标签: 微服务 prometheus+grafana监控 docker 数据库
微服务基础服务
MySQL
主从复制
主库安装
- 创建配置文件
创建目录
mkdir -p /opt/mysql/master/conf
创建my.cnf文件
vim /opt/mysql/master/conf/my.cnf内容如下
default-character-set=utf8[mysql]default-character-set=utf8[mysqld]collation-server = utf8_unicode_ciinit-connect='SET NAMES utf8'character-set-server = utf8pid-file = /var/run/mysqld/mysqld.pidsocket = /var/run/mysqld/mysqld.sockdatadir = /var/lib/mysqlsecure-file-priv= NULLsymbolic-links=0skip-character-set-client-handshakebinlog_format=ROWbinlog_rows_query_log_events=1server_id = 1log-bin= mysql-bingtid_mode=onenforce_gtid_consistency=ONmaster_info_repository=TABLErelay_log_info_repository=TABLErelay_log_recovery=ONsync_master_info=1binlog_checksum=CRC32slave-parallel-type=LOGICAL_CLOCKslave_parallel_workers=4binlog_transaction_dependency_tracking=WRITESET_SESSIONtransaction_write_set_extraction=XXHASH64transaction-isolation=READ-COMMITTEDread-only=0replicate-ignore-db=mysqlreplicate-ignore-db=sysreplicate-ignore-db=information_schemareplicate-ignore-db=performance_schemaexpire_logs_days=30max_connections=3600# Custom config should go here!includedir /etc/mysql/conf.d/
skip-character-set-client-handshake:忽略应用程序想要设置的其他字符集binlog_format:为设置binlog格式binlog_rows_query_log_events:在row模式下开启该参数,将把sql语句打印到binlog日志里面,默认是0(off);server_id:这个的值必需所有mysql实例都不重复log-bin:binlog的名称gtid_mode:开启GTID,用来代替classic的复制方法enforce_gtid_consistency:开启gtid的一些安全限制,阻止不安全的语句执行master_info_repository=table和relay_log_info_repository=table:master.info和relay.info保存在表中relay_log_recovery:当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性sync_master_info:每个事务都会刷新master.infobinlog_checksum:默认为NONE, 表示在图1的箭头1 不生成checksum, 这样就可以兼容旧版本的mysql。此外,就只能设置为CRC32了slave-parallel-type:DATABASE为默认值,基于库的并行复制方式;LOGICAL_CLOCK基于组提交的并行复制方式slave_parallel_workers:设置多少个SQL Thread(coordinator线程)来进行并行复制binlog_transaction_dependency_tracking:控制是否使用WRITESET策略,WRITESET_SESSION是在写集合的基础上增加约束,保证按照前后顺序执行transaction_write_set_extraction:控制检测事务依赖关系时采用的HASH算法transaction-isolation:事务隔离级别read-only:是否只读,0为否,1为是replicate-ignore-db:配置忽略同步的数据库expire_logs_days:binlog日志过期时间,默认不过期max_connections:mysql最大连接数
- 启动主库
docker run -d \-p 3306:3306 \--name mysql-nacos-master \-v /opt/mysql/master/conf/my.cnf:/etc/mysql/my.cnf \-v /opt/mysql/master/data/mysql:/var/lib/mysql \-v /opt/mysql/master/log:/opt/mysql/log \-e MYSQL_ROOT_PASSWORD=1q2w3e4r \mysql-5.7:5.7
MYSQL_ROOT_PASSWORD=1q2w3e4r
- 主库创建用于同步的账号
- 登录进主库
- 进去docker容器内
docker exec -it mysql-nacos-master bash
- 登录mysql数据库
mysql -uroot -p1q2w3e4r
- 创建backup账号
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
从库安装
进入从库的服务器执行以下操作,建议是不同于主库的服务器,如果服务器相同需要修改3306端口为其他的值
- 创建配置文件
创建目录
mkdir -p /opt/mysql/slave/conf
创建my.cnf文件
vim /opt/mysql/slave/conf/my.cnf内容如下
[client]default-character-set=utf8[mysql]default-character-set=utf8[mysqld]collation-server = utf8_unicode_ciinit-connect='SET NAMES utf8'character-set-server = utf8pid-file = /var/run/mysqld/mysqld.pidsocket = /var/run/mysqld/mysqld.sockdatadir = /var/lib/mysqlsecure-file-priv= NULLsymbolic-links=0skip-character-set-client-handshakebinlog_format=ROWbinlog_rows_query_log_events=1server_id = 224log-bin= mysql-bingtid_mode=onenforce_gtid_consistency=ONmaster_info_repository=TABLErelay_log_info_repository=TABLErelay_log_recovery=ONsync_master_info=1binlog_checksum=CRC32slave-parallel-type=LOGICAL_CLOCKslave_parallel_workers=4binlog_transaction_dependency_tracking=WRITESET_SESSIONtransaction_write_set_extraction=XXHASH64transaction-isolation=READ-COMMITTEDread-only=1replicate-ignore-db=mysqlreplicate-ignore-db=sysreplicate-ignore-db=information_schemareplicate-ignore-db=performance_schemaexpire_logs_days=30max_connections=3600# Custom config should go here!includedir /etc/mysql/conf.d/
不同于主库的配置如下server_id:设为非1read-only:设为只读
- 启动从库
docker run -d \-p 3306:3306 \--name mysql-nacos-slave\-v /opt/mysql/slave/conf/my.cnf:/etc/mysql/my.cnf \-v /opt/mysql/slave/data/mysql:/var/lib/mysql \-v /opt/mysql/slave/log:/opt/mysql/log \-e MYSQL_ROOT_PASSWORD=1q2w3e4r \mysql-5.7:5.7
- 关联主库
- 登录进从库
- 进去docker容器内
docker exec -it mysql-nacos-slave bash
- 登录mysql数据库
mysql -uroot -p1q2w3e4r
- 执行关联master语句
change master to master_host='192.168.28.130',master_port=3306,master_user='backup',master_password='123456',MASTER_AUTO_POSITION=1;master_host:为主库ipmaster_port:主库端口master_user:主库用于同步的帐号master_password:主库用于同步的帐号密码master_auto_position:slave连接master将使用基于GTID的复制协议
- 启动slave
start slave;
- 查看slave的状态
show slave status\G
- 创建从库的普通用户
read_only=1只读模式,可以限定普通用户进行数据修改的操作,但不会限定具有super权限的用户(如超级管理员root用户)的数据修改操作,所以需要另外创建普通账号来操作从库。
GRANT select,insert,update,delete,create,drop,alter ON *.* to 'slave'@'%' identified by '1q2w3e4r';
主库查看同步信息
- 登录主库
- 查看binlog线程,执行以下语句查看正在执行的线程
show processlist;
- 查看所有从库信息
show slave hosts;
Redis
主从复制
概述
主节点端口为16379,从节点端口为16380
主节点配置
vim /opt/redis/conf/16379.conf
bind 0.0.0.0protected-mode yesport 16379tcp-backlog 511timeout 0tcp-keepalive 300daemonize nosupervised nopidfile /var/run/redis_16379.pidloglevel noticelogfile "16379.log"dbfilename dump-16379.rdbrequirepass 1q2w3e4rmasterauth 1q2w3e4rdatabases 16always-show-logo yessave ""stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdir ./slave-serve-stale-data yesslave-read-only yesrepl-diskless-sync norepl-diskless-sync-delay 5repl-disable-tcp-nodelay noslave-priority 100lazyfree-lazy-eviction nolazyfree-lazy-expire nolazyfree-lazy-server-del noslave-lazy-flush noappendonly yesappendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit slave 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10aof-rewrite-incremental-fsync yes
dbfilename:快照名字requirepass:密码masterauth:主节点密码,主从复制需要save m n:开启RDB快照appendonly:是否开启aofaof-use-rdb-preamble:是否开启混合持久化
主节点启动文件
vim start-16379.sh
PORT=16379docker stop redis-${PORT}docker rm redis-${PORT}docker run --name redis-${PORT} \-p ${PORT}:${PORT} \-v /opt/redis/master/conf/${PORT}.conf:/etc/redis/redis.conf \-v /opt/redis/master/data:/data \-d 10.3.0.171/dao/redis-5.0.2-alpine:5.0.2-alpine \redis-server /etc/redis/redis.conf
从节点配置
vim /opt/redis/conf/16380.conf
bind 0.0.0.0protected-mode yesport 16380tcp-backlog 511timeout 0tcp-keepalive 300daemonize nosupervised nopidfile /var/run/redis_16380.pidloglevel noticelogfile "16380.log"dbfilename dump-16380.rdbslaveof 10.2.10.224 16379requirepass 1q2w3e4rmasterauth 1q2w3e4rdatabases 16always-show-logo yessave ""stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdir ./slave-serve-stale-data yesslave-read-only yesrepl-diskless-sync norepl-diskless-sync-delay 5repl-disable-tcp-nodelay noslave-priority 100lazyfree-lazy-eviction nolazyfree-lazy-expire nolazyfree-lazy-server-del noslave-lazy-flush noappendonly yesappendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit slave 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10aof-rewrite-incremental-fsync yes
slaveof:启用主从模式配置主库ip和端口slave-read-only:从节点是否只读masterauth:设置访问master服务器的密码,如果主节点设置了密码必需添加该参数才能同步数据
从节点启动文件
vim start-16380.sh
PORT=6380docker stop redis-${PORT}docker rm redis-${PORT}docker run --name redis-${PORT} \-p ${PORT}:${PORT} \-v /opt/redis/slave/conf/${PORT}.conf:/etc/redis/redis.conf \-v /opt/redis/slave/data:/data \-d 10.3.0.171/dao/redis-5.0.2-alpine:5.0.2-alpine \redis-server /etc/redis/redis.conf
查看主从节点状态
- 进入主节点容器
docker exec -it redis-16379 bash
- 通过密码登录Redis
redis-cli -a 1q2w3e4r
- 查看主从信息
info replication
数据库之分库分表
分库分表思路
数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
- IO瓶颈
1. 磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
2. 网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。 - CPU瓶颈
1. SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
2. 单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
分库分表
- 水平分库
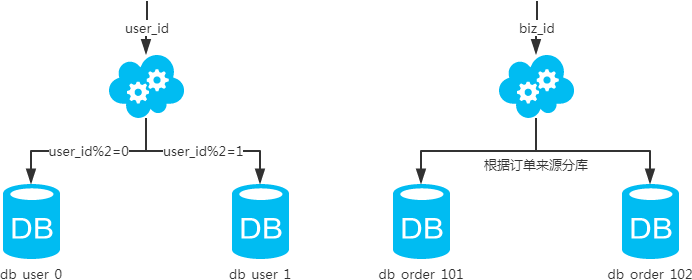
- 概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
- 结果:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
- 场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
- 分析:库多了,io和cpu的压力自然可以成倍缓解。
- 水平分表
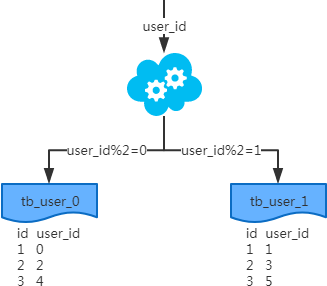
- 概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
- 结果:
- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是全量数据;
- 场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
- 分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
- 垂直分库
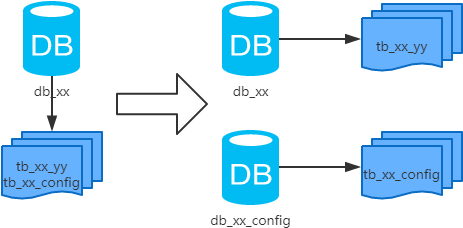
- 概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
- 结果:
- 每个库的结构都不一样;
- 每个库的数据也不一样,没有交集;
- 所有库的并集是全量数据;
- 场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
- 分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
- 垂直分表
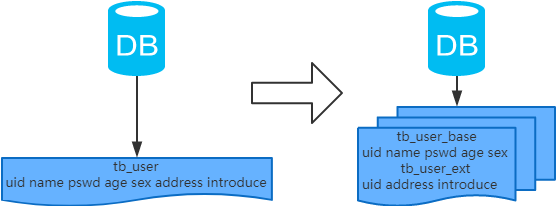
- 概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
- 结果:
- 每个表的结构都不一样;
- 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
- 所有表的并集是全量数据;
- 场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
- 分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
分库分表工具
- sharding-sphere:jar、proxy
- TDDL:jar
- Mycat:proxy
- Atlas:proxy
分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。
分库分表问题
- 非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
1.1. 端上除了partition key只有一个非partition key作为条件查询
- 映射法
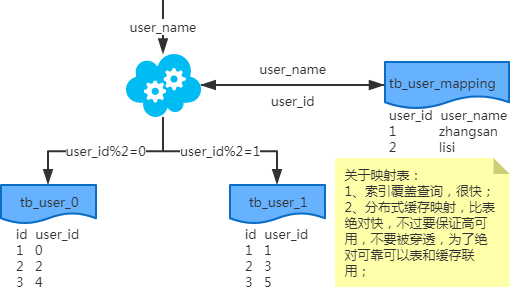
- 基因法
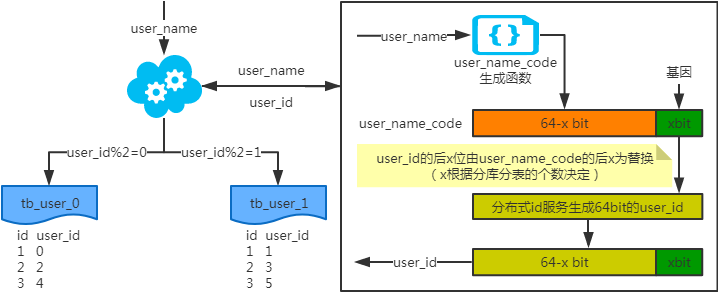
写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,23=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用snowflake算法。
1.2. 端上除了partition key不止一个非partition key作为条件查询
- 映射法
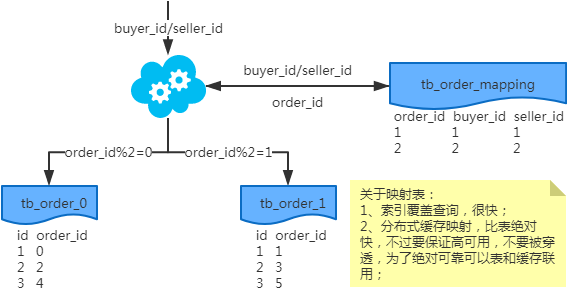
- 冗余法
顾名思义就是同一个表分别用不同的partition key来分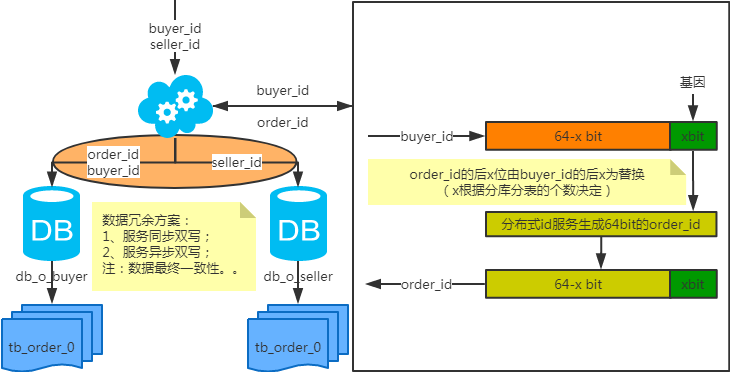
1.3. 后台除了partition key还有各种非partition key组合条件查询
- NoSQL法
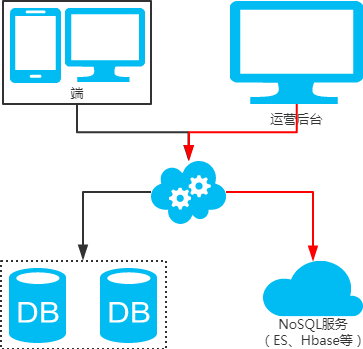
- 冗余法
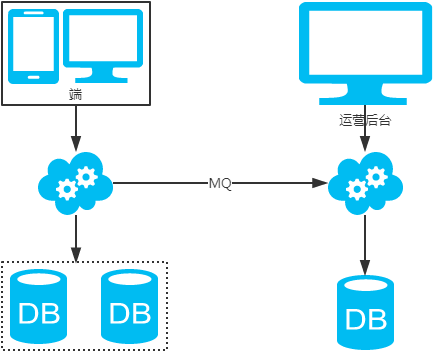
- 非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
用NoSQL法解决(ES、Hive等)
另外这种很多批量分页且条件多样的查询通常为运营端(后台用户)用于查询报表或者运营数据而用的,这类查询计算量大,返回数据量大,对数据库的性能消耗较高,这类业务最好采用前台与后台分离的方案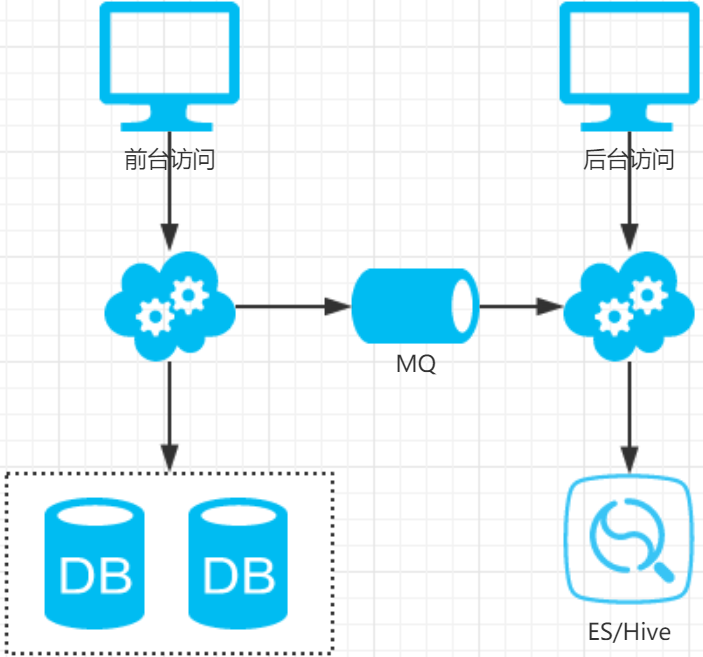
后台业务需求则抽取独立的web/service/db来支持,解除系统之间的耦合,对于业务复杂、并发量低、无需高可用、能接受一定延时的后台业务:
- 可以通过MQ或者线下异步(binlog)同步数据,牺牲一些数据的实时性
- 可以使用更契合大量数据允许接受更高延时的“索引外置”或者“HIVE”的设计方案
- 扩容问题(水平分库分表,拆分策略为常用的hash法)
- 水平扩容表(双写迁移法)
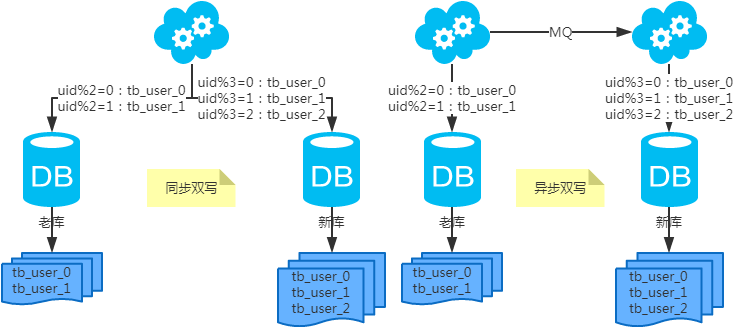
- 将老库中的老数据复制到新库中;
- 应用配置双写,部署;
- 以老库为准校对新库中的老数据;
- 应用去掉双写,部署;
中间件
spring cloud stream消息框架
背景
Spring Cloud Stream 是一个用于构建“基于事件驱动的、与共享消息系统相连接的高度可扩展微服务”的框架,并提供了许多抽象和原语,以简化 Spring 生态系统消息驱动应用程序的开发。 Spring Cloud Stream 应用程序由一个“与中间件无关的核心”组成,应用程序通过由框架注入的输入和输出通道与外部进行通信。通道通过中间件特定的“Binder 实现”连接到外部代理,目前支持 RabbitMQ 和 Apache Kafka。
Spring Cloud Stream 的核心构件是:
- 目标绑定器——提供与外部邮件系统集成的组件。
- 目标绑定——外部消息传递系统和应用程序之间的桥梁,提供消息的“生产者”和“消费者”(由目标绑定器创建)。
- 消息——一种规范化的数据结构,生产者和消费者基于这个数据结构通过外部消息系统与目标绑定器和其他应用程序通信。
介绍
Spring Cloud Stream是一个用来为微服务应用构建消息驱动能力的框架。它可以基于Spring Boot来创建独立的、可用于生产的Spring应用程序。它通过使用Spring Integration来连接消息代理中间件以实现消息事件驱动的微服务应用。Spring Cloud Stream为一些供应商的消息中间件产品提供了个性化的自动化配置实现,并且引入了发布-订阅、消费组以及消息分区这三个核心概念。简单的说,Spring Cloud Stream本质上就是整合了Spring Boot和Spring Integration,实现了一套轻量级的消息驱动的微服务框架。通过使用Spring Cloud Stream,可以有效地简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。目前Spring Cloud Stream官方的实现有RabbitMQ Binder和Kafka Binder,而Spring Cloud Alibaba内部已经实现了RocketMQ Binder。处理模型图如下: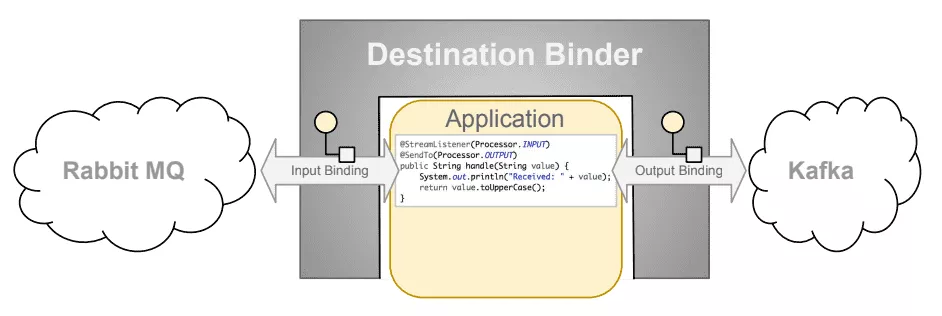
从图中可以看出,Binding 是连接应用程序跟消息中间件的桥梁,用于消息的消费和生产
关键概念
- Inputs:接收消息的通道
- Output:发送消息的通道
- Binder:可理解为一个抽象的中间件,应用通过在spring cloud stream中所注入的inputs,outputs通道来跟外界消息通信,而这些通道又是通过具体中间件的Binder实现来连接到消息队列的服务器上。有了Binder,甚至可以不改一行代码,就切换中间件的类型。
- Group:消费组,一个消息到达一个消费组后,只能被这个消费组的其中一个实例消费掉;
- Partion:消息分区,一个非常大的topic可以分布到多个broker(即服务器)上
RabbitMQ消息中间件
介绍与相关资料
消息队列介绍
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
RabbitMQ 特点
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
- 可靠性(Reliability)
- RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。
- 灵活的路由(Flexible Routing)
- 在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
- 消息集群(Clustering)
- 多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。
- 高可用(Highly Available Queues)
- 队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
- 多种协议(Multi-protocol)
- RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
- 多语言客户端(Many Clients)
- RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。
- 管理界面(Management UI)
- RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
- 跟踪机制(Tracing)
- 如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。
- 插件机制(Plugin System)
- RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
RabbitMQ 中的概念模型
- 消息模型
所有 MQ 产品从模型抽象上来说都是一样的过程:
消费者(consumer)订阅某个队列。生产者(producer)创建消息,然后发布到队列(queue)中,最后将消息发送到监听的消费者。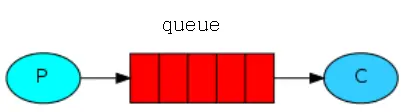
- RabbitMQ 基本概念
上面只是最简单抽象的描述,具体到 RabbitMQ 则有更详细的概念需要解释。上面介绍过 RabbitMQ 是 AMQP 协议的一个开源实现,所以其内部实际上也是 AMQP 中的基本概念: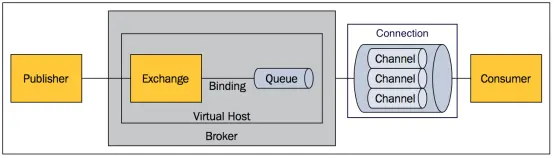
- Message
- 消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
- Publisher
- 消息的生产者,也是一个向交换器发布消息的客户端应用程序。
- Exchange
- 交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
- Binding
- 绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
- Queue
- 消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
- Connection
- 网络连接,比如一个TCP连接。
- Channel
- 信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
- Consumer
- 消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
- Virtual Host
- 虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
- Broker
- 表示消息队列服务器实体。
- AMQP 中的消息路由
AMQP 中消息的路由过程和 Java 开发者熟悉的 JMS 存在一些差别,AMQP 中增加了 Exchange 和 Binding 的角色。生产者把消息发布到 Exchange 上,消息最终到达队列并被消费者接收,而 Binding 决定交换器的消息应该发送到那个队列。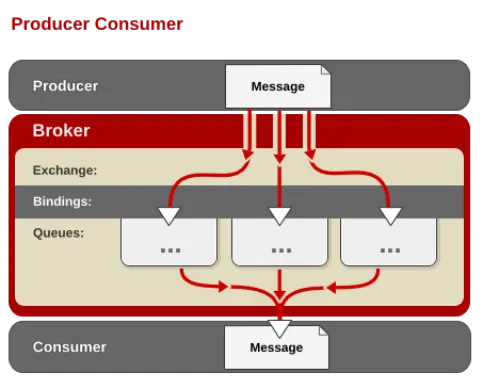
- Exchange 类型
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、topic、headers 。headers 匹配 AMQP 消息的 header 而不是路由键,此外 headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以直接看另外三种类型: - direct
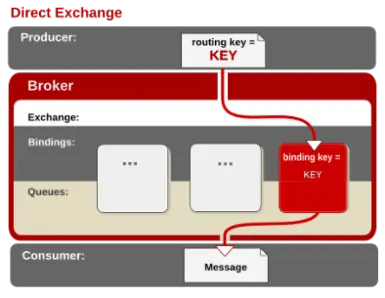
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式。
2. fanout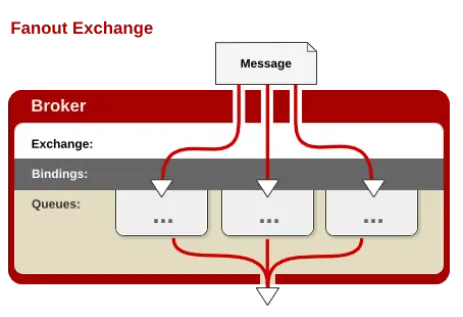
每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的。
3. topic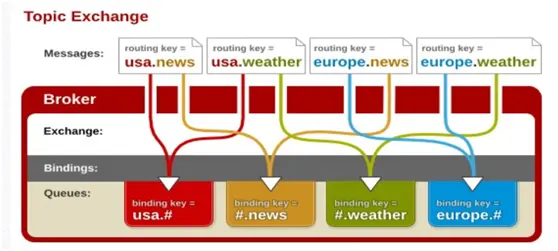
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“”。#匹配0个或多个单词,匹配不多不少一个单词。
监控中心
服务器与基础设施监控
- 监控介绍
ELK主要收集分析预警的是我们平台系统中各个服务的业务日志,一般通过日志组件(log4j 、log4j2 、logback)来收集并写入文本。但是对于系统本身以及一些应用软件的监控预警,这套方案显然是不合适的,这里推荐一下GPE三剑客;基本上主流的中间件和应用都能监控,并且大多数都是代码无入侵的。 - 监控结构图
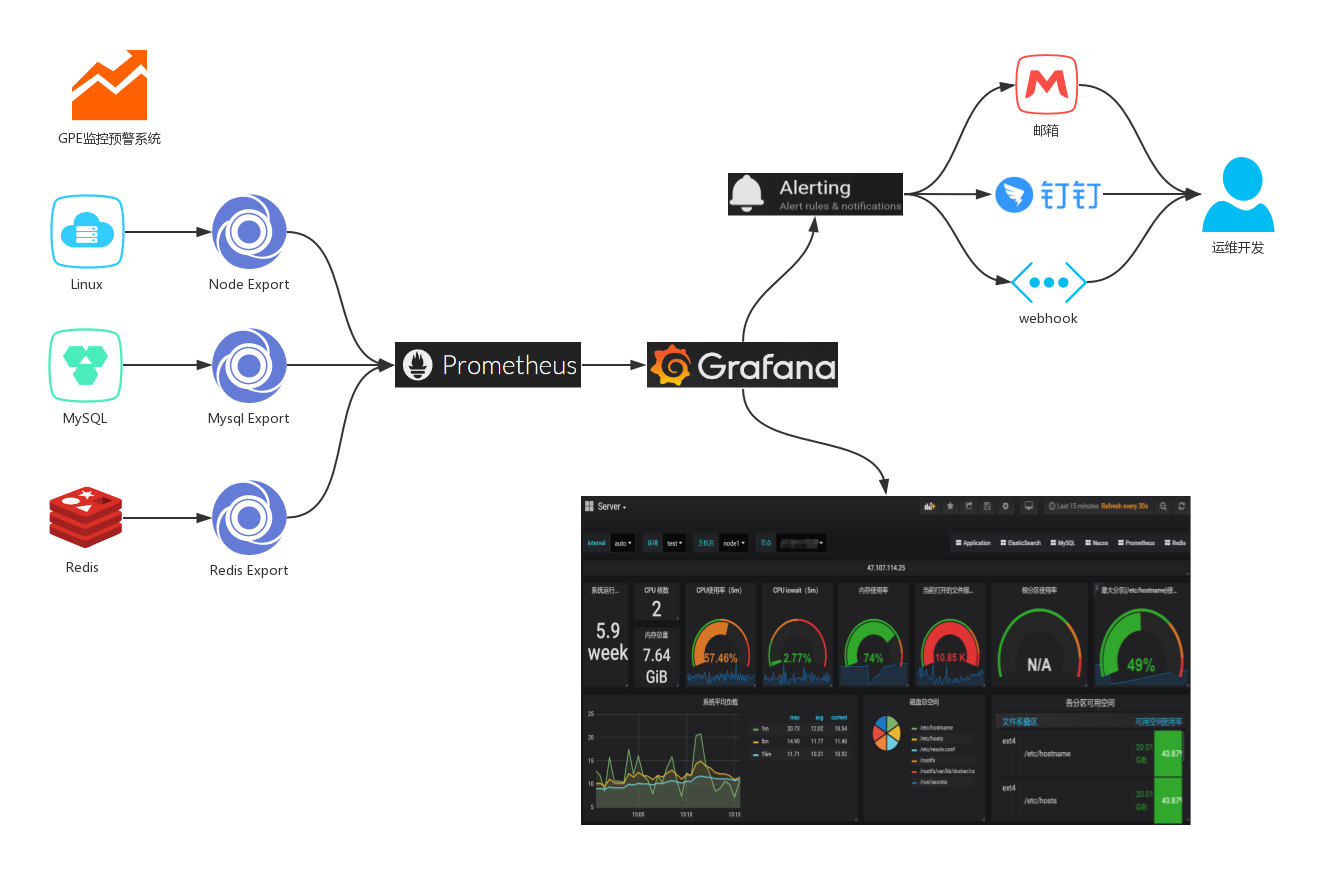
- 监控核心组件
Grafana、Prometheus、Exporter的三剑客,使用邮件、钉钉以及webhook实现异常告警。
- Prometheus:是一个开源的服务监控系统,它通过HTTP协议从远程的机器收集数据并存储在本地的时序数据库上。
- Grafana:是一个开箱即用的可视化工具,具有功能齐全的度量仪表盘和图形编辑器,有灵活丰富的图形化选项,可以混合多种风格,支持多个数据源特点。
- Exporter:是一系列的插件和外部进程,支持黑盒获取metrics(代码无入侵)
- 监控工作流程
- Exporter组件获取服务器或者系统软件的metrics
- Prometheus拉取Exporter的metrics到本地存储
- Grafana配置Prometheus数据源获取其采集数据结合自定义面板实现监控大屏
- Grafana通过设置Alerting实现监控预警
PGA监控
- 介绍与相关资料
- Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作。Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
- Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker 。
Prometheus应该是为数不多的适合Docker、Mesos、Kubernetes环境的监控系统之一。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等),具体支持的源看:https://github.com/prometheus。 - 与其他监控系统相比,Prometheus的主要特点是:
- 一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)。
- 非常高效的存储,平均一个采样数据占~3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 一种灵活的查询语言。
- 不依赖分布式存储,单个服务器节点。
- 时间集合通过HTTP上的PULL模型进行。
- 通过中间网关支持推送时间。
- 通过服务发现或静态配置发现目标。
- 多种模式的图形和仪表板支持。
- Prometheus架构
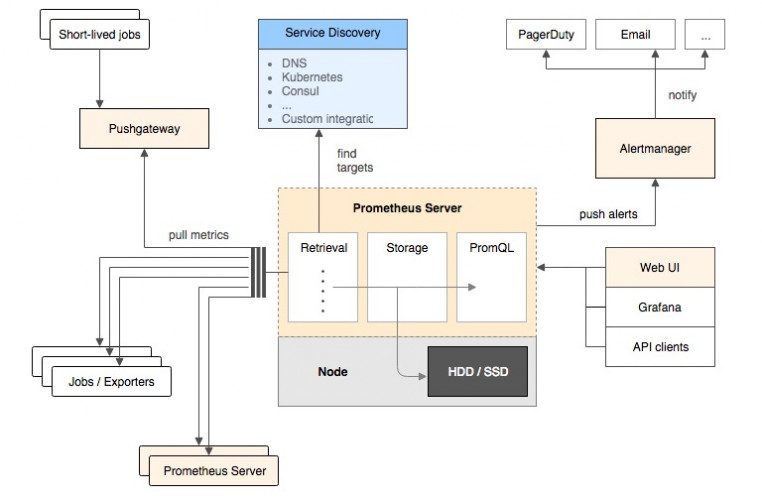
- 它的服务过程是这样的Prometheus daemon负责定时去目标上抓取metrics(指标) 数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。
- Prometheus:支持通过配置文件、文本文件、zookeeper、Consul、DNS SRV lookup等方式指定抓取目标。支持很多方式的图表可视化,例如十分精美的Grafana,自带的Promdash,以及自身提供的模版引擎等等,还提供HTTP API的查询方式,自定义所需要的输出。
- Alertmanager:是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
- PushGateway:这个组件是支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- 大多数Prometheus组件都是用Go编写的,它们可以轻松地构建和部署为静态二进制文件。访问prometheus.io以获取完整的文档,示例和指南。
- Prometheus 的数据模型
Prometheus 从根本上所有的存储都是按时间序列去实现的,相同的 metrics(指标名称) 和 label(一个或多个标签) 组成一条时间序列,不同的label表示不同的时间序列。为了支持一些查询,有时还会临时产生一些时间序列存储。
metrics name & label 指标名称和标签
每条时间序列是由唯一的 指标名称 和 一组 标签 (key=value)的形式组成。
指标名称 一般是给监测对像起一名字,例如 httprequests_total 这样,它有一些命名规则,可以包字母数字之类的的。
通常是以应用名称开头监测对像数值类型_单位这样。
- Prometheus 的四种数据类型
- Counter
- Counter 用于累计值,例如 记录 请求次数、任务完成数、错误发生次数。
- 一直增加,不会减少。
- 重启进程后,会被重置。
- Gauge
- Gauge 常规数值,例如 温度变化、内存使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
- Histogram
- Histogram 可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供 count 和 sum 全部值的功能。
- Summary
- Summary和Histogram十分相似,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的
服务器
监控的服务器: 10.2.11.64 10.2.11.65 10.2.11.66 10.2.10.224
- 安装node-exporter
docker pull node-exporter
- 运行 node-exporter
docker run -d \--name node-exporter \-p 9100:9100 \-v "/proc:/host/proc" \-v "/sys:/host/sys" \-v "/:/rootfs" \--net="host" \10.3.0.171/prometheus/prom/node-exporter:latest
- 修改prometheus的配置
- job_name: 'node-exporter'static_configs:- targets: ["10.2.11.64:9100","10.2.11.65:9100","10.2.11.66:9100","10.2.10.224:9100"]
数据库—MySQL
- 安装mysqld-exporter
- 运行mysqld-exporter
docker run -d -p 9104:9104 \--name mysqld-master-exporter-e DATA_SOURCE_NAME="root:1q2w3e4r@(10.2.11.66:3306)/nacos" \10.3.0.171/prometheus/prom/mysqld-exporter:latest
docker run -d -p 9104:9104 \--name mysqld-slave-exporter-e DATA_SOURCE_NAME="root:1q2w3e4r@(10.2.10.224:3306)/nacos" \10.3.0.171/prometheus/prom/mysqld-exporter:latest
docker run -d -p 9104:9104 \--name mysqld-slave-exporter-e DATA_SOURCE_NAME="root:root@(10.3.0.247:31106)/nacos" \10.3.0.171/prometheus/prom/mysqld-exporter:latest
- 修改prometheus配置
- job_name: 'mysql-exporter'static_configs:- targets: ['10.3.0.247:9104']labels:name: mysqlinstance: 10.3.0.247:31106
- job_name: 'mysql-exporter'static_configs:- targets: ['10.2.11.66:9104']labels:name: mysqlinstance: 10.2.11.66:3306
- job_name: 'mysql-exporter'static_configs:- targets: ['10.2.10.224:9104']labels:name: mysqlinstance: 10.2.10.224:3306
数据库—Redis
- 安装redis-exporter
docker pull 10.3.0.171/prometheus/Oliver/redis-exporter:latest
- 运行 redis-exporte
docker run -d \--name redis_exporter \-p 9121:9121 \10.3.0.171/prometheus/Oliver/redis-exporter:latest \--redis.addr redis://10.2.11.64:3379
- 修改prometheus的配置
- job_name: 'redis-exporter'static_configs:- targets: ['10.2.11.64:9121']
ELK日志监控
日志解决方案设计
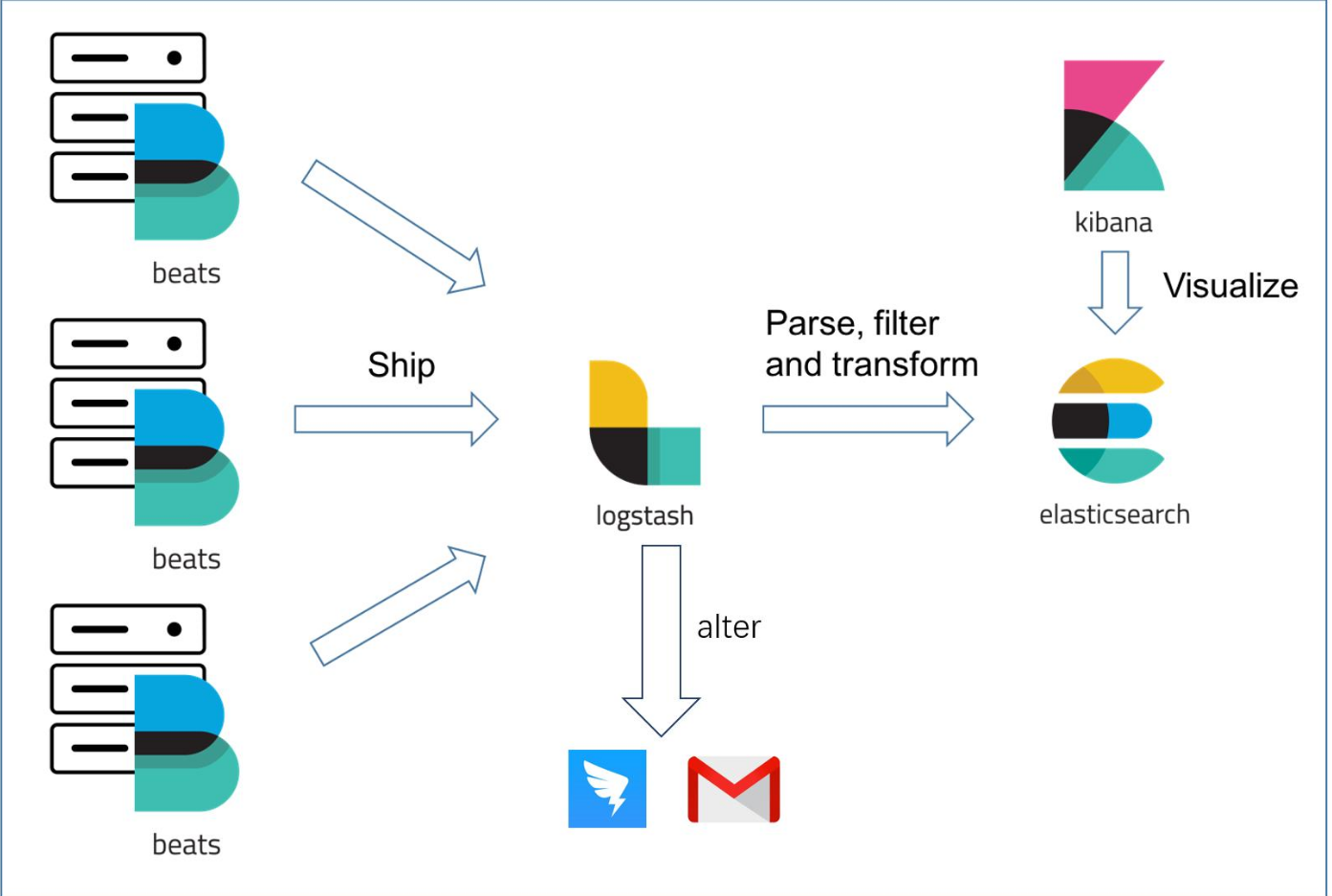
- 组件说明
- filebeat:部署在每台应用服务器、数据库、中间件中,负责日志抓取与聚合日志
- 日志聚合:把多行日志合并成一条,例如exception的堆栈信息等
- logstash:通过各种filter结构化日志信息,并把字段transform成对应的类型
- elasticsearch:负责存储和查询日志信息
- kibana:通过ui展示日志信息、还能生成饼图、柱状图等
- ELK常见部署架构
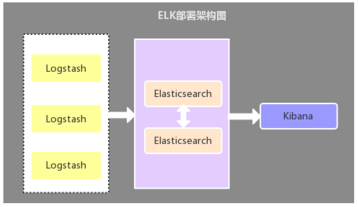
2.1. Logstash作为日志收集器
- 这种架构是比较原始的部署架构,在各应用服务器端分别部署一个Logstash组件,作为日志收集器,然后将Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展示,这种架构不足的是:Logstash比较耗服务器资源,所以会增加应用服务器端的负载压力
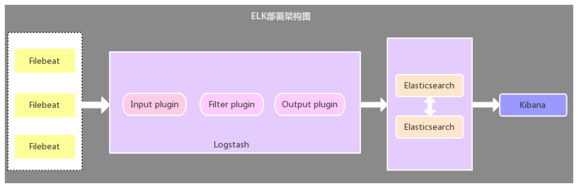
2.2. Filebeat作为日志收集器 - 该架构与第一种架构唯一不同的是:应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最常用的架构
2.3. 引入缓存队列的部署架构 - 该架构在第二种架构的基础上引入了Kafka消息队列(还可以是其他消息队列),将Filebeat收集到的数据发送至Kafka,然后在通过Logstasth读取Kafka中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力
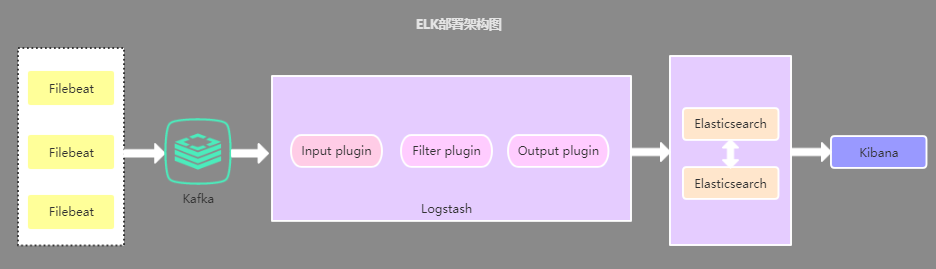
2.4. 以上三种架构的总结 - 第一种部署架构由于资源占用问题,现已很少使用,目前使用最多的是第二种部署架构,至于第三种部署架构个人觉得没有必要引入消息队列,除非有其他需求,因为在数据量较大的情况下,Filebeat 使用压力敏感协议向 Logstash 或 Elasticsearch 发送数据。如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并继续发送数据
应用服务的监控
Sentinel流控中心
Sentinel
- 概述
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式服务架构的轻量级流量控制框架,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助您保护服务的稳定性。
Sentinel 提供一个轻量级的开源控制台,它提供机器发现以及健康情况管理、监控(单机和集群),规则管理和推送的功能。
Sentinel 控制台包含如下功能
- 查看机器列表以及健康情况:收集 Sentinel 客户端发送的心跳包,用于判断机器是否在线。
- 监控 (单机和集群聚合):通过 Sentinel 客户端暴露的监控 API,定期拉取并且聚合应用监控信息,最终可以实现秒级的实时监控。
- 规则管理和推送:统一管理推送规则。
- 资源
资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。 - 规则
围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。 - 各功能的介绍与使用
4.1. 流量控制
概述
流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
- resource:资源名,即限流规则的作用对象
- count: 限流阈值
- grade: 限流阈值类型(QPS 或并发线程数)
- limitApp: 流控针对的调用来源,若为 default 则不区分调用来源
- strategy: 调用关系限流策略
- controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
4.1.1. 基于QPS/并发数的流量控制
流量控制主要有两种统计类型,一种是统计并发线程数,另外一种则是统计 QPS。
并发线程数流量控制
并发线程数限流用于保护业务线程数不被耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel 并发线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目,如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。
QPS流量控制
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括以下几种:直接拒绝、Warm Up、匀速排队。
直接拒绝
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。
Warm Up
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过”冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
匀速排队
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。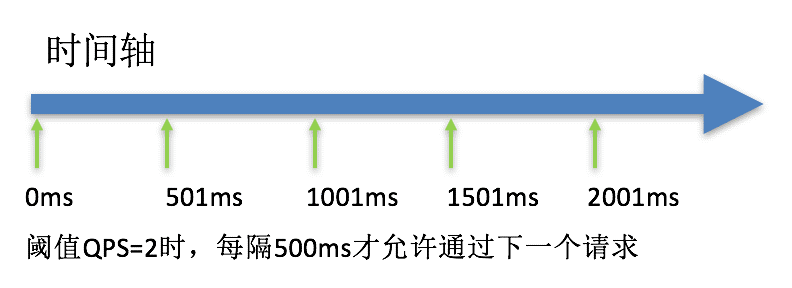
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
4.2. 降级规则
概述
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断。
降级策略
- RT(平均响应时间):当资源的RT超过阈值时,资源进入准降级状态。
- 异常比例:当资源的每秒异常总数占通过量的比值超过阈值,进入准降级状态,即在接下的时间窗口内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
- 异常数:当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意:异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常不生效。
4.3. 实时监控
对于每个应用服务下的实时监控内可以看到应用服务内所有资源的QPS(服务系统一定时间内接收客户端请求的一个并发处理能力)。
峰值QPS和机器计算公式
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 80% ) / ( 每天秒数 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
4.4. 热点规则
热点即经常访问的数据。
| 属性 | 说明 | 默认值 |
|---|---|---|
| 资源名 | 资源名,必填 | |
| 限流模式 | 限流模式 | QPS模式 |
| 参数索引 | 热点参数的索引,必填 | |
| 是否集群 | 表示资源是否是在多个服务器上加载资源 | 默认非必填 |
| 均摊阈值 | 如果是单机运行,则单机负载阈值 | |
| 集群阈值 | 整个集群内负载阈值 |
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
4.5. 系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的总体 Load、RT、入口 QPS 和线程数四个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统规则支持四种阈值类型:
- Load(仅对 Linux/Unix-like 机器生效):当系统 load1 超过阈值,且系统当前的并发线程数超过系统容量时才会触发系统保护。系统容量由系统的 maxQps minRt 计算得出。设定参考值一般是 CPU cores 2.5。
- RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
4.6. 授权规则
授权规则也是黑白名单规则,黑白名单根据资源的请求来源限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。
| 属性 | 说明 | 默认值 |
|---|---|---|
| 资源名 | 必填 | |
| 流控应用 | 只掉用房,多个调用方,用”,”分隔开 | |
| 授权类型 | 白名单、黑名单 |
4.7. 集群流控
集群流控中共有两种身份:
- Token Client:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
- Token Server:即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)
4.8. 机器列表
可以在Sentinel此功能内显示出来该应用服务所有执行此服务的server地址,与此server下的运行状态。
DevOps

CICDde的流程设计
一、CICD概念
持续集成(CI):持续编译、测试、打包;
持续部署(CD):代码在任何时刻都是可部署的,并且适配不同的环境自动部署
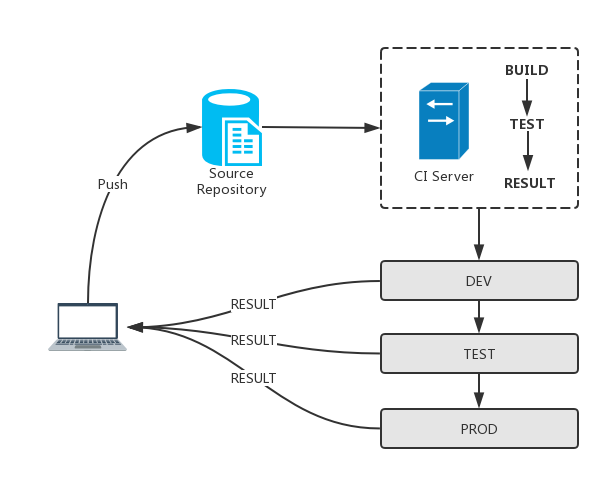
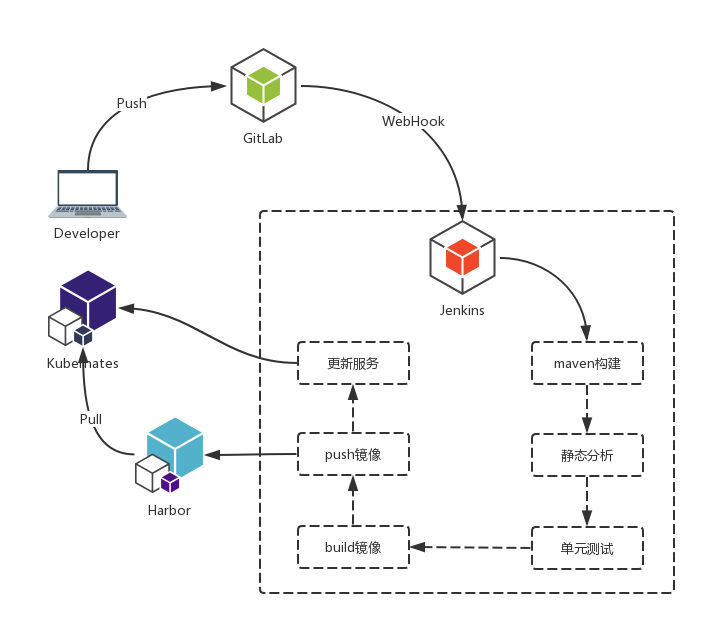
二、企业级CICD流水线
- 开发提交代码 -> GitLab
- GitLab 通过 WebHook 触发Jenkins构建
- Jenkins 跑构建流程
- 更新 Harbor 的镜像
- 通知K8s触发更新服务
GitHub webhook配置
一、说明
- webhoo是一种web回调或者http的push API,是向APP或者其他应用提供实时信息的一种方式。
- 一般是需要通过git的某些行为触发jenkins构建使用
- 如果只需要手动构建的话可以忽略webhook
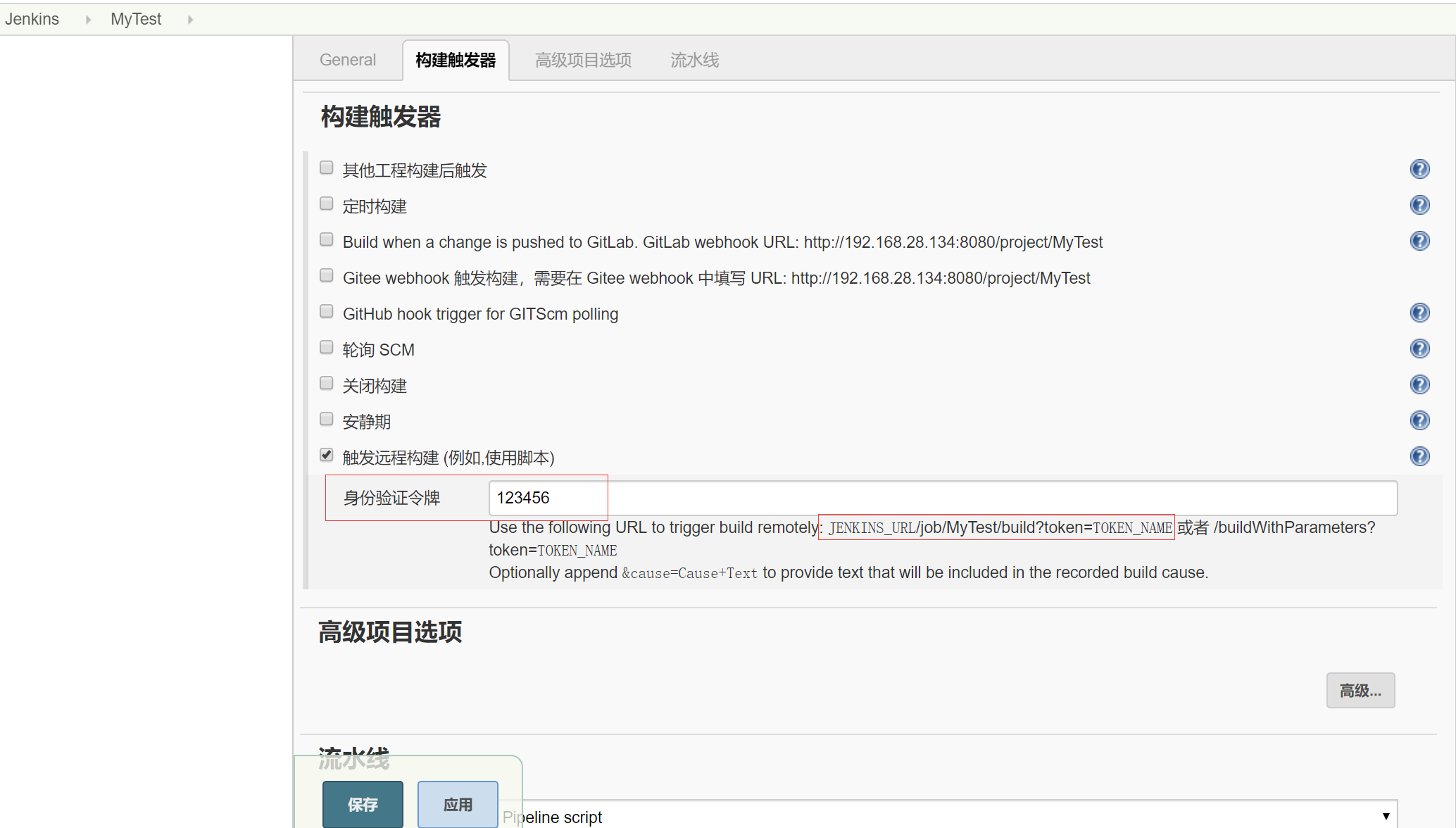
二、配置触发
- 打开webhoo页面项目详情页面 -> Settings -> Integrations

- URL为jenkins的job构建地址加token参数
- jenkins的token配置如下图
- Trigger为触发的行为,默认是Push操作
- 增加webhook
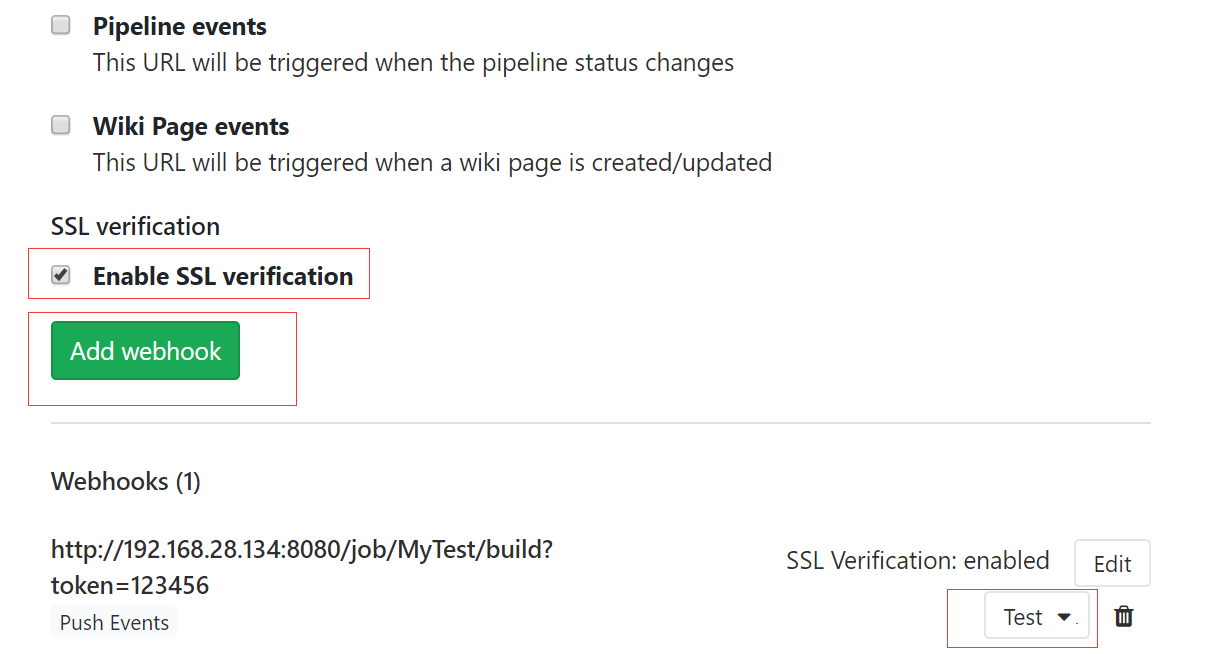
- 可以通过test按钮测试触发器
Harbor私有仓库
一、介绍
Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器。Harbor用于容器镜像管理,主要提供基于角色的镜像访问控制、镜像复制、镜像漏洞分析、镜像验真和操作审计等功能。
二、新建项目
默认是私有项目,必需通过docker login登录后才能拉取或者提交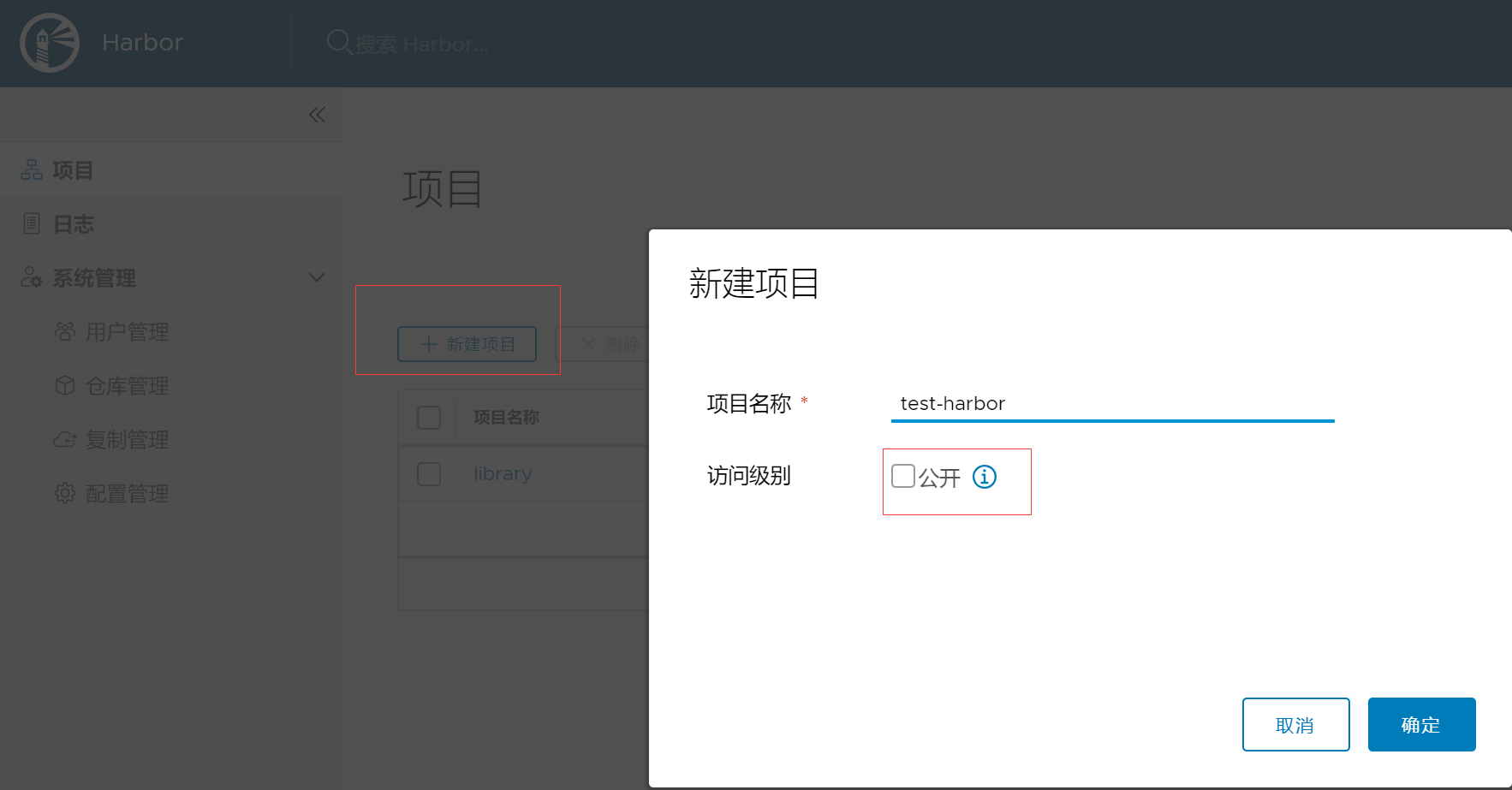
jenkins的安装部署及配置
一、环境准备
本说明是针对使用需要Java 8的Jenkins发行版。还建议使用超过512MB RAM的系统,并且在安装jenkins的服务器先装好以下环境
Java 8(JRE或JDK)
git
maven 3.5+
512MB可用内存
1GB +可用磁盘空间
二、下载Jenkins
http://mirrors.jenkins.io/war/latest/jenkins.war
三、创建启动文件start.sh
nohup java -Dhudson.util.ProcessTree.disable=true -jar jenkins.war --httpPort=8080 >> nohup.out 2>&1 &
-Dhudson.util.ProcessTree.disable=true 参数意思为:禁止Jenkins在Job构建过程结束后认为将kill掉未执行完的子进程https://wiki.jenkins.io/display/JENKINS/ProcessTreeKiller
四、启动和访问
- 启动
sh start.sh
五、插件安装
- 首次登录时候的插件安装
进入选择插件安装界面,选择第一个(Install suggested plugins)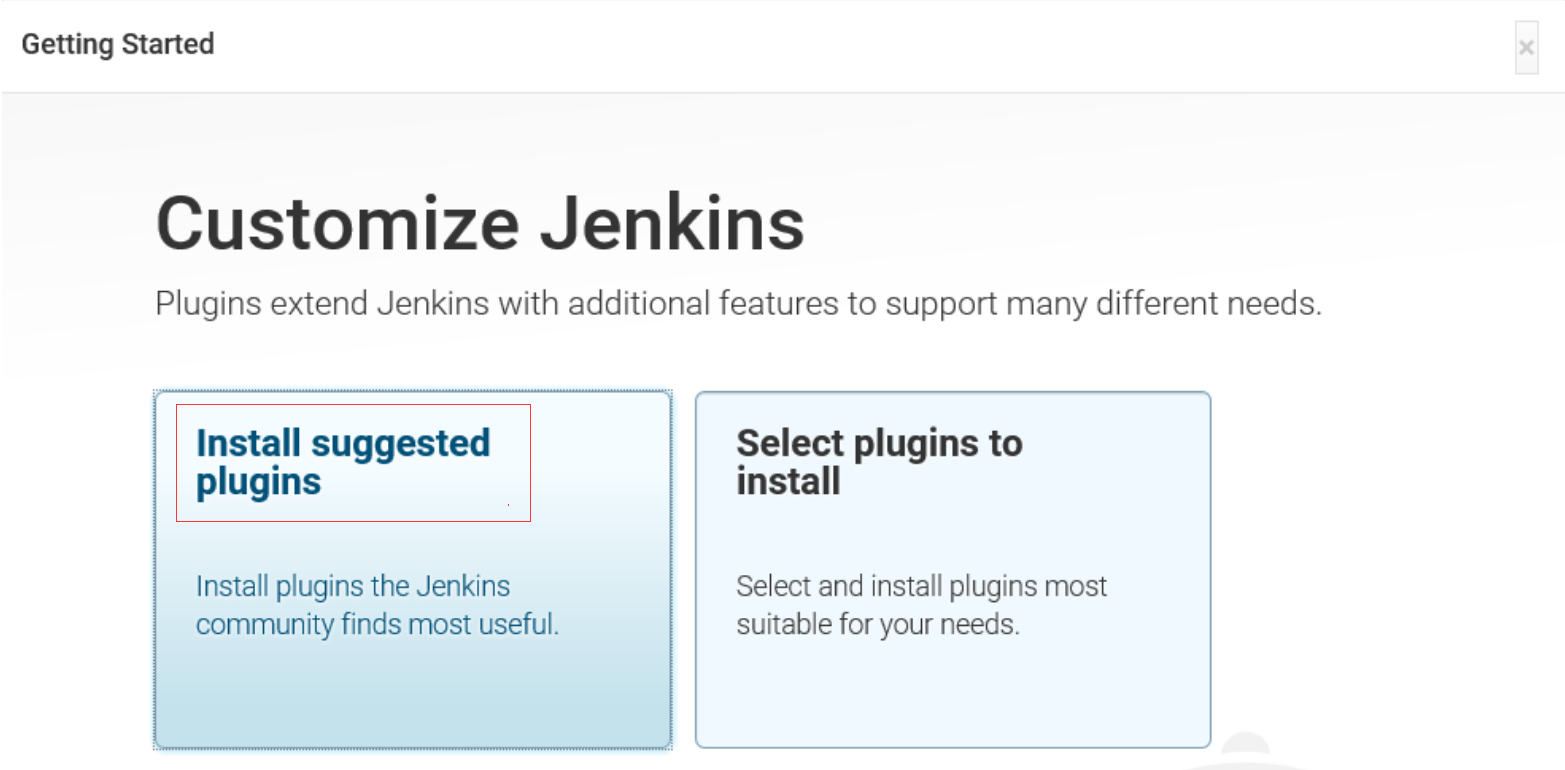
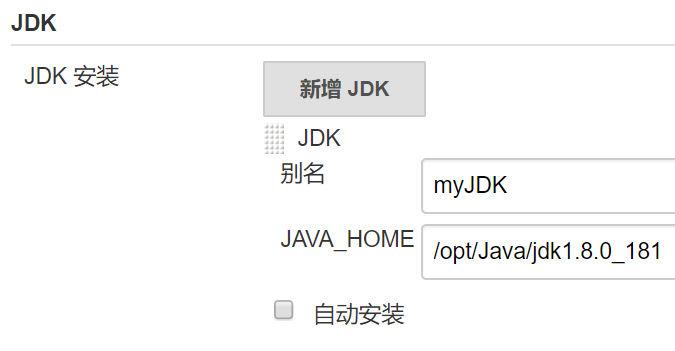
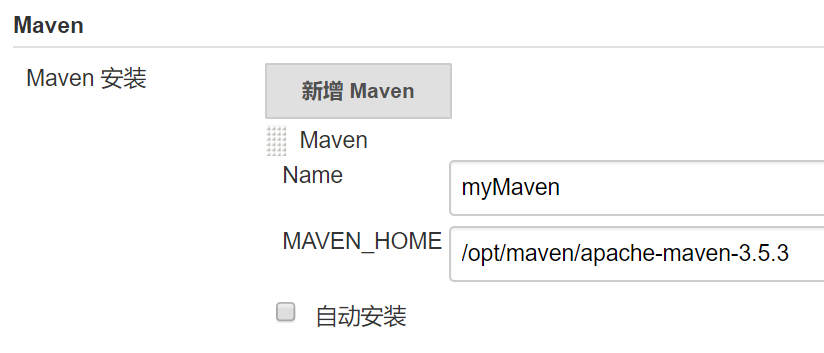
六、全局工具配置
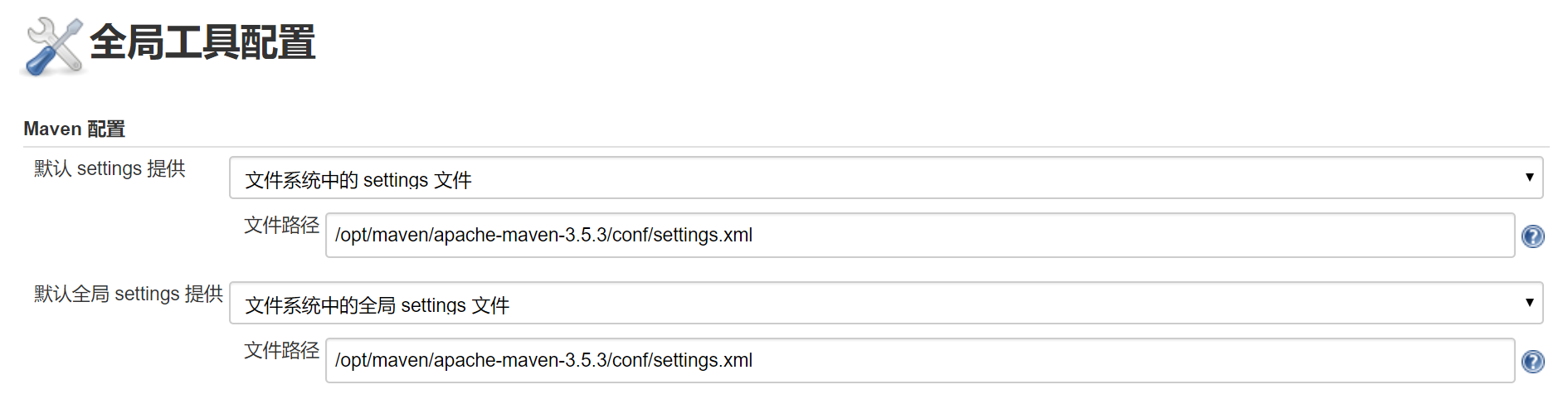
Maven 配置
配置maven的settings.xml路径

七、安全配置
- 配置匿名可读权限
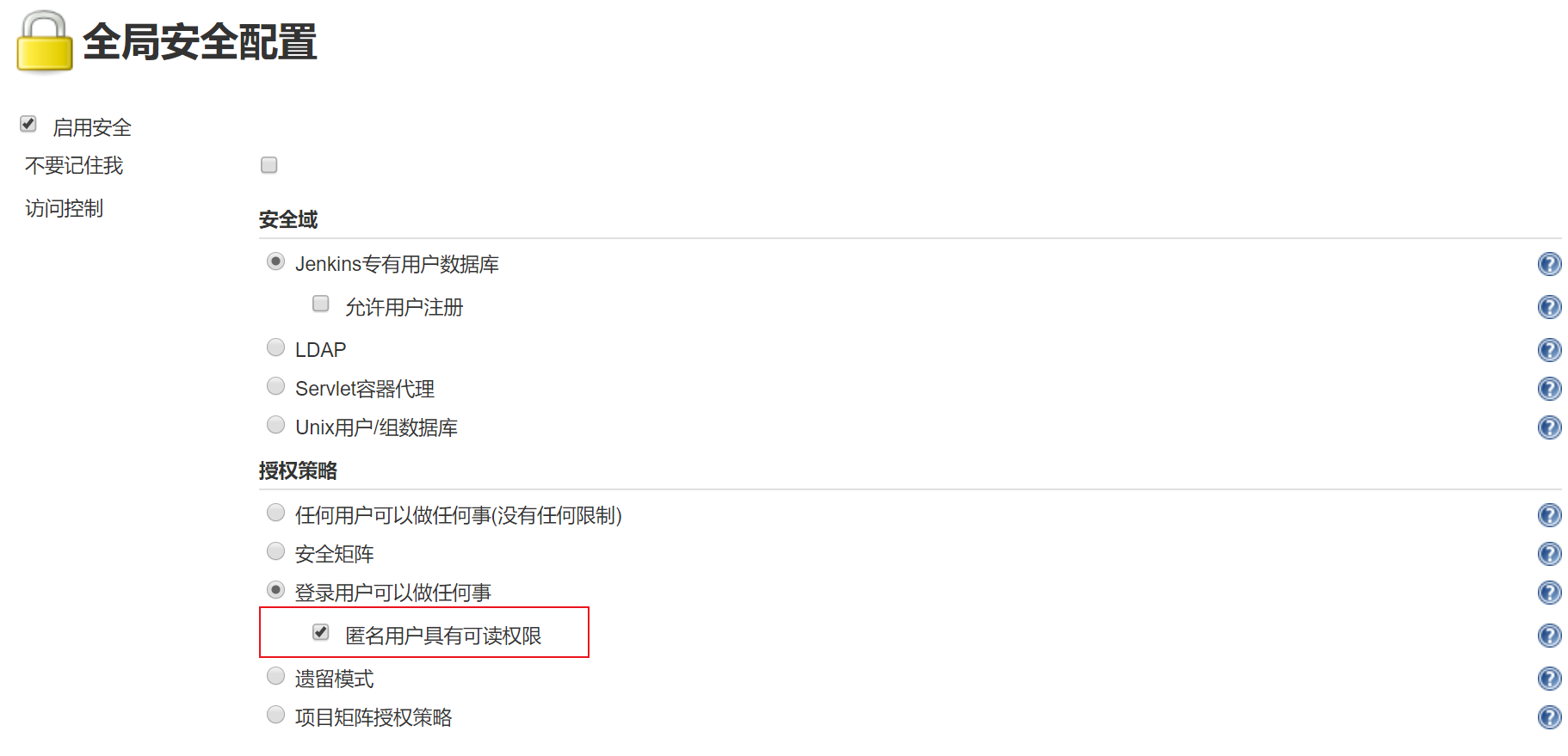
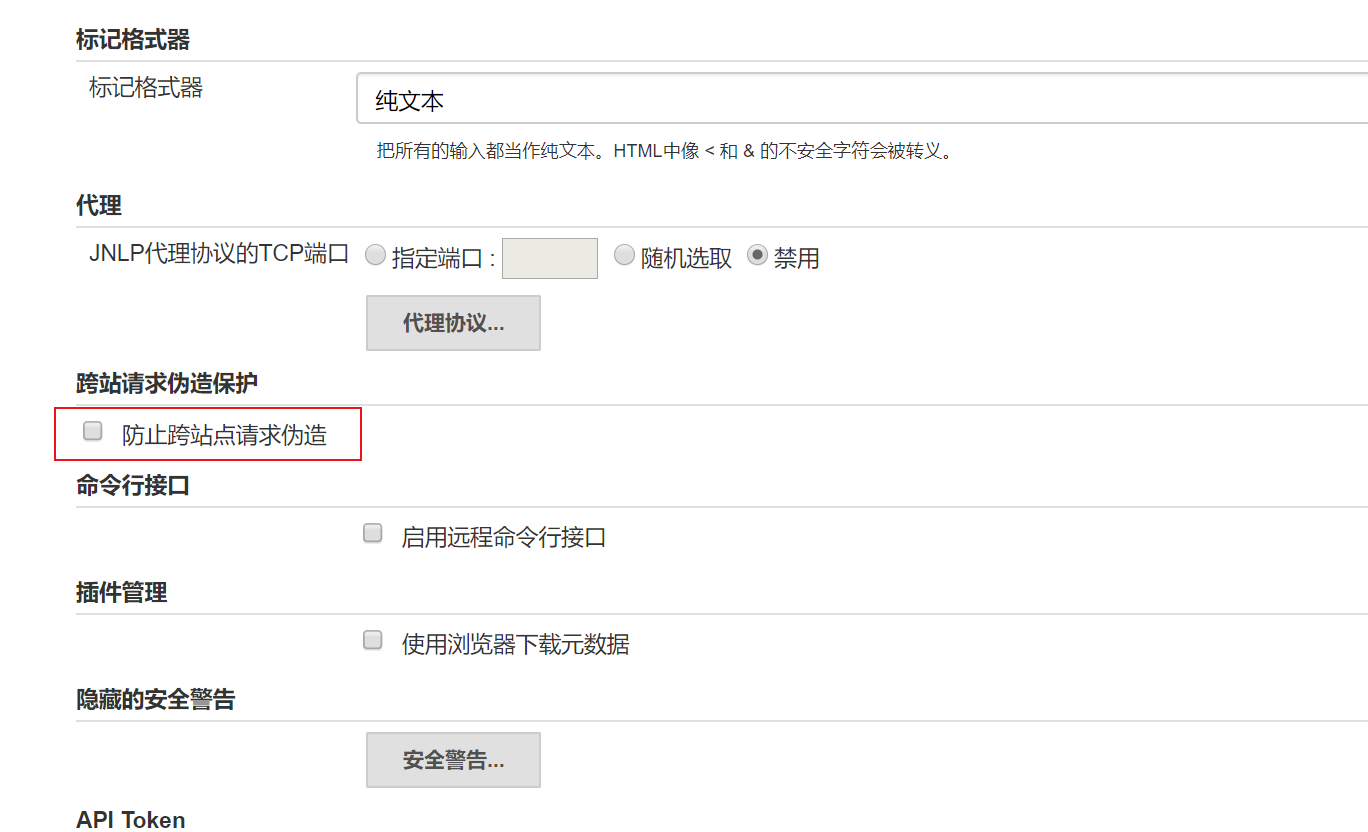
- 取消跨站请求伪造保护
jenkins流水线设置
流水线方式一:github+jemkins+k8s+docker+harbor
- 流水线配置,如下图
- jenkins流水线脚本
- jenkins脚本—Jenkinsfile
pipeline{agent anytools {jdk 'java8'maven 'maven3.3.9'}environment {REPOSITORY="git@10.2.10.29:weizhi/springblade.git"SCRIPT_PATH=""}stages{stage('获取代码'){steps {echo "start fetch code from git:${REPOSITORY}"deleteDir()git "${REPOSITORY}"}}stage('编译'){steps{echo "start compile"sh "mvn -U -am clean package -Dmaven.test.skip=true"}}stage('构建镜像') {steps{echo "start build images"sh 'chmod +x ./script/k8s-springblade-build.sh'sh './script/k8s-springblade-build.sh build'}}stage('发布系统') {steps {withKubeConfig([contextName: 'kubernetes-admin@kubernetes',credentialsId: 'k8s',namespace: 'dao']) {sh 'chmod +x ./script/k8s-springblade-deploy.sh'sh './script/k8s-springblade-deploy.sh deploy'}}}}}
- Jenkinsfile中涉及到的其他部署脚本:
- jenkins-build.sh 进行docker镜像的构建与上传私有云harbor
#!/bin/bashIMAGE_REPOSITORY=10.3.0.171/blade/GIT_VERSION=$(git log -1 --pretty=format:"%h")MOUDLE=(blade-gateway blade-auth blade-ops blade-service)MOUDLE_OPS=(blade-admin blade-develop)MOUDLE_SERVICE=(blade-desk blade-log blade-system blade-user)#使用说明,用来提示输入参数usage(){echo "Usage: sh 执行脚本.sh [build]"exit 1}#构建镜像build() {for moudleName in ${MOUDLE[@]};doecho "组装构建镜像名称"if [ $moudleName = "blade-ops" ];thenfor moudleOps in ${MOUDLE_OPS[@]};doIMAGE_NAME=${IMAGE_REPOSITORY}$moudleOps:${GIT_VERSION}docker build -t ${IMAGE_NAME} ./${moudleName}/${moudleOps}/docker login 10.3.0.171 -u springblade -p ZWZ@gree#2018docker push ${IMAGE_NAME}docker rmi ${IMAGE_NAME}echo "构建${IMAGE_NAME} is ending"doneelif [ $moudleName = "blade-service" ];thenfor moudleService in ${MOUDLE_SERVICE[@]};doIMAGE_NAME=${IMAGE_REPOSITORY}$moudleService:${GIT_VERSION}docker build -t ${IMAGE_NAME} ./${moudleName}/${moudleService}/docker login 10.3.0.171 -u springblade -p ZWZ@gree#2018docker push ${IMAGE_NAME}docker rmi ${IMAGE_NAME}echo "构建${IMAGE_NAME} is ending"doneelseIMAGE_NAME=${IMAGE_REPOSITORY}$moudleName:${GIT_VERSION}echo $IMAGE_NAMEdocker build -t ${IMAGE_NAME} ./${moudleName}/docker login 10.3.0.171 -u springblade -p ZWZ@gree#2018docker push ${IMAGE_NAME}docker rmi ${IMAGE_NAME}echo "构建${IMAGE_NAME} is ending"fidone#更新配置文件版本sed -i 's/{{VERSION}}/${GIT_VERSION}/g' ./script/nacos/.env}#根据输入参数,选择执行对应方法,不输入则执行使用说明case "$1" in"build")build;;*)usage;;esac
- jenkins-deploy.sh 将服务发布到k8s中进行自动的服务编排
#!/bin/bashGIT_VERSION=$(git log -1 --pretty=format:"%h")MOUDLE=(blade-auth blade-ops blade-service blade-gateway)MOUDLE_OPS=(blade-admin blade-develop)MOUDLE_SERVICE=(blade-desk blade-log blade-system blade-user)#使用说明,用来提示输入参数usage() {echo "Usage: sh 执行脚本.sh [deploy]"exit 1}deploy(){for moudleName in ${MOUDLE[@]};doif [ $moudleName = "blade-ops" ];thenfor moudleOps in ${MOUDLE_OPS[@]};doecho "更新镜像$moudleOps发布到k8s上"kubectl apply -f ${moudleName}/${moudleOps}/${moudleOps}.yamlsed -i "s/{{TAG}}/$GIT_VERSION/g" ${moudleName}/${moudleOps}/deployment.yamlkubectl apply -f ${moudleName}/${moudleOps}/deployment.yamlsleep 5secho "更新镜像$moudleOps完成"doneelif [ $moudleName = "blade-service" ];thenfor moudleService in ${MOUDLE_SERVICE[@]};doecho "更新镜像$deployPath发布到k8s上"kubectl apply -f ${moudleName}/${moudleService}/${moudleService}.yamlsed -i "s/{{TAG}}/$GIT_VERSION/g" ${moudleName}/${moudleService}/deployment.yamlkubectl apply -f ${moudleName}/${moudleService}/deployment.yamlsleep 5secho "更新镜像$moudleService完成"done;elseecho "更新镜像$moudleName发布到k8s上"kubectl apply -f ${moudleName}/${moudleName}.yamlsed -i "s/{{TAG}}/$GIT_VERSION/g" ${moudleName}/deployment.yamlkubectl apply -f ${moudleName}/deployment.yamlsleep 5secho "更新镜像$moudleName完成"fidone}#根据输入参数,选择执行对应方法,不输入则执行使用说明case "$1" in"deploy")deploy;;*)usage;;esac
流水线方式二:jenkins+github+docker+docker-cmpose实现部署到不同的服务器中
- jenkins流水线脚本
pipeline {agent anytools {jdk 'java8'maven 'maven3.3.9'}environment {app_name="springblade"target_dir="/opt/application"git_addr="git@10.2.10.29:weizhi/springblade.git"target_ssh="root@10.2.11.64"sonar_url="10.2.11.66:9000"backup_dir="/opt/application/backup/springblade"}stages {stage('获取代码') {steps {echo "start fetch code from git:${git_addr} to jenkins"deleteDir()git credentialsId: '260291', url: "${git_addr}"}}stage('代码静态检查') {when {environment name:'is_sonarscan', value:'是'}steps {withSonarQubeEnv('sonarqube-66') {echo "start code check"sh "mvn clean compile sonar:sonar -Dsonar.host.url=http://${sonar_url}"}}}stage('单元测试') {when {environment name:'is_test', value:'是'}steps {echo "start test"sh "mvn test"junit '**/target/surefire-reports/TEST-*.xml'}}stage('打包') {steps {echo "start fetch code from git:${git_addr} to server:${target_ssh}"sh "ssh ${target_ssh} 'cd ${target_dir};chmod +x task.sh;sh task.sh git_clone'"echo "start package"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/task/;chmod +x task.sh;sh task.sh mvn_package'"}}stage('部署') {steps {echo "start delpoy"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/task/;chmod +x task.sh;sh task.sh tag_version'"script {echo "start build mirror"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;chmod +x deploy.sh '"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh build '"sleep 20}}}stage('推送') {steps {echo "start restart"script {echo "stop containers"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh stop '"sleep 10echo "rm exited containers"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh rmiExitContainer '"echo "push to harbor"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh push '"echo "rmi local mirror"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh rmiBladeTag '"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh rmiNoneTag '"}}}stage('重启') {steps {echo "push to harbor"script {echo "run base services"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh base '"sleep 20echo "run modules services"sh "ssh ${target_ssh} 'cd ${target_dir}/${app_name}/script/nacos/;sh deploy.sh modules '"}}}}post {success {emailext (attachLog: true,subject: "'${env.JOB_NAME} [${env.BUILD_NUMBER}]' 更新正常",body: """<h2>详情:</h2><p>SUCCESSFUL: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'</p><p>状态:${env.JOB_NAME} jenkins 更新运行正常</p><p>URL :${env.BUILD_URL}</p><p>项目名称 :${env.JOB_NAME}</p><p>项目更新进度:${env.BUILD_NUMBER}</p><li>构建日志: <a href="${BUILD_URL}console">${BUILD_URL}console</a></li>""",to: "260291@gree.com.cn;260286@gree.com.cn;260226@gree.com.cn",recipientProviders: [[$class: 'DevelopersRecipientProvider']])}failure {emailext (attachLog: true,subject: "'${env.JOB_NAME} [${env.BUILD_NUMBER}]' 更新失败",body: """<h2>详情:</h2><p>FAILED: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'</p><p>状态:${env.JOB_NAME} jenkins 运行失败</p><p>URL :${env.BUILD_URL}</p><p>项目名称 :${env.JOB_NAME}</p><p>项目更新进度:${env.BUILD_NUMBER}</p><li>构建日志: <a href="${BUILD_URL}console">${BUILD_URL}console</a></li>""",to: "260291@gree.com.cn;260286@gree.com.cn;260226@gree.com.cn",recipientProviders: [[$class: 'DevelopersRecipientProvider']])}}}
#!/bin/bash#全局参数配置app_name="springblade"target_dir="/opt/application"backup_dir="/opt/application/backup"git_addr="git@10.2.10.29:weizhi/springblade.git"sonar_url="10.2.10.29:9000"#使用说明,用来提示输入参数usage() {echo "Usage: sh 执行脚本.sh [git_clone 拉取代码|mvn_package 编译打包|tag_version 项目版本号]"exit 1}#拉取代码git_clone(){cd ${target_dir};rm -rf ${app_name};git clone "${git_addr}"}#编译打包mvn_package(){cd ${target_dir}/${app_name};mvn package -Dmaven.test.skip=true}#修改项目版本号tag_version(){cd ${target_dir}/${app_name};git_version=`git log -1 --pretty=format:"%h"`;cd ${target_dir}/${app_name}/script/nacos/;sed -i "s/{{TAG_VERSION}}/${git_version}/g" ${target_dir}/${app_name}/script/nacos/.env}#根据输入参数,选择执行对应方法,不输入则执行使用说明case "$1" in"git_clone")git_clone;;"mvn_package")mvn_package;;"tag_version")tag_version;;*)usage;;esac
#使用说明,用来提示输入参数usage() {echo "Usage: sh 执行脚本.sh [port 开放端口|base 基础模块|modules 业务模块|build 构建镜像|push 推送到harbor|stopBase 关闭基础服务|stopModules 关闭业务服务|stop 关闭DAO微服务|rm 删除容器|rmiNoneTag 删除无TAG镜像|rmiBladeTag 删除DAO镜像|rmiExitContainer 删除退出的容器]"exit 1}#开启所需端口port(){firewall-cmd --add-port=80/tcp --permanentfirewall-cmd --add-port=88/tcp --permanentfirewall-cmd --add-port=8848/tcp --permanentfirewall-cmd --add-port=3306/tcp --permanentfirewall-cmd --add-port=3379/tcp --permanentfirewall-cmd --add-port=7002/tcp --permanentservice firewalld restart}##放置挂载文件mount(){if test ! -f "/docker/nginx/gateway/nginx.conf" ;thenmkdir -p /docker/nginx/gatewaycp nginx/gateway/nginx.conf /docker/nginx/gateway/nginx.conffiif test ! -f "/docker/nginx/web/nginx.conf" ;thenmkdir -p /docker/nginx/webcp nginx/web/nginx.conf /docker/nginx/web/nginx.confcp -r nginx/web/html /docker/nginx/web/htmlfi}#启动基础模块base(){mountdocker-compose up -d blade-web blade-nginx blade-redis}#启动程序模块modules(){docker-compose up -d blade-gateway1 blade-gateway2 blade-gateway3 blade-auth1 blade-auth2 blade-user blade-desk blade-system blade-log blade-develop blade-admin}#关闭所有模块stop(){docker-compose stop blade-web blade-nginx blade-redis \blade-gateway1 blade-gateway2 blade-gateway3 blade-admin blade-develop \blade-auth1 blade-auth2 blade-user blade-desk blade-system blade-log}#关闭base模块stopBase(){docker-compose stop blade-web blade-nginx blade-redis}#关闭modules模块stopModules(){docker-compose stop blade-gateway1 blade-gateway2 blade-gateway3 blade-auth1 blade-auth2 blade-user blade-desk blade-system blade-log blade-develop blade-admin}#构建所有的镜像build(){docker-compose build blade-gateway1 blade-admin blade-develop \blade-auth1 blade-user blade-desk blade-system blade-log}#推送所有的镜像push(){docker-compose push blade-gateway1 blade-auth1 blade-user blade-desk blade-system blade-log}#删除所有模块rm(){docker-compose rm blade-web blade-nginx blade-redis \blade-gateway1 blade-gateway2 blade-gateway3 blade-admin blade-develop \blade-auth1 blade-auth2 blade-user blade-desk blade-system blade-log}#删除Tag为空的镜像rmiNoneTag(){if [ `docker images|grep blade-`="" ];thenecho "no none mirror rmi"elsedocker images|grep none|awk '{print $3}'|xargs docker rmi -ffi}#删除exit的容器rmiExitContainer(){if [ `docker ps -a|grep "Exited"`="" ];thenecho "no exit container rm"elsedocker ps -a|grep "Exited" | awk '{print $1}' | xargs docker rmfi}#删除blade-业务镜像rmiBladeTag(){if [ `docker images|grep blade-`="" ];thenecho "no blade mirror rmi"elsedocker images|grep blade-|awk '{print $3}'|xargs docker rmi -ffi}#根据输入参数,选择执行对应方法,不输入则执行使用说明case "$1" in"port")port;;"base")base;;"modules")modules;;"build")build;;"push")push;;"stop")stop;;"stopModules")stopModules;;"stopBase")stopBase;;"rmiExitContainer")rmiExitContainer;;"rm")rm;;"rmiNoneTag")rmiNoneTag;;"rmiBladeTag")rmiBladeTag;;*)usage;;esac
作者 @zzxhub
2018 年 07月 07日

若有收获,就点个赞吧
0 人点赞
