在介绍mybatis之前首先,我先要理解它是做是什么?其实mybatis是一个持久化框架,是把Java程序与关系型数据关联起来的一个框架,它把Java对象与表中的数据映射起来,实现Java程序与数据库之间的交互。
mybatis架构简介
mybatis分为三层架构,分别为基础支撑层、核心处理层和接口层,如下图所示: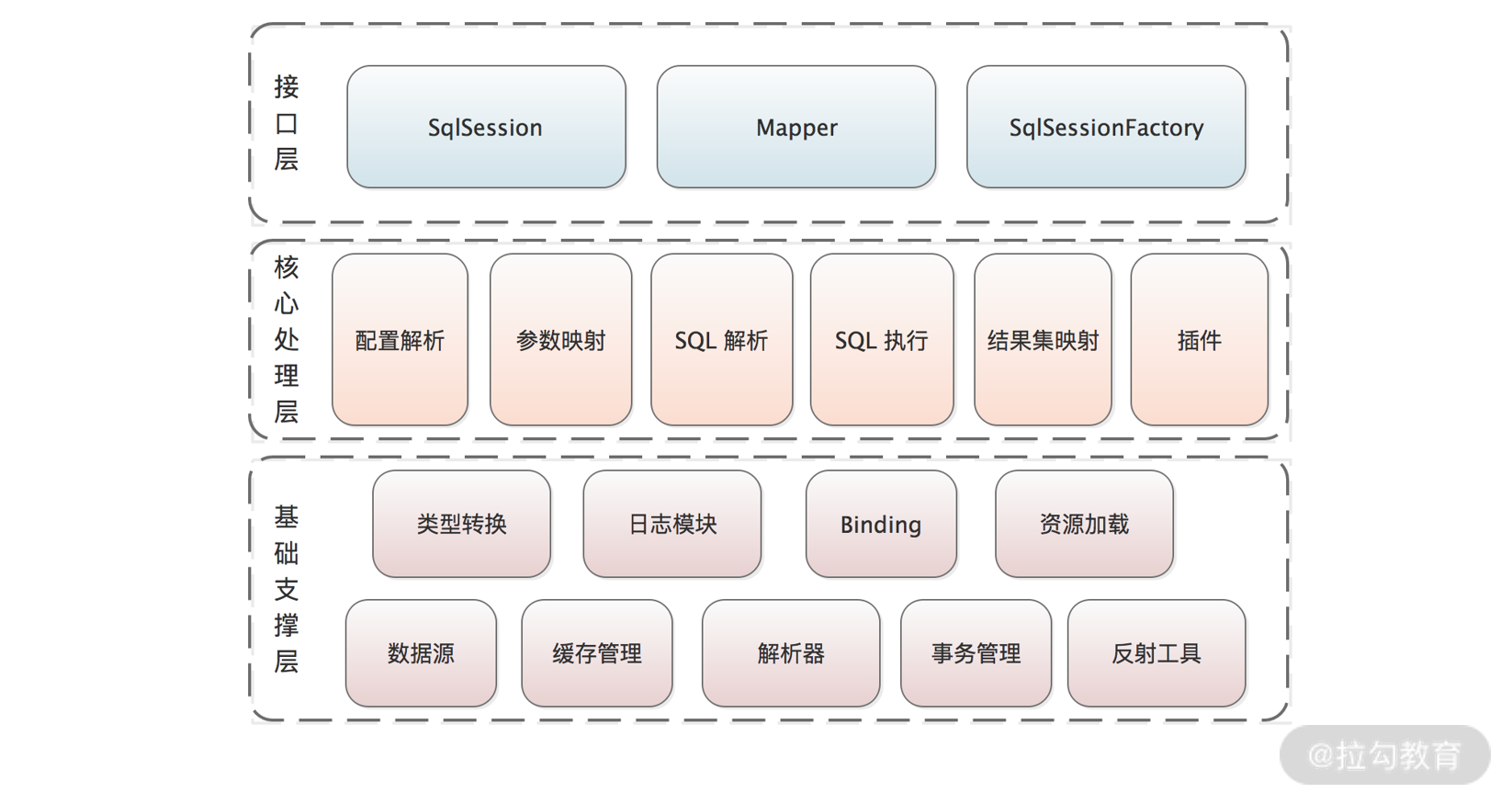
基础支撑层
基础支撑层是整个mybatis框架的基础,为整个mybatis框架提供了非常基础的功能,其中每个模块都提供了一个内聚的、单一的能力,mybatis基础支撑层按照这些单一的能力可以划分为上图所示的九个基础模块。
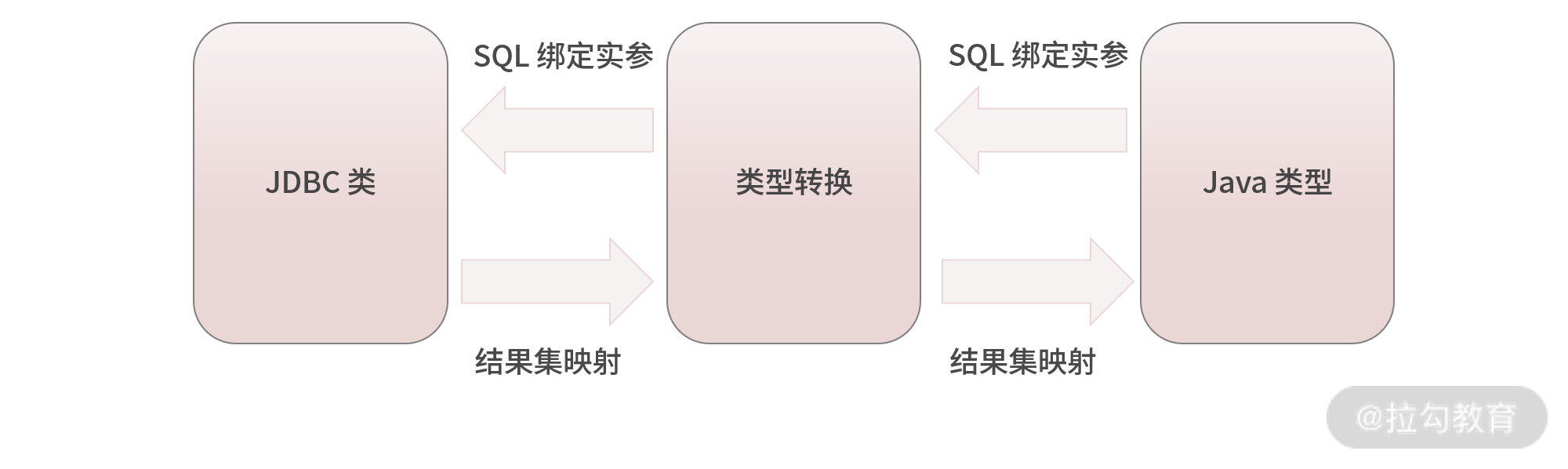
- 类型转换模块。在mybatis-config.xml配置文件中通过
标签为一个类定义一个别名,这里用到的“别名机制”就是由mybatis基础支撑中的类型转换模块实现的;除了别名机制,类型转换模块还实现了mybatis中JDBC类型和Java类型之间的相互转换,这一功能在绑定实参、映射ResultSet场景中都有所体现: - 在SQL模板绑定用户传入实参的场景中,类型转换模块会将Java类型转换成JDBC类型数据;
- 在将ResultSet映射程结过对象的时候,类型转换模块会将JDBC类型数据转换成Java类型数据。
- 具体如下图所示:
- 日志模块。日志是我们生产中排查问题、定位Bug、锁定性能瓶颈的主要线索来源。在任何一个成熟系统中都会有级别合理、信息翔实得日志模块,mybatis也不例外。mybatis提供了日志模块来集成Java生态中的第三方日志框架,该模块目前可以集成log4j、Log4j2、slf4j等优秀的日志框架。
- 反射工具模板。mybatis的反射工具箱是在Java反射的基础上进行封装,为上层使用方提供更加灵活、方便的API接口,同时缓存Java原生反射相关的元数据,提升反射代码执行的效率,优化反射操作性能。
- Binding模块。通过sqlsession获取mapper接口的代理,然后通过这个代理执行关联mapper.xml文件中的数据库操作。通过这种方式,可以将一些错误提前到编译期,以上功能就是通过Binding模块完成。其实binding模块可以让我们无须编写mapper接口的具体实现,利用其自动生成mapper接口的动态代理对象。简单的数据操作,可以直接在mapper接口中使用注解完成。
- 数据源模块。
- 缓存模块。MyBatis 就提供了一级缓存和二级缓存,具体实现位于基础支撑层的缓存模块中。
- 解析器模块。mybatis有两大部分配置文件需要解析,一是mybatis-config,xml配置文件,另一个是Mapper.xml配置文件。这两个文件都是由mybatis的解析器模块进行解析,其中主要是依赖XPath实现XML配置文件以及各类表达式的高效解析。
- 事务管理模块。
mybatis中的反射工具类—Reflector
Reflector是Mybatis反射模板的基础。要是用反射模块操作一个Class,都会先将Class封装成一个Reflector对象,在Reflector中缓存Class的元数据信息,可以提高反射效率。
mybatis核心初始化流程
对于mybatis反射操作,Reflector管理类的属性和方法,这些信息都记录在核心字段中,具体如下:
- type (final Class<?> 类型):该Reflector对象封装Class类型;
- readablePropertyNames、writablePropertyNames (final String [] 类型):可读、可写属性的名称集合;
- setMethods、getMethods (final Map
- setTypes、getTypes (final Map
- defaultConstructor(Constructor<?> 类型):默认构造方法;
- caseInsensitivePropertyMap (Map
在mybatis中构造一个Reflector对象,传入一个class对象,通过解析class对象,即可填充上述核心字段。整合核心流程如下描述:
- 用type字段记录传入的class对象;
- 通过反射拿到class类拿到全部构造方法,并进行遍历,过滤得到唯一无参构造方法来初始化defaultConstructor字段。这部分逻辑在addDefaultConstructor()方法中实现;
- 读取Class类中的getter方法,填充上面介绍的getMethods集合和getTypes集合,这部分逻辑在addGetMethods()方法中实现;
- 读取Class类中setter方法,填充上面介绍的setMethods集合和setTypes集合,这部分逻辑在addSetMethods()方法中实现;
- 读取Class中没有getter/setter方法的字段,生成对应的Invoker对象,填充getMethods集合、getTypes集合以及setMethods集合setTypes集合。这部分逻辑在addFields()方法中实现;
- 根据前面三步构造方法的getMethods/setMethods集合的keySet,初始化readablePropertyNames、writablePropertyNames集合;
遍历构造的readablePropertyNames、writablePropertyNames集合,将其中的属性名称全部转化成大写并记录到caseInsensitivePropertyMap集合中。
public Reflector(Class<?> clazz) {type = clazz; //1addDefaultConstructor(clazz); //2addGetMethods(clazz); //3addSetMethods(clazz); //4addFields(clazz); //5//6readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);writablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);//7for (String propName : readablePropertyNames) {caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);}for (String propName : writablePropertyNames) {caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);}}
对创建Reflector对象流程中的核心方法解读如下:
addGetMethods()和addSetMethods()方法(以addGetMethods()方法为例)
- 获取方法信息。
Invokerprivate void addGetMethods(Class<?> cls) {Map<String, List<Method>> conflictingGetters = new HashMap<>();//获取方法信息,通过调用getClassMethods()方法获取当前class类的所有方法的唯一签名,以及每个方法对 //应的Method对象,这里生成的方法是包含返回值的,可以作为该方法全局唯一标识Method[] methods = getClassMethods(cls);//for (Method method : methods) {if (method.getParameterTypes().length > 0) {continue;}String name = method.getName();if ((name.startsWith("get") && name.length() > 3)|| (name.startsWith("is") && name.length() > 2)) {name = PropertyNamer.methodToProperty(name);addMethodConflict(conflictingGetters, name, method);}}//解决签名冲突,理冲突的核心逻辑其实就是比较 getter 方法的返回值,优先选择返回值为子类的 getter //方法resolveGetterConflicts(conflictingGetters);}
在Reflector对象的初始化过程中,所有属性的getter\setter方法都会被封装成MethodInvoker对象,没有getter\setter的字段也会生成对应的get\setFieldInvoker对象。
在mybatis中对象反射invoker接口的继承关系如下: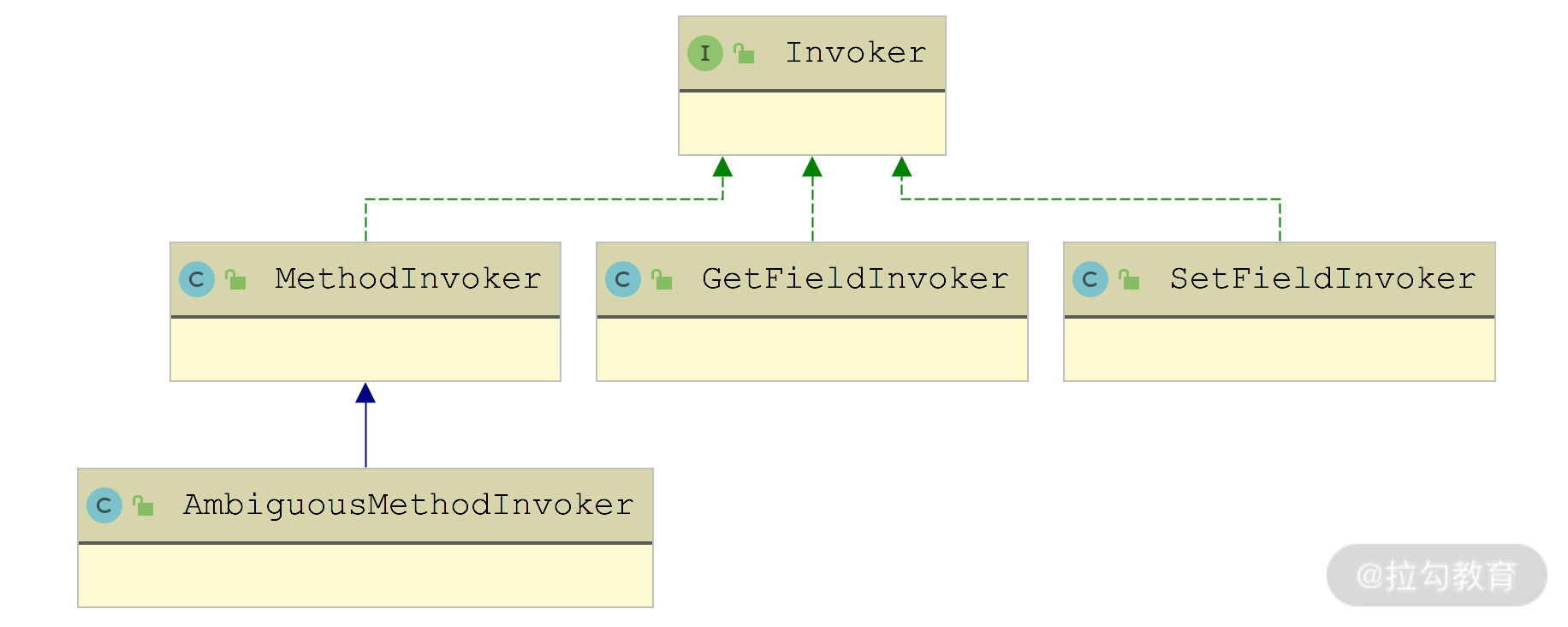
以上对Invoker接口的实现,methodInvoker方法是通过反射方式执行底层封装的method方法(setter\getter方法)完成属性读写效果。get/setFieldInvoker方法是通过反射方式读写底层封装的Field字段,进而实现字段的读写效果。
ReflectorFactory
为了提升Reflector的初始化速度,mybatis中提供了ReflectorFactory这个接口工厂类,是对Reflector对象进行缓存,其中最核心的方法是findForClass()方法。
DefaultReflectorFactory是对ReflectorFactory接口的默认实现。在该默认实现的类中有一个在内存中维护的ConcurrentMap
事务接口
Transaction接口是Mybatis中对数据库事务的抽象,其中定义了提交事务、回滚事务,以及获取事务底层数据库连接的方法。
Mapper文件与Java接口的优雅映射之道
在myabtis中mapper文件与java的接口文件映射功能在binding模块,其中涉及的核心如下: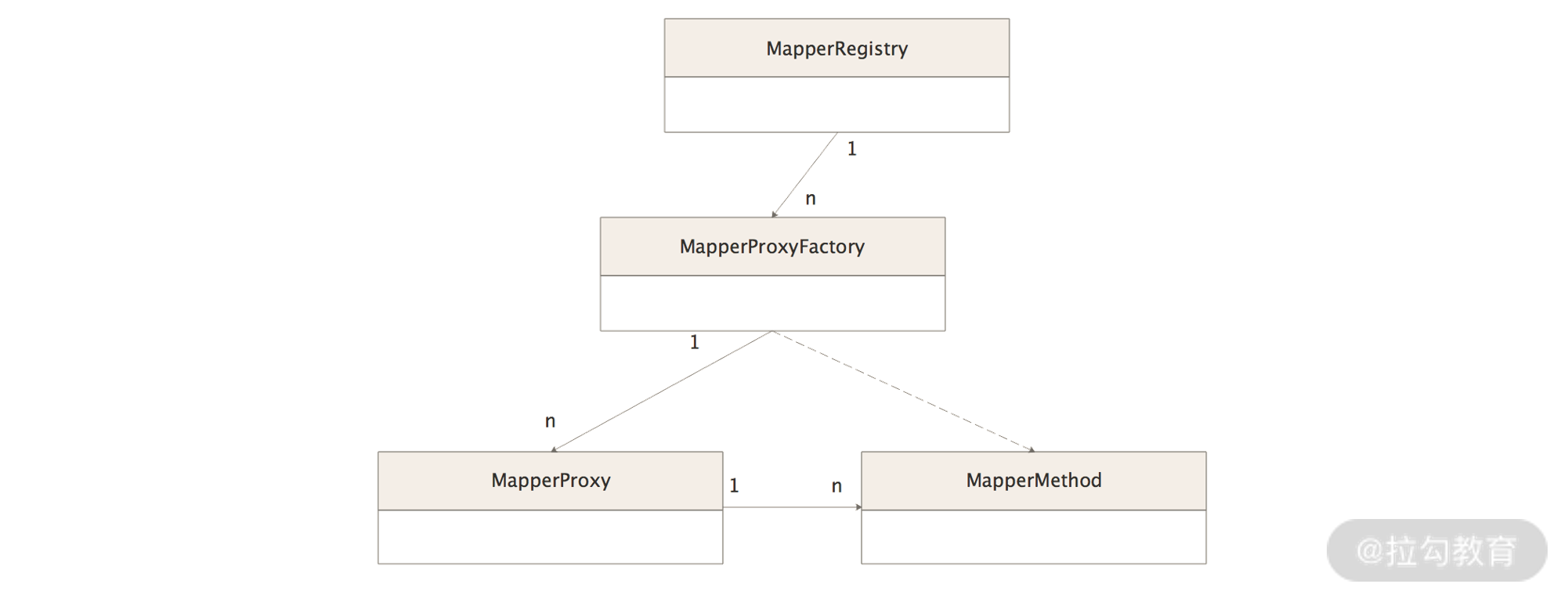
binding模块核心组件关系图MapperRegistry
MapperRegistry是Mybatis初始过程中构造的一个对象,主要作用是统一维护Mapper接口以及这些Mapper的代理对象工厂。
MapperRegistry中的核心字段:
- 获取方法信息。
- config(Configuration 类型):指向Mybatis全局唯一的Configuration对象其中维护了解析之后的全部Mybatis配置信息;
- knowMappers (Map
在Mybatis初始化时,会读取全部Mapper.xml配置文件,还会扫描全部Mapper接口中的注解信息,之后会调用MapperRegistry.addMapper()方法填充knowMappers集合。在addMapper()方法填充knowMappers集合之前,MapperRegistry会先保证传入type参数是一个接口且knowMappers集合没有加载过type类型,然后才会创建相应的MapperProxyFactory工厂并记录到knowMappers集合中。
MapperProxyFactory
MapperProxyFactory的核心功能是创建Mapper接口的代理对象,其底层核心原理就是JDK的动态代理。
在MapperRegistry中会依赖MapperProxyFactory的newInstance()方法创建代理对象,底层则是通过JDK动态代理的方式生成代理对象的,如下代码,这里使用的InvocationHandler实现是MapperProxy。
public T newInstance(SqlSession sqlSession) {final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);return newInstance(mapperProxy);}@SuppressWarnings("unchecked")protected T newInstance(MapperProxy<T> mapperProxy) {return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);}
MapperProxy
MapperProxy是生成Mapper接口代理对象的关键,它实现了InvocationHandler接口。
MapperProxy中的核心字段:
- sqlSession (SqlSession 类型):记录了当前MapperProxy关联的SqlSession对象。在与当前MapperProxy关联的代理对象中,会用该SqlSession访问数据;
- mapperInterface (Class
类型):Mapper接口类型,也是当前MapperProxy关联的代理对象实现的接口类型; - methodCache (Map
- lookupConstructor (Constructor 类型):针对JDK8中的特殊处理,该字段指向了MethodHandler.Lookup的构造方法;
- privateLookupInMethod (Method 类型):除了JDK8之外的其他JDK版本会使用该字段,该字段指向MethodHandlers.privateLookupIn()方法。
MapperProxy.invoke()方法是代理对象执行的入口,其中会拦截所有非Object方法,针对每个被拦截的方法,都会调用获取对应MapperMethod对象的方法。
MapperMethod
MapperMethod核心:MapperMethod是最终执行SQL语句的地方,同时也记录了Mapper接口中的对应方法。
- SqlCommand
MapperMethod的第一个核心字段是command(SqlCommand 类型),其中维护了关联SQL语句的相关信息。在MapperMethod$SqlCommand这个内部类中,通过name字段记录了关联SQL语句的唯一标识,通过type字段(SqlCommandType类型)维护了SQL语句的操作类型,这里SQL语句的操作类型分为INSERT、UPDATE、DELETE、SELECT和FLUSH五种。
//SqlCommand查找Mapper接口中一个方法对应的SQL语句的信息public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {//获取Mapper接口中对应的方法名称final String methodName = method.getName();//获取Mapper接口的类型final Class<?> declaringClass = method.getDeclaringClass();//将Mapper接口名称和方法名称拼接起来作为SQL语句唯一标识,到Configuration这个全局配置对象中查找SQL//语句,MappedStatement对象就是Mapper.xml配置文件中一条SQL语句解析之后得到的对象MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,configuration);if (ms == null) {//针对@Flush注解的处理if (method.getAnnotation(Flush.class) != null) {name = null;type = SqlCommandType.FLUSH;} else {//没有@Flush注解,会抛出异常throw new BindingException("Invalid bound statement (not found): "+ mapperInterface.getName() + "." + methodName);}} else {//记录SQL语句唯一标识name = ms.getId();//记录SQL语句的操作类型type = ms.getSqlCommandType();if (type == SqlCommandType.UNKNOWN) {throw new BindingException("Unknown execution method for: " + name);}}}
在上面中调用了resolveMappedStatement()方法不仅会尝试根据SQL语句的唯一标识从Configuration全局配置对象中查找关联的MappedStatement对象,还会尝试顺着Mapper接口的继承树进行查找,直至查找成功为止,具体如下:
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,Class<?> declaringClass, Configuration configuration) {//将Mapper接口名称和方法名称拼接起来作为SQL语句唯一标识String statementId = mapperInterface.getName() + "." + methodName;//检测Configuration中是否包含相应的MappedStatement对象if (configuration.hasStatement(statementId)) {return configuration.getMappedStatement(statementId);} else if (mapperInterface.equals(declaringClass)) {//如果方法就定义在当前接口中,则证明没有对应的SQL语句,返回nullreturn null;}//如果当前检查的Mapper接口(mapperInterface)中不是定义该方法的接口(declaringClass),//则会从mapperInterface开始,沿着继承关系向上查找递归每个接口,查找该方法对应的,MappedStatement对象for (Class<?> superInterface : mapperInterface.getInterfaces()) {if (declaringClass.isAssignableFrom(superInterface)) {MappedStatement ms = resolveMappedStatement(superInterface, methodName,declaringClass, configuration);if (ms != null) {return ms;}}}return null;}
MethodSignature
MapperMethod的第二个核心字段是method字段(MethodSignature 类型),其中维护了Mapper接口中方法的信息,首先是Mapper接口方法返回值相关信息:
- returnsMany、returnsMap、returnsVoid、returnsCursor、returnsOptional(boolean 类型):用于表示方法返回值是否为Collection集合或数组、Map集合、void、cursor、optional类型;
- returnType (Class<?> 类型):方法返回值的具体类型
- mapKey (String 类型):如果方法的返回值为Map集合,则通过mapKey字段记录了作为key的列名。mapKey字段的值是通过解析方法上的@MapKey注解得到的;
- resultHandlerIndex (Integer 类型):记录了Mapper接口方法的参数列表中ResultHandler类型参数的位置;
- rowBoundsIndex (Integer 类型):记录了Mapper接口方法的参数列表中RowBounds类型参数的位置;
- paramNameResolver (ParamNameResolver 类型):用来解析方法参数列表的工具类。
在上面的字段中,paramNameResolver字段含义:
在ParamNameResolver中有一个names字段(SortedMap
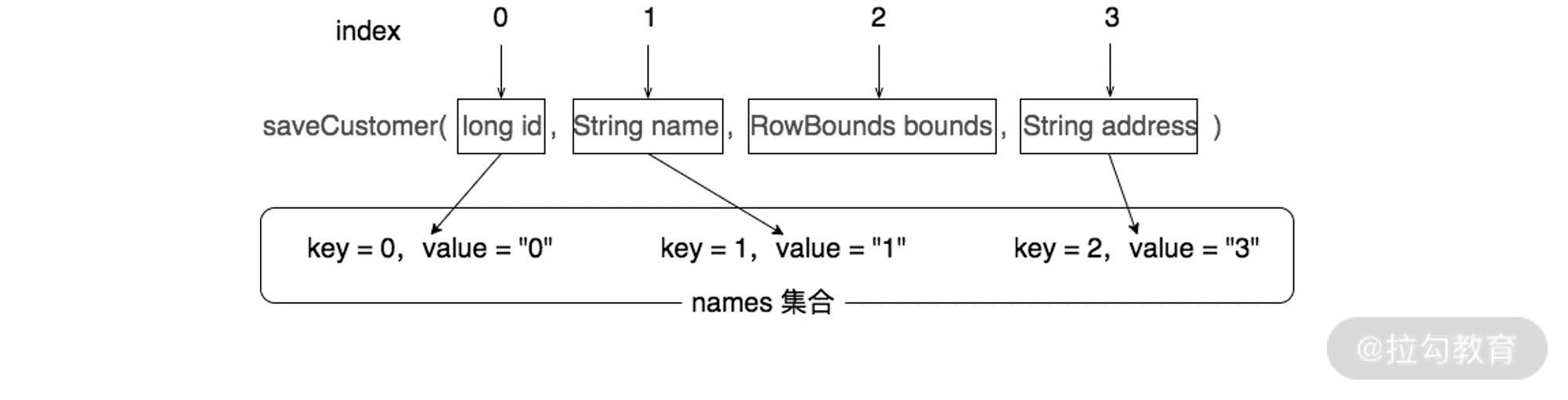
names集合中KV不一致示意图
以上是names集合初始化,以下是从names集合中查询参数名称,该部分逻辑如下:
/*** <p>* A single non-special parameter is returned without a name.* Multiple parameters are named using the naming rule.* In addition to the default names, this method also adds the generic names (param1, param2,* ...).* </p>*/public Object getNamedParams(Object[] args) {//获取方法中非特殊类型(RowBounds类型和ResultHandler类型)的参数个数final int paramCount = names.size();if (args == null || paramCount == 0) {//若方法没有非特殊类型参数,返回nullreturn null;} else if (!hasParamAnnotation && paramCount == 1) {//方法参数列表中没有使用@Param注解,且只有一个非特殊类型参数return args[names.firstKey()];} else {//处理存在@Param注解或是存在多个非特殊类型参数的长江//param集合用于记录了参数名称与实参之间的映射关系,这里的ParamMap继承了HashMap,与HashMap唯一//的不同:向ParamMap中添加已经存在的key时,会直接抛出异常,而不是覆盖原有的Keyfinal Map<String, Object> param = new ParamMap<>();int i = 0;for (Map.Entry<Integer, String> entry : names.entrySet()) {//将参数名称与实参的映射保存到param集合中param.put(entry.getValue(), args[entry.getKey()]);// add generic param names (param1, param2, ...)//同时,为参数创建"param+索引"格式的默认参数名称,具体格式为:param1,param2等,将"param+索引"//的默认参数名称与实参的映射关系也保存到param集合中final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);// ensure not to overwrite parameter named with @Paramif (!names.containsValue(genericParamName)) {param.put(genericParamName, args[entry.getKey()]);}i++;}return param;}}
对于MethodSignature构造方法:
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {//根据TypeParameterResolver工具类解析方法的返回值类型。初始化returnType字段值。Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);if (resolvedReturnType instanceof Class<?>) {this.returnType = (Class<?>) resolvedReturnType;} else if (resolvedReturnType instanceof ParameterizedType) {this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();} else {this.returnType = method.getReturnType();}this.returnsVoid = void.class.equals(this.returnType);this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray();this.returnsCursor = Cursor.class.equals(this.returnType);this.returnsOptional = Optional.class.equals(this.returnType);//如果返回值为Map类型,则从方法的@MapKey注解中获取Map中为key的字段名称this.mapKey = getMapKey(method);this.returnsMap = this.mapKey != null;//解析方法中RowBounds类型参数和ResultHandler类型参数类型的下标索引位置,初始化rowBoundsIndex和//resultHandlerIndex字段this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);//创建ParamNameResolver工具对象,在创建ParamNameResolver对象的时候会解析方法的参数列表信息this.paramNameResolver = new ParamNameResolver(configuration, method);}
- execute()方法
execute()方法是MapperMethod中最核心的方法之一。execute()方法会根据要执行的SQL语句的具体类型执行SqlSession的相应方法完成数据库操作,其核心实现如下:
public Object execute(SqlSession sqlSession, Object[] args) {Object result;switch (command.getType()) {case INSERT: {Object param = method.convertArgsToSqlCommandParam(args);result = rowCountResult(sqlSession.insert(command.getName(), param));break;}case UPDATE: {Object param = method.convertArgsToSqlCommandParam(args);result = rowCountResult(sqlSession.update(command.getName(), param));break;}case DELETE: {Object param = method.convertArgsToSqlCommandParam(args);result = rowCountResult(sqlSession.delete(command.getName(), param));break;}case SELECT:if (method.returnsVoid() && method.hasResultHandler()) {executeWithResultHandler(sqlSession, args);result = null;} else if (method.returnsMany()) {result = executeForMany(sqlSession, args);} else if (method.returnsMap()) {result = executeForMap(sqlSession, args);} else if (method.returnsCursor()) {result = executeForCursor(sqlSession, args);} else {Object param = method.convertArgsToSqlCommandParam(args);result = sqlSession.selectOne(command.getName(), param);if (method.returnsOptional()&& (result == null || !method.getReturnType().equals(result.getClass()))) {result = Optional.ofNullable(result);}}break;case FLUSH:result = sqlSession.flushStatements();break;default:throw new BindingException("Unknown execution method for: " + command.getName());}if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {throw new BindingException("Mapper method '" + command.getName()+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");}return result;}
Cache接口及核心实现
Cache接口是Mybatis缓存中最顶层的抽象接口,定义了Mybatis缓存最核心、最基础的行为。Cache接口中最核心的方法主要是:putObject()、getObject()和removeObject()三个方法,分别用来写入、查询和删除缓存数据。
Cache接口的实现类如下图所示,其中PerpetualCache担任装饰器模式中的ComponentImpl角色,实现了Cache接口缓存数据的基本能力。
PerpetualCache中有两个核心字段:一个id(String 类型),记录了缓存对象的唯一标识;另外一个是cache(HashMap 类型),真正实现Cache存储的数据结构,对Cache接口的实现也会直接委托给这个HashMap对象的相关方法。
Cache接口装饰器
除了PerpetualCache之外的其他所有Cache接口实现类,都是装饰器实现,也就是DecoratorImpl的角色。
- BlockingCache
BlockingCache是在原有Cache实现之上添加了阻塞线程的特性。对于Key来说,同一时刻,BlockingCache只会让一个业务线程到数据库中去查找,查找到结果后,会添加到BlockingCache中缓存。
作为一个装饰器,BlockingCache还包含一个Cache类型的字段,也就是delegate字段。BlockingCache还包含了一个locks(ConcurrentHashMap
- FifoCache
Mybatis缓存实际上是JVM堆中的一块内存,需要严格控制Cache的大小,防止Cache占用内存过大影响程序的性能。操作系统有很多缓存淘汰规则,Mybatis也提供了类似的规则来清理缓存。
这就引出了FifoCache装饰器,自然也会包含一个指向Cache的字段(也就是delegate字段),同时还维护了两个与FIFO相关字段:一个keyList队列(LinkedList),主要利用了LinkedList集合有序性,记录缓存条目写入Cache的先后顺序;另一个是当前Cache的大小上限字段(size字段),当Cache大小超过该值时,就会从keyList集合中查找最早的缓存条目并进行清理。
FifoCache的getObject()方法和removeObject()方法实现非常简单,都是直接委托给底层delegate这个被装饰的Cache对象的同名方法。FifoCache的关键字实现在putObject()方法中,在将数据写入被装饰的Cache对象之前,FifoCache会通过cycleKeyList()方法执行FIFO策略清理缓存,然后才会调用delegate.putObject()方法完成数据写入。
- LruCache
Mybatis还支持LRU(Least Recently Used,近期最少使用算法)策略来清理缓存。LruCache就是使用LRU策略清理缓存的装饰器实现,如果LruCache发现缓存需要清理,它会清除最近最少使用的缓存条目。
LruCache中除了有一个delegate字段指向被装饰Cache对象之外,还维护了一个LinkedHashMap集合(keyMap 字段),用来记录各个缓存条目最近的使用情况,以及一个eldestKey字段(Object 类型),用来指向最近最少使用的Key。
LinkedHashMap继承了HashMap,底层使用数组存储KV数据,数组中存储的是LinkedHashMap.Entry类型的元素。在LinkedHashMap.Entry中除了存储KV数据之外,还维护了before、after两个字段分别指向当前Entry前后两个Entry节点。在LinkedHashMap中还维护了head、tail两个指针,分别指向了第一个和最后一个Entry节点。LinkedHashMap的原理如下图: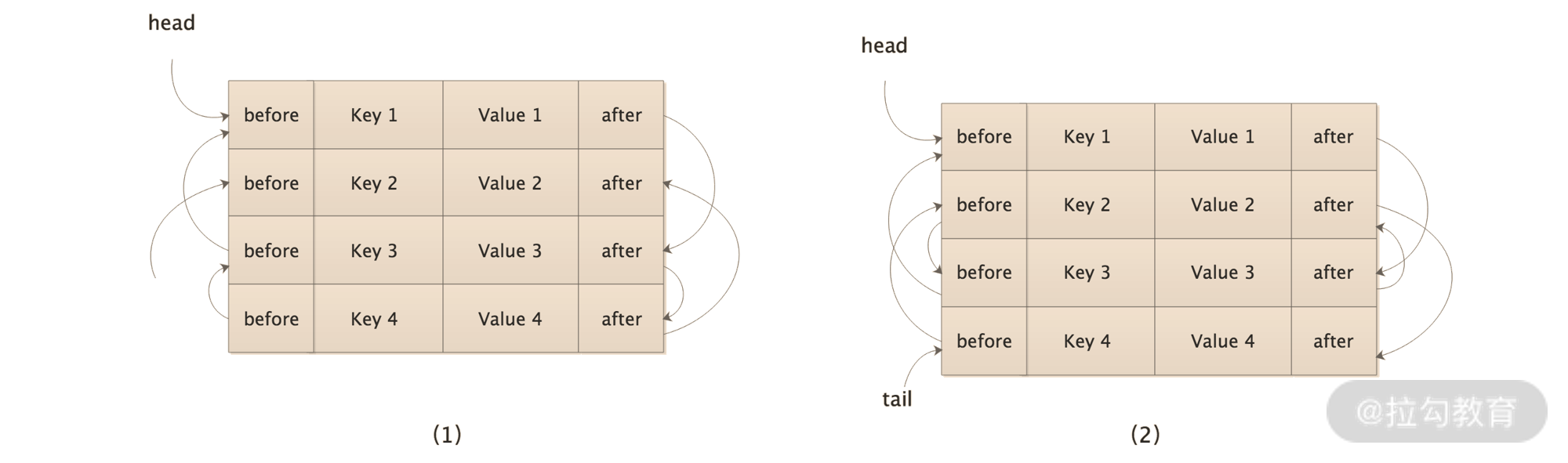
LinkedHashMap 原理图
在上图(1)中,通过Entry中的before和after指针形成了一个链表,当我们调用get()方法访问key4时,LinkedHashMap除了返回Value4之外还会默默修改Entry链表,将key4移动到链表的尾部,得到上图(2)中的结构。
LruCache中的keyMap覆盖了LinkedHashMap默认的removeEldestEntry()方法实现,当LruCache中缓存条目达到上限的时候,返回true,即删除Entry链表中head指向的Entry。LruCache就是依赖LinkedHashMap上述的这些特点来确定最久未使用的的缓存条目并完成删除的。
LruCache初始化过程中,keyMap对LinkedHashMap.removeEldestEntry()方法的覆盖:
public void setSize(final int size) {keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {private static final long serialVersionUID = 4267176411845948333L;//调用LinkedHashMap.put()方法,会调用removeEldestEntry()方法,决定是否删除head指向的Entry数据@Overrideprotected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {boolean tooBig = size() > size;if (tooBig) { //已达到缓存上限,更新eldestKey,并返回true,LinkedHashMap会删除该keyeldestKey = eldest.getKey();}return tooBig;}};}
- SoftCache
核心处理层
核心处理层是Mybatis的核心,主要是mybatis的初始化以及执行一条SQL语句的全流程。
- 配置解析。mybatis有三处可以添加配置信息的地方,分别是:mybatis-config.xml配置文件、mapper.xml配置文件以及mapper接口中的注解信息。在mybatis初始化过程中会加载这些配置信息,并将解析之后得到的配置对象保存到Configuration对象中。
- SQL解析与scripting模块。mybatis提供了动态SQL功能,通过其提供的标签,根据实际运行条件动态生成执行SQL语句。mybatis提供的动态标签有:
等。mybatis中的scripting模块就是负责动态生成SQL的核心模块。他会根据运行时用户传入的实参,解析动态sql中的标签,并形成SQL模板,然后处理SQL模板中的占位符,用运行时的实参填充占位符,得到数据库真正可执行的SQL语句。 - SQL执行。在mybatis中执行一条SQL语句,涉及到的核心组件有:Executor、StatementHandler、ParameterHandler和ResultSetHandler。其中Executor会调用事务管理模块实现事务的相关控制,同时会通过缓存模块管理一级缓存和二级缓存。SQL语句真正执行将会由StatementHandler实现。StatementHandler会先依赖ParameterHandler进行SQL模板的实参绑定,然后由java.sql.Statement对象将SQL语句以及绑定好的实参传到数据库执行,从数据库中拿到ResultSet,最后,由ResultSetHandler将ResultSet映射成Java对象返回给调用方,这是SQL执行模板的核心。以下是SQL语句的核a心过程:
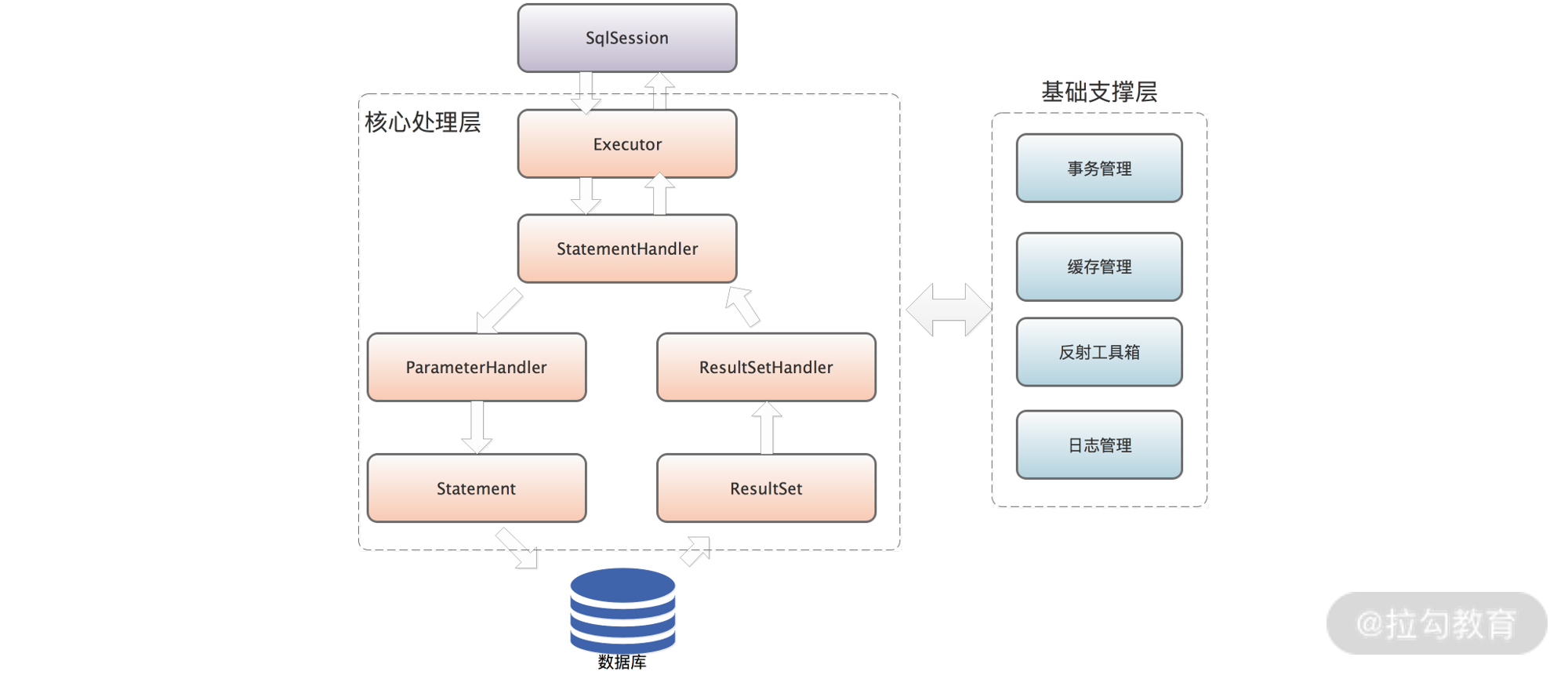
- 插件。
接口层
接口层是mybatis暴露给调用的接口集合,这些接口都是使用mybatis时常用的接口,例如:sqlSession接口、sqlSessionFactory接口等。其中最核心的是sqlSession接口(该接口可以获取mapper代理、执行SQL语句、控制事务开关等)。
JDBC
JDBC(Java DataBase Connectivity)是Java程序与关系型数据库交互的统一API。实际上,JDBC由两部分API构成:第一部分是面向开发者的Java API,它是一个统一的、标准的Java API,独立于各个数据库产品的接口规范;第二部分是面向对象数据库驱动程序开发者的API,它是由各个数据厂家提供的数据库驱动,是第一部分规范的底层实现,用于连接具体的数据库产品。
JDBC操作的核心步骤
- 注册数据库驱动类,指定数据库链接地址,其中包括DB的用户名、密码及其他连接信息;
- 调用DriverManager.getConnection()方法创建Connection连接到数据库;
- 调用Connection的createStatement()或prepareStatement()方法,创建Statement对象,此时会指定SQL(或是SQL语句模板+SQL参数);
- 通过Statement对象执行SQL语句,得到ResultSet对象,也就是查询结果集;
- 遍历ResultSet,从结果集中读取数据,并将每一行数据库记录转换成一个JavaBean对象;
- 关闭ResultSet结果集、Statement对象及数据库Connection,从而释放这些对象占用的底层资源。
- mybatis mapper内的方法能重载么
不能,因mybatis使用 package+mapper+method 作为key,去xml文件中匹配sql,若重载方法时会产生矛盾。

若有收获,就点个赞吧
0 人点赞
