读
Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:print(f.read())
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
for line in f.readlines():print(line.strip()) # 把末尾的'\n'删掉
写
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:f.write('Hello, world!')
总结
使用with语句操作文件IO是个好习惯。
读写csv文件
参考:https://python3-cookbook.readthedocs.io/zh_CN/latest/c06/p01_read_write_csv_data.html
问题
读写一个CSV格式的文件
csv文件:
Symbol,Price,Date,Time,Change,Volume"AA",39.48,"6/11/2007","9:36am",-0.18,181800"AIG",71.38,"6/11/2007","9:36am",-0.15,195500"AXP",62.58,"6/11/2007","9:36am",-0.46,935000"BA",98.31,"6/11/2007","9:36am",+0.12,104800"C",53.08,"6/11/2007","9:36am",-0.25,360900"CAT",78.29,"6/11/2007","9:36am",-0.23,225400
解决方案
方法一
使用Python标准库csv读取:
import csvdef read_csv():with open('test.csv') as f:f_csv = csv.reader(f)# 从第二行开始headers = next(f_csv)for rows in f_csv:print(rows)
运行结果: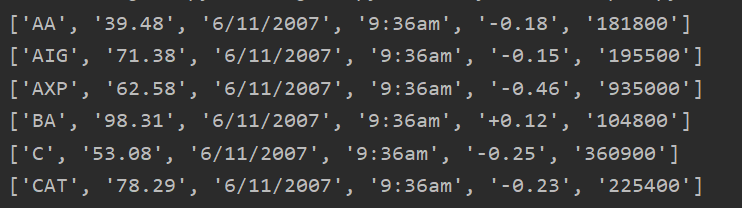
在上面的代码中, row 会是一个列表。因此,为了访问某个字段,你需要使用下标,如 row[0] 访问Symbol, row[4] 访问Change。
方法二
由于这种下标访问通常会引起混淆,可以考虑使用命名元组
from collections import namedtupledef read2_csv():with open('test.csv') as f:f_csv = csv.reader(f)# 从第二行开始headings = next(f_csv)Row = namedtuple('Row', headings)for r in f_csv:row = Row(*r)print(row)
结果:
它允许你使用列名如 row.Symbol 和 row.Change 代替下标访问。 需要注意的是这个只有在列名是合法的Python标识符的时候才生效。如果不是的话, 你可能需要修改下原始的列名(如将非标识符字符替换成下划线之类的)。
方法三
将数据读取到一个字典序列中去
import csvdef read3_csv():with open('test.csv') as f:f_csv = csv.DictReader(f)for row in f_csv:print(row)
结果:
用列名去访问每一行的数据了。比如,row[‘Symbol’] 或者 row[‘Change’]
写入CSV数据
你仍然可以使用csv模块,不过这时候先创建一个 writer 对象,例如:
headers = ['Symbol','Price','Date','Time','Change','Volume']rows = [('AA', 39.48, '6/11/2007', '9:36am', -0.18, 181800),('AIG', 71.38, '6/11/2007', '9:36am', -0.15, 195500),('AXP', 62.58, '6/11/2007', '9:36am', -0.46, 935000),]# newline=''设置换行符with open('stocks.csv','w',newline='') as f:f_csv = csv.writer(f)f_csv.writerow(headers)f_csv.writerows(rows)
结果: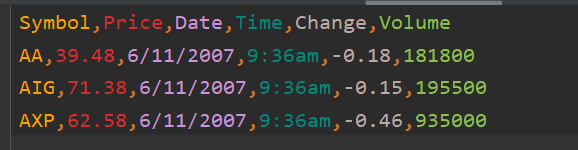
如果有一个字典序列的数据,可以像这样做:
import csvheaders = ['Symbol', 'Price', 'Date', 'Time', 'Change', 'Volume']rows = [{'Symbol':'AA', 'Price':39.48, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.18, 'Volume':181800},{'Symbol':'AIG', 'Price': 71.38, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.15, 'Volume': 195500},{'Symbol':'AXP', 'Price': 62.58, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.46, 'Volume': 935000},]with open('stocks.csv','w',newline='') as f:f_csv = csv.DictWriter(f, headers)f_csv.writeheader()f_csv.writerows(rows)
总结
应该总是优先选择csv模块分割或解析CSV数据,自己之前读csv文件曾这样处理:
with open('stocks.csv') as f:for line in f:row = line.split(',')# process row
使用这种方式的一个缺点就是你仍然需要去处理一些棘手的细节问题。 比如,如果某些字段值被引号包围,你不得不去除这些引号。 另外,如果一个被引号包围的字段碰巧含有一个逗号,那么程序就会因为产生一个错误大小的行而出错。

若有收获,就点个赞吧
0 人点赞
