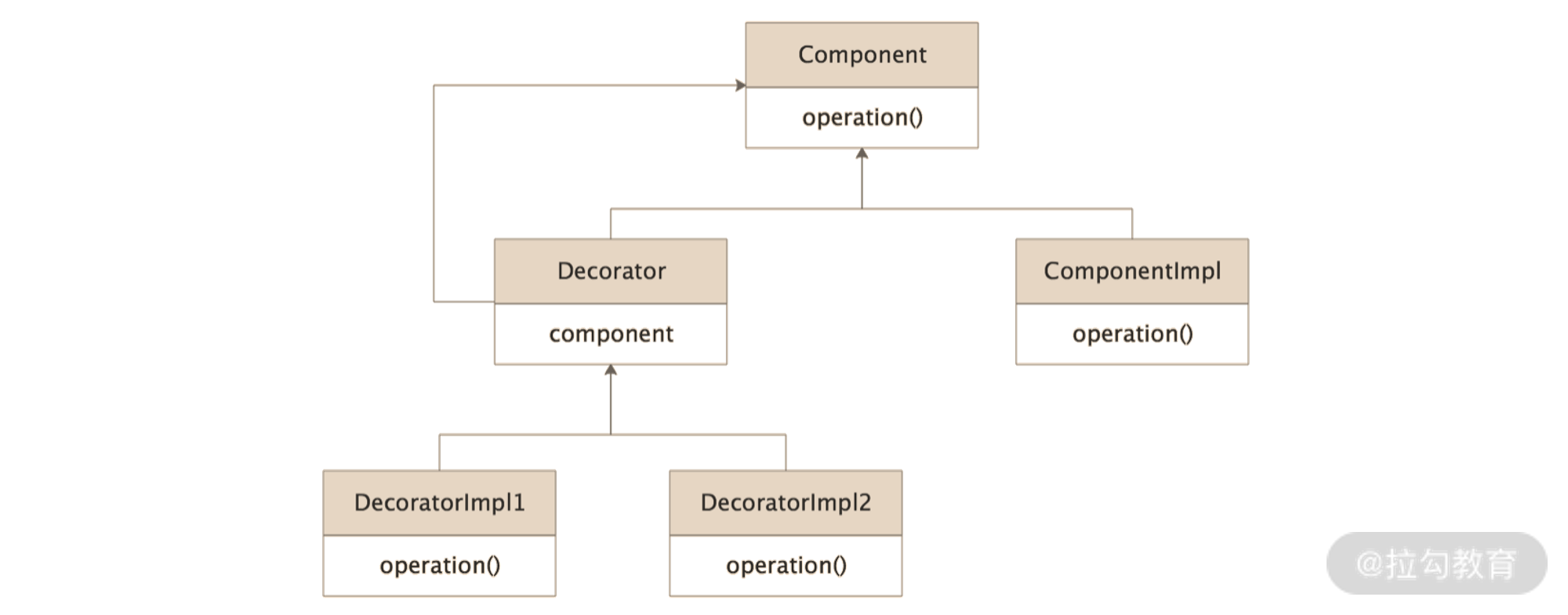
装饰器模式类图
装饰器模式核心类有以下四个:
- Component接口:已有的业务接口,是整个功能的核心抽象。定义了Decorator和ComponentImpl这些实现类的核心行为。JDK中的IO流体系就使用了装饰器模式,其中InputStream接口就是一个Component接口的角色;
- ComponentImpl实现类:实现了上面介绍的Component接口,其中实现了Component接口最基础、最核心的功能,也就是被装饰的原始的基础类。在JDK IO流体系之中的FileInputStream就是ComponentImpl的角色,它实现了读取文件的基本能力;
- Decorator抽象类:所有装饰器的父类,实现Component接口,其核心不是提供新的拓展能力,而是封装一个Component类型的字段,也是被装饰的目标对象。需要注意的是,这个被装饰的对象可以是ComponentImpl对象,也可以是Decorator实现类的对象,之所以这么设计,就是为了实现下图的装饰器嵌套。这里的DecoratorImpl1装饰了DecoratorImpl2,DecoratorImpl2装饰了ComponentImpl,经过了这一系列装饰之后得到的Component对象,除了具有ComponentImpl的基础能力之外,还拥有了DecoratorImpl1和DecoratorImpl2的拓展能力。JDK IO流体系中的FilterInputStream就是Decorator角色。

Decorator与Component的引用关系
- DecoratorImpl1、DecoratorImpl2:Decorator的具体实现类,它们的核心就是在被装饰对象的基础之上添加新的拓展能力。在JDK IO流体系中的BufferedInputStream就扮演了DecoratorImpl的角色,它在原有的InputStream基础上,添加了一个byte[] 缓冲区,提高了更加高效的读文件操作。

若有收获,就点个赞吧
0 人点赞
