一. 创建爬虫步骤
创建一个项目
scrapy startproject xxx
进入项目目录
cd xxx
在spiders子目录下创建一个爬虫文件
scrapy genspider spiderName www.xxx.com
执行工程
scrapy crawl spiderName
若:(1)只想打印结果(爬虫如果有错误看不到错误信息,只会返回空)
scrapy crawl spiderName --nolog
(2)打印结果(但只有爬虫出现错误时才打印日志信息)——建议使用
在settings.py中加入# 任选一种LOG_LEVEL = "ERROR"LOG_LEVEL = "INFOLOG_LEVEL = 'WARNING'"
二. scrapy持久化存储
1. 基于终端指令
要求:只能将parse方法的返回值存储到本地的文本文件中
scrapy crawl menu_content -o ./menu_content.csv
2. 基于管道(推荐)
编码流程
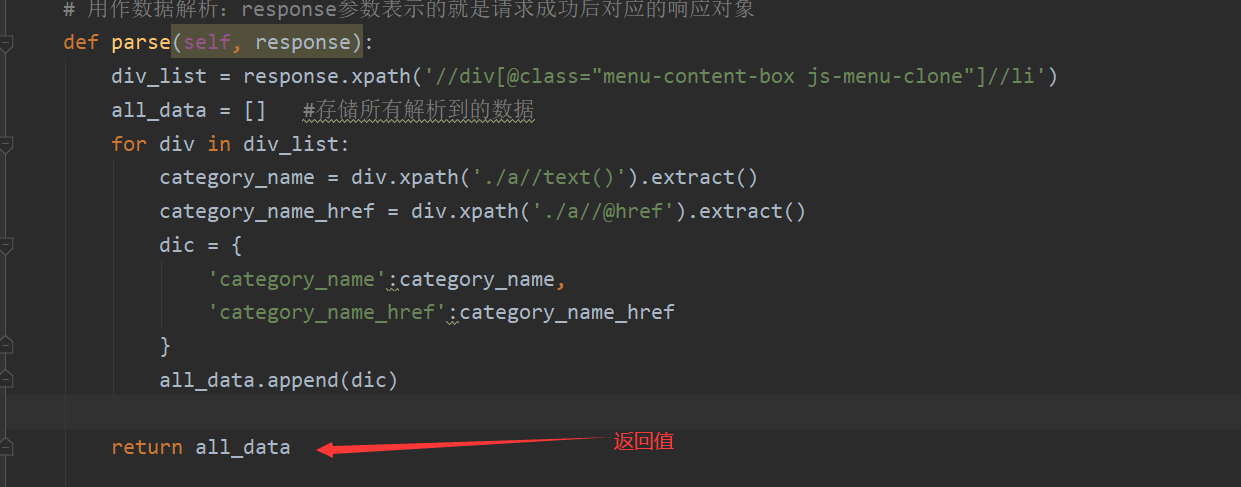
数据解析(使用xpath获取想要的)
- 在item类中定义相关的属性
- 将解析的数据封装存储到item类型的对象
- 将item类型的对象提交给管道进行持久化存储的操作
- 在管道类的process_item中要将其接受到的item对象中存储到的数据进行持久化存储操作
- 在配置文件中开启管道
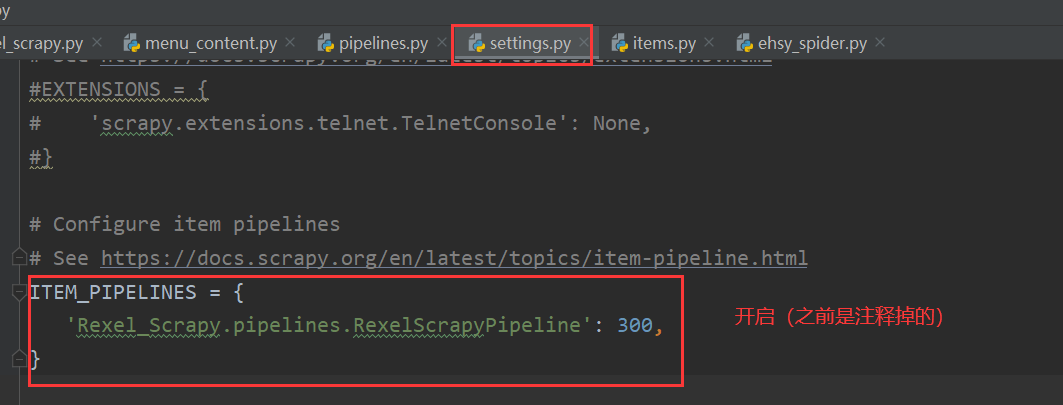
字典中存放管道类(300表示优先级,数值优小先级越高)
一道面试题:将爬取到的数据一分存储到本地一分存储到数据库中,请问如何实现?答:1. 在管道类中定义两个类,一个管道类对应将一组数据存储到一个平台或者载体中2. 在settings.py的管道中设置两个管道类的优先级3. 爬虫提交的item只会给管道文件中第一个被执行的管道类4. process_item 中return item表示将item传递给下一个即将执行的管道类疑问:1. 爬虫文件提交的item类型的对象最终会提交给哪一个管道类?——哪个管道类优先级高,哪个管道类接收item类型2. 那么按照上述所说,item类型的对象只能提交给一个管道类,那么如果定义多个管道类,其他的管道类如何拿到item对象?——每个管道类都会 return item ,通过return就会将item传递给下一个即将执行的管道类(根据优先级)
三. 遇到的问题
1. 获取div中内容时返回内容为空
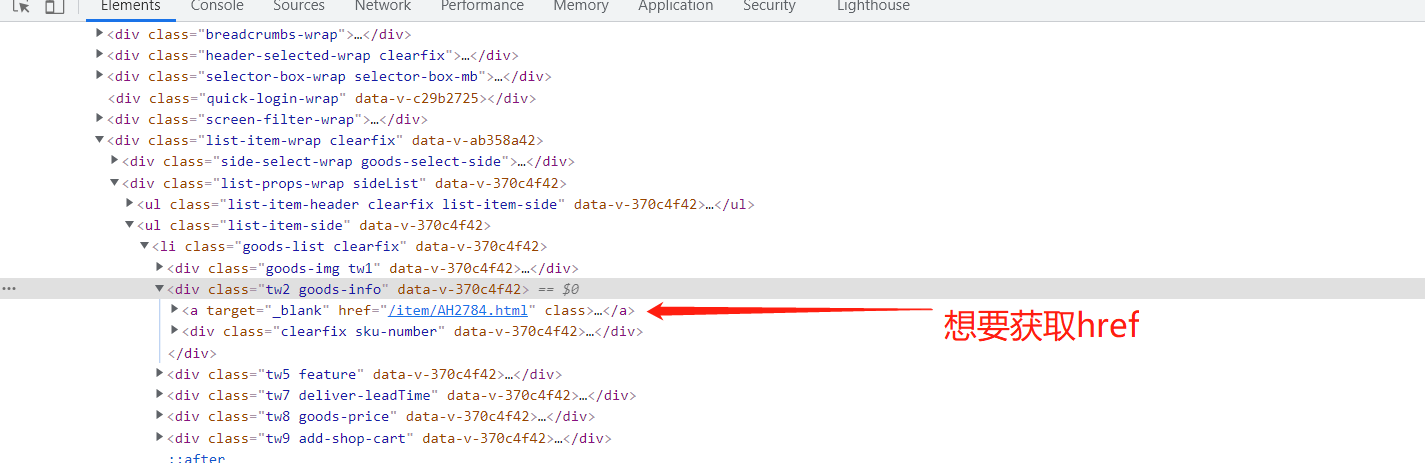
首先检查检查过该页面不是动态加载的(禁用谷歌浏览器中js仍然可以看到内容、使用response.text发现返回来的网页源代码也有该内容,就是获取不到)
xpath写法:(从xpath helper上检查过可以获取到内容,而且平时也是这种写法,能获取)
//*[@id="app"]/div/div/div[5]/div[6]/div[2]/ul[2]/li[1]/div[2]/a/@href
最后从网上查询,换了种写法:
//div[@class='tw2 goods-info']/a/@href
最后总结一下这个问题可能的原因:
1:xpath 的语法问题:在 chrome中能获取数据不代表在 shell 中也一定能够获取数据,所以遇到这个问题可以尝试改写语法
2:XML根元素处声明的默认命名空间问题,具体可见上面的 stackoverflow 链接
2. 解析离线HTML网页,获取script标签中内容
为了爬取网页中的json数据,将html网页保存到本地,想获取script标签中window.INITIAL_DATA的数据
试过js2xml语法,和正则表达式,没处理好,然后就使用读入每一行,替换字段的方法
<script>
window.__INITIAL_DATA__ = {
"routing": {"location": null}, "@@dva": 0, "common": {
"injectConst": {
"NODE_ENV": "production",
"webUrl": {"host": "www.zkh360.com", "port": 443, "protocol": "https:"},
# 省略...
}, "propsServer": undefined
};</script>
原window.INITIAL_DATA中的数据全在一行,上面是格式化的代码
with open('AA9433.html', "rb") as f:
html_data = f.readlines()
for line in html_data:
if 'window.__INITIAL_DATA__' in line.decode():
sa = line.decode().replace("window.__INITIAL_DATA__ =", "").replace("undefined", "\"\"").replace(
";</script><script>", "")
json_data = json.loads(sa)
print(json_data)
- decode()方法作用:使用readlines()读取每一行数据为字节流,该方法将字节流转为字符串进行处理,默认编码为字符串编码。
- 处理后的sa为json格式,使用son.loads(sa)将字符串转为json格式,然后就可以拿到json中的数据了
可以使用notepad++中的插件查看json结构(没有的话可以从插件管理中下载)
四 scrapy配置(settings.py)
# 日志打印级别
# LOG_LEVEL = "ERROR"
# LOG_LEVEL = 'INFO'
LOG_LEVEL = 'WARNING'
# Obey robots.txt rules(默认是true,改为false)
ROBOTSTXT_OBEY = False
# Disable cookies (禁用cookies,可以防止反爬机制)
COOKIES_ENABLED = False
# 下载延迟
DOWNLOAD_DELAY = 3
# 并发
#CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS = 2
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 2
CONCURRENT_REQUESTS_PER_IP = 2
五 暂停和恢复爬虫
启动爬虫
scrapy crawl spider -s JOBDIR=record/spider-1
- record/spider-1是工作路径
暂停
直接Ctrl + c
恢复
scrapy crawl spider -s JOBDIR=record/spider-1
六. 总结
1. xpath写法(管道符)
li_list = response.xpath('//ul[@class="list-item-side"]/li | //ul[@class="list-item-side"]/a')
意思是如果前面的xpath生效使用前面的,后面的生效使用后面的(或者的关系)
2. 列表转字符串
str = ''.join(list)
3. 加快selenium加载速度
禁止网页图片加载
option = webdriver.ChromeOptions()
# 禁止弹窗 图片
prefs = {
'profile.default_content_setting_values':
{
'images': 2,
'notifications': 2
}
}
option.add_experimental_option('prefs', prefs)
4. selenium遍历元素,获取值
good_list = bro.find_elements_by_xpath('//div[@class="tw2 goods-info"]/a')
for link in tqdm(good_list):
url = link.get_attribute('href')
5. scrapy的settings.py设置
# 日志打印级别
# LOG_LEVEL = "ERROR"
# LOG_LEVEL = 'INFO'
LOG_LEVEL = 'WARNING'
# Obey robots.txt rules(默认是true,改为false)
ROBOTSTXT_OBEY = False
# Disable cookies (禁用cookies,可以防止反爬机制)
COOKIES_ENABLED = False
6. scrapy使用中间件设置随机请求头
步骤
(1)在middlewares.py中
class UserAgentDownloadMiddleware(object):
"""
随机请求头中间件
"""
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36',
]
def process_request(self, request, spider):
# random.choice()在列表中随机选择一个
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
(2)在settings.py中开启中间件
DOWNLOADER_MIDDLEWARES = {
# 'Img_Scrapy.middlewares.ImgScrapyDownloaderMiddleware': 543,
'Img_Scrapy.middlewares.UserAgentDownloadMiddleware': 543,
}

若有收获,就点个赞吧
0 人点赞
